Scientists are known for making dramatic predictions about the future – and sinister robots are once again in the spotlight now that artificial intelligence has become a marketing tool for all sorts of different brands.
The future of AI will require facing rapid change, vagueness, and difficulty. We need to be prepared for different adaptations of the future. There is no way to know what path the development of AI will take.
Modular construction isn’t new, but robots are making it more efficient than ever while addressing a labor shortage. Bringing robotics into the equation allows more parts of the building process to happen in customized facilities.
In a basement of New York University in 2013, Dr. Sergei Lupashin wowed the room of one hundred leading technology enthusiasts with one of the first indoor Unmanned Aerial Vehicle (UAV) demonstrations. During his presentation, Dr. Lupashin of ETH Zurich attached a dog leash to an aerial drone while declaring to the audience, “there has to be another way” of flying robots safely around people. Lupashin’s creativity eventually led to the invention of Fotokite and one of the most successful Indiegogo campaigns.
Since Lupashin’s demo, there are now close to a hundred providers of drones on leashes from innovative startups to aftermarket solutions in order to restrain unmanned flying vehicles. Probably the best known enterprise solution is CyPhy Works which has raised more than $30 million. Last August, during President Trump’s visit to his Golf Course in New Jersey, the Department of Homeland Security (DHS) deployed CyPhy’s tethered drones to patrol the permitter. In a statement by DHS about their “spy in the sky program,” the agency explained: “The Proof of Concept will help determine the potential future use of tethered Unmanned Aircraft System (sUAS) in supporting the Agency’s protective mission. The tethered sUAS used in the Proof of Concept is operated using a microfilament tether that provides power to the aircraft and the secure video from the aircraft to the Operator Control Unit (OCU).” CyPhy’s systems are currently being utilized to provide a birdseye view to police departments and military units for a number of high profile missions, including the Boston Marathon.
Fotokite, CyPhy and others have proved that tethered machines offer huge advantages from traditional remote controlled or autonomous UAVs, by removing regulatory, battery and payload restrictions from lengthy missions. This past week Genius NY, the largest unmanned systems accelerator, awarded one million dollars to Fotokite for its latest enterprise line of leashed drones. The company clinched the competition after demonstrating how its drones can fly for up to twenty-four hours continuously providing real-time video feed autonomously and safely above large population centers. Fotokite’s Chief Executive, Chris McCall, announced that the funds will be utilized to fulfill a contract with one of the largest fire truck manufacturers in the United States. “We’re building an add-on to fire and rescue vehicles and public safety vehicles to be added on top of for instance a fire truck. And then a firefighter is able to pull up to an emergency scene, push a button and up on top of the fire truck this box opens up, a Fotokite flies up and starts live streaming thermal and normal video down to all the firefighters on the ground,” boasted McCall.
Fotokite is not the only kite drone company marketing to fire fighters, Latvian-born startup Aerones is attaching firehoses to its massive multi-rotor unmanned aerial vehicles. Aerones claims to have successfully built a rapid response UAV that can climb up to a thousand feet within six minutes to extinguish fires from the air. This enables first responders to have a reach of close to ten times more than traditional fire ladders. The Y Combinator startup offers municipalities two models: a twenty-eight propeller version that can carry up to 441 pounds to a height of 984 feet and a thirty-six propeller version that ferriess over 650 pounds of equipment to ascend over 1,600 feet. However, immediate interest for the Aerones solution is coming from industrial clients such as wind farms. “Over the last two months, we’ve been very actively talking to wind turbine owners,” says Janis Putrams, CEO of Aerones. “We have lots of interest and letters of intent in Texas, Spain, Turkey, South America for wind turbine cleaning. And in places like Canada, the Nordic and Europe for de-icing. If the weather is close to freezing, ice builds up, and they have to stop the turbine.” TechCrunch reported last March that the company moved its sales operations to Silicon Valley.
The emergency response industry is also looking to other aerial solutions to tackle its most difficult challenges. For over a year, Zipline has been successfully delivering blood for critical transfusions to the most remote areas of Africa. The company announced earlier this month that it has filed with the FAA to begin testing later this year in America. This is welcome news for the USA’s rural health centers which are straddled with exploding costs, staff shortages and crippling infrastructure. In a Fast Company article about Zipline, the magazine reported that “Nearly half of rural providers already have a negative operating margin. As rural residents–who tend to be sicker than the rest of the country–have to rely on the smaller clinics that remain, drones could ensure that those clinics have access to necessary supplies. Blood products spoil quickly, and outside major hospitals, it’s common not to have the right blood on hand for a procedure. Using the drones would be faster, cheaper, and more reliable than delivering the supplies in a van or car.”
Keller Rinaudo, Zipline’s Chief Executive, describes, “There’s a lot that [the U.S.] can be doing better. And that’s what we think is ultimately the promise of future logistics and automated logistics. It’s not delivering tennis shoes or pizza to someone’s backyard. It’s providing universal access to healthcare when people need it the most.”
To date, Zipline has flown over 200,000 miles autonomously delivering 7,000 units of blood throughout Rwanda. To prepare for its US launch, the company re-engineered its entire platform to bolster its delivery capabilities. Rinaudo explains, “In larger countries, you’re going to need distribution centers and logistics systems that are capable of doing millions of deliveries a day rather than hundreds or thousands.” The new UAV is a small fixed-wing plane called the Zip that can soar close to 80 miles per hour enabling life-saving supplies such as blood, organ donations or vaccines to be delivered in a matter of minutes.
As I prepare to speak at Xponetial 2018 next month, I am inspired by these innovators who turn their mechanical inventions into life-saving solutions. Many would encourage Rinaudo and others to focus their energies on the seemingly more profitable sectors such as e-commerce delivery and industrial inspections. However, Rinaudo retorts that “Healthcare logistics is a way bigger market and a way bigger problem than most people realize. Globally it’s a $70 billion industry. The reality is that there are billions of people who do not have reliable access to healthcare and a big part of that is logistics. As a result of that, 5.2 million kids die every year due to lack of access to basic medical products. So Zipline’s not in a rush to bite off a bigger problem than that.”
The topic of utilizing life-saving technology will be discussed at the next RobotLab event on “The Politics Of Automation,” with Democratic Presidential Candidate Andrew Yang and New York Assemblyman Clyde Vanel on June 13th @ 6pm in NYC – RSVP Today!
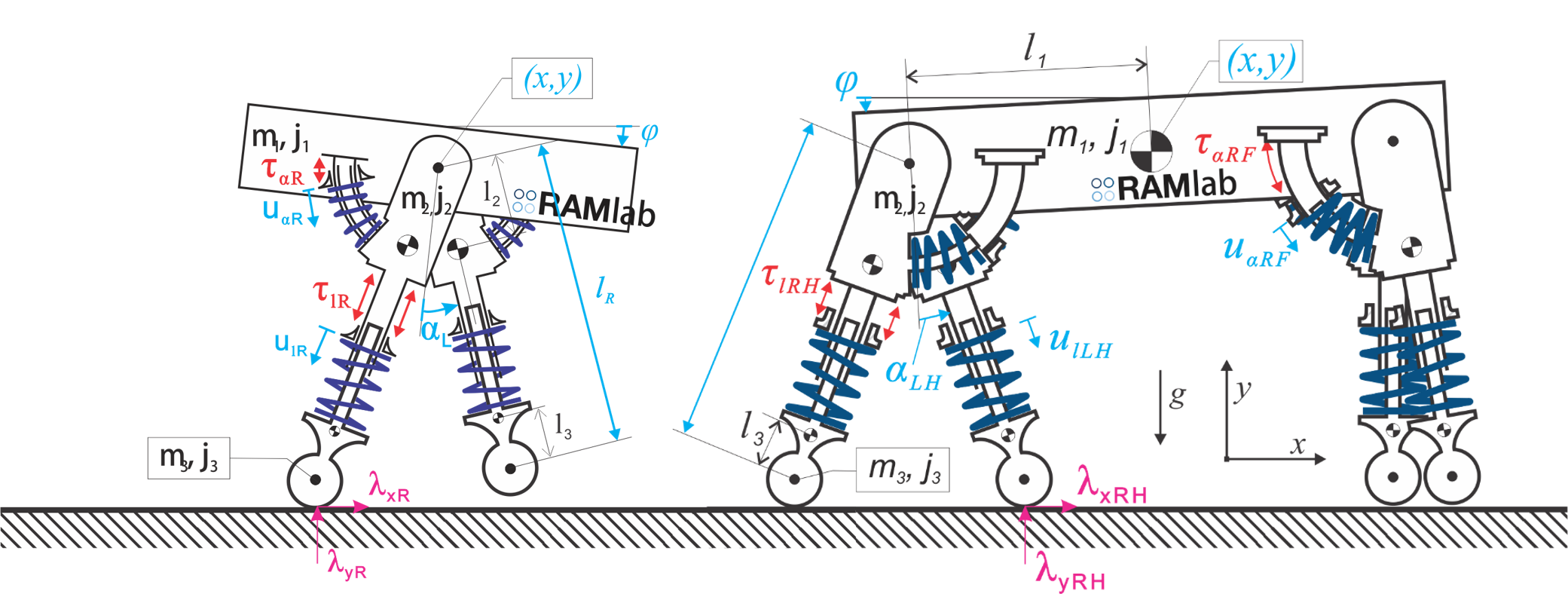
The choice of gait, that is whether we walk or run, comes to us so naturally that we hardly ever think about it. We walk at slow speeds and run at high speeds. If we get on a treadmill and slowly crank up the speed, we will start out with walking, but at some point we will switch to running; involuntarily and simply because it feels right. We are so accustomed to this, that we find it rather amusing to see someone walking at high speeds, for example, during the racewalk at the Olympics. This automatic choice of gait happens in almost all animals, though sometimes with different gaits. Horses, for example, tend to walk at slow speeds, trot at intermediate speeds, and gallop at high speeds. What is it that makes walking better suited for low speeds and running better for high speeds? How do we know that we have to switch, and why don’t we skip or gallop like horses? What exactly is it that constitutes walking, running, trotting, galloping, and all the other gaits that can be found in nature?
Researchers led by Dr. C. David Remy at the Robotics and Motion Laboratory (RAM-Lab) at the University of Michigan are interested in these and related questions for a very simple reason: they want to build legged robots that are agile, fast, and energy efficient. The ability to use different gaits might be a crucial element in this quest, since what is beneficial for humans and animals could potentially be equally beneficial for legged robots. That is still a big `could’, since we currently do not know if using different gaits will actually pay off, or, how suitable gaits for robots will look. Are they some form of walking or running, or will they be something completely different?
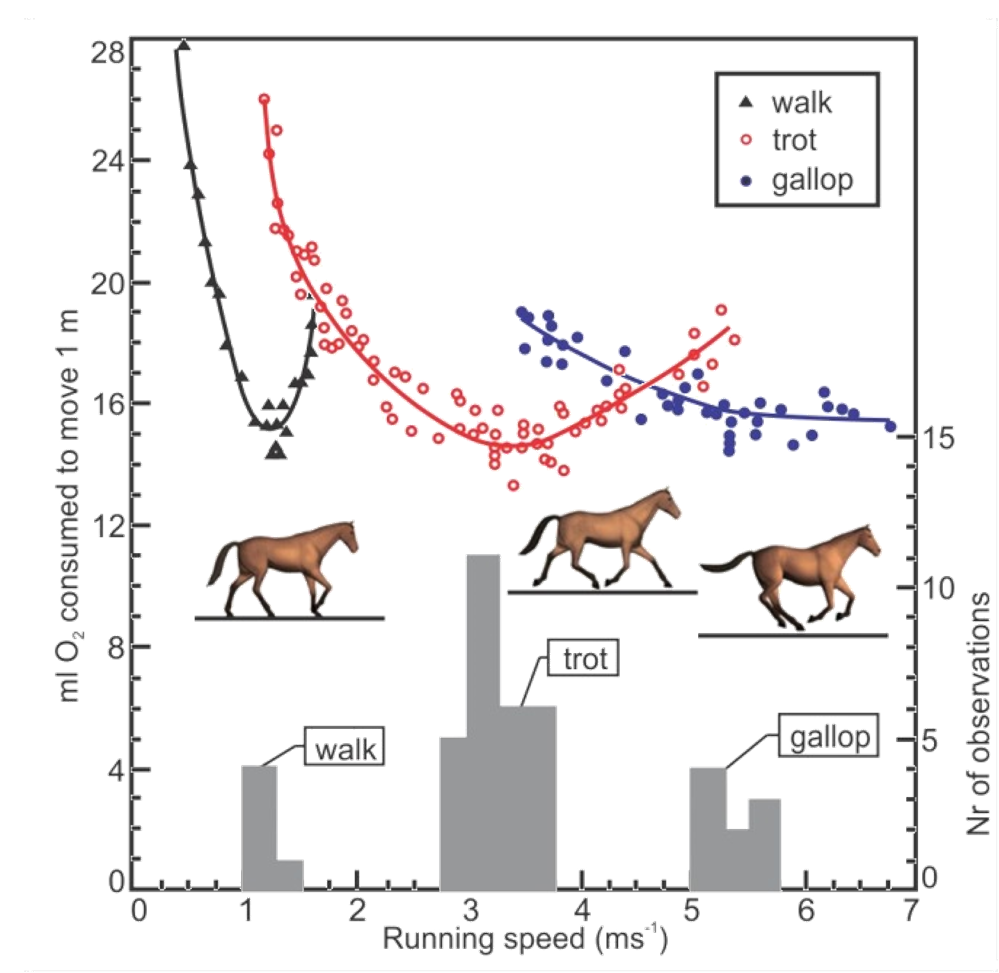
In nature, biomechanics research has shown that the choice of gait is closely related to the energetic cost of transport. This cost describes how many calories one needs to burn in order to move a certain distance. It is an important measure, as for many animals, food is often a scarce resource and efficient locomotion can be key for survival. To understand the implications of gait on the cost of transport, researchers can estimate energy consumption by measuring the amount of oxygen that a human or animal consumes while locomoting using different gaits. Using this technique, it has been shown that at low speeds, it simply requires less effort for humans to walk and at high speeds, less effort to run. The same holds for horses as they switch from walking to trotting to galloping: changing gaits saves energy.
This adaptation of a figure from the Hoyt and Taylor paper “Gait and the energetics of locomotion in horses” shows the metabolic cost of transport as a function of the forward speed. It is clear that as speed increases, there is an energetic benefit to transitioning from walking to trotting to galloping. Furthermore, when horses self-selected their velocities within a particular gait, they tended to choose to move near their energetic minima.
In order to understand if the same energetic saving can be achieved in robots, Dr. Remy’s team uses large scale numerical optimization. That is, after building a computer model of a legged robot, they essentially ask an algorithm to automatically find the most energetically economical way of moving forward. That is, they find the motion that minimizes the cost of transport. The computer solves this puzzle by simply trying out -in a systematic fashion- any possible way of using the model’s legs to move forward. The results of these optimizations are remarkable. Even though the computer has no prior notion of walking, running, or gait in general, the optimal motions that emerge through this process closely resemble gaits and gait sequences found in nature. By varying the target velocity of each motion, optimal gait sequences can then be identified. The surprising finding is that there are essentially no surprises: to move with as little effort as possible, bipedal robots should walk at slow speeds and run at high speeds; quadrupedal robots should walk, trot, and gallop. The remarkable thing is that this result was found despite the substantial differences in structure and actuation between animals and robots.
Further Readings:
Hoyt, Donald F., and C. Richard Taylor. “Gait and the energetics of locomotion in horses.” Nature 292.5820 (1981): 239.
Xi, Weitao, Yevgeniy Yesilevskiy, and C. David Remy. “Selecting gaits for economical locomotion of legged robots.” The International Journal of Robotics Research 35.9 (2016): 1140-1154.
Xi, Weitao, and C. David Remy. “Optimal gaits and motions for legged robots.” Intelligent Robots and Systems (IROS 2014), 2014 IEEE/RSJ International Conference on. IEEE, 2014.
Remy, C. David. Optimal exploitation of natural dynamics in legged locomotion. Diss. ETH Zurich, 2011.
Great news here at Dreaming Robots as we’ve just been able to confirm with Sky Atlantic and NowTV that we will be live tweeting again each episode of the new series of HBO’s completely fantastic Westworld, starting with the Season 2 premiere on 23 April.
We’re very keen for the reboot of Westworld, and that we’ll be able to bring you commentary on all the action, as we did with Season 1. See, for example, some out Twitter moments collected below.
(We didn’t quite manage a superguide for every episode last time; we got them for Episodes 1, 2, 3, and 9, but we’ll aim to get every episode covered this time around!)
We hope that everyone will appreciate the extra ideas and content that the Sheffield Robotics team, Tony Prescott and I, can bring to a series already rich in imagination and challenging issues.
Look for our tweets and the other announcements related to Westworld by following @DreamingRobots.
In the meantime, here are some of Dreaming Robots posts from Season 1 of Westworld, to re-kindle your interest and get you ready for Season 2:
VTT's proof of concept demo showed that a range of sensors or smart identifications can be added to 3D printed metal parts during manufacture, in order to track the performance and condition of machines or devices, or verify the authenticity of the parts.
Drilling out a hole in the skull base has to be done with great precision and often takes many hours. It is an intervention that requires the maximum from a surgeon. Researchers from TU/e have therefore developed a surgery robot to take over this task. With sub-millimeter precision, the robot can automatically and safely mill a cavity of the desired shape and dimensions. Jordan Bos will receive his Ph.D. on 16 April for the robot he designed and built. The robot is expected to perform its first surgery within five years.
In this episode, Audrow Nash speaks with Michael Laskey, PhD student at UC Berkeley, about a method for robust imitation learning, called DART. Laskey discusses how DART relates to previous imitation learning methods, how this approach has been used for folding bed sheets, and on the importance of robotics leveraging theory in other disciplines.
To learn more, see this post on Robohub from the Berkeley Artificial Intelligence Research (BAIR) Lab.
Michael Laskey
Michael Laskey is a Ph.D. Candidate in EECS at UC Berkeley, advised by Prof. Ken Goldberg in the AUTOLAB (Automation Sciences). Michael’s Ph.D. develops new algorithms for Deep Learning of robust robot control policies and examines how to reliably apply recent deep learning advances for scalable robotics learning in challenging unstructured environments. Michael received a B.S. in Electrical Engineering from the University of Michigan, Ann Arbor. His work has been nominated for multiple best paper awards at IEEE, ICRA, and CASE and has been featured in news outlets such as MIT Tech Review and Fast Company.
725 exhibitors will showcase a full range of technologies, products and solutions in more than 370,000 square feet of space filled with hands-on exhibits, interactive demos, and new products.
There are 4 possible scenarios for collaboration between user and robot. The bottom line is that in truth the only safe way to work with a robot is to guard it.
AUVSI XPONENTIAL 2018 will take place in Denver, CO April 30th - May 3rd. This RoboticsTomorrow.com Special Tradeshow report aims to bring you news, articles and products from this years event.
Over the years, we’ve gotten pretty used to glasses with photochromic lenses, which automatically darken when exposed to bright light. This Wednesday, however, Johnson & Johnson Vision announced the upcoming availability of its self-tinting contact lenses.
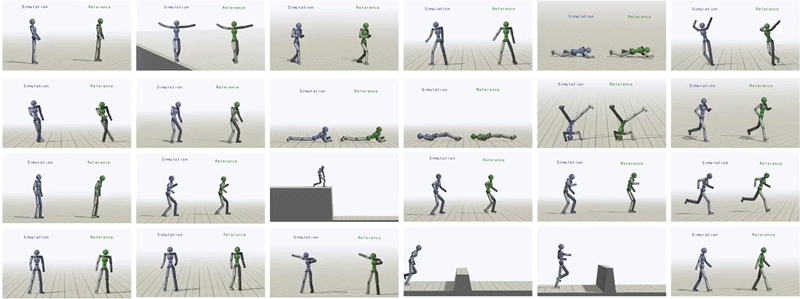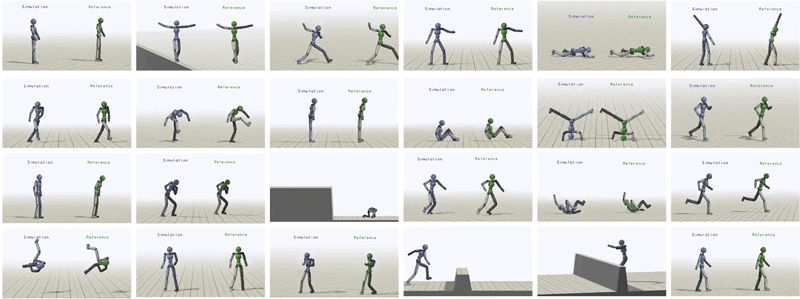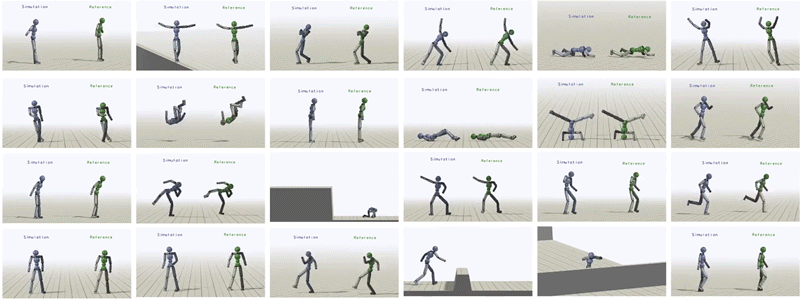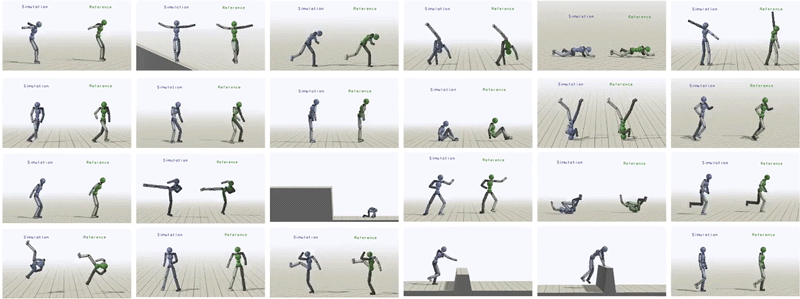
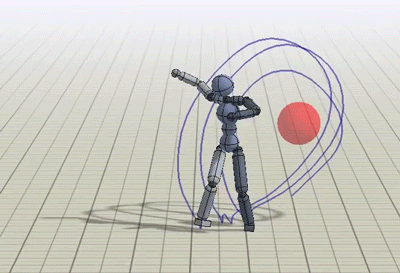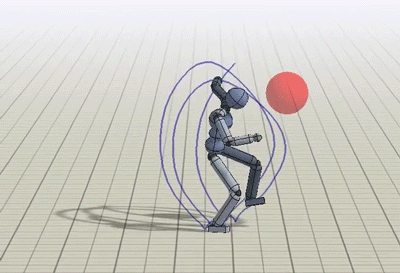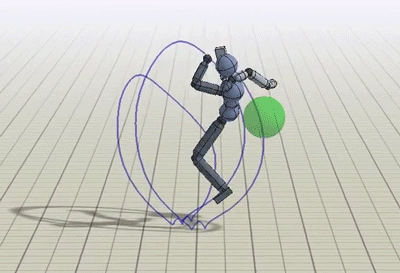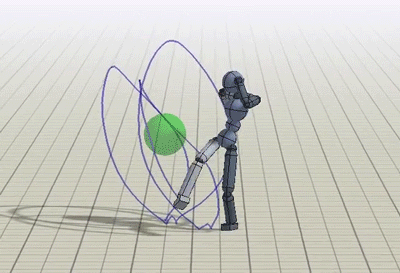
Motion control problems have become standard benchmarks for reinforcement learning, and deep RL methods have been shown to be effective for a diverse suite of tasks ranging from manipulation to locomotion. However, characters trained with deep RL often exhibit unnatural behaviours, bearing artifacts such as jittering, asymmetric gaits, and excessive movement of limbs. Can we train our characters to produce more natural behaviours?
Simulated humanoid performing a variety of highly dynamic and acrobatic skills.
A wealth of inspiration can be drawn from computer graphics, where the physics-based simulation of natural movements have been a subject of intense study for decades. The greater emphasis placed on motion quality is often motivated by applications in film, visual effects, and games. Over the years, a rich body of work in physics-based character animation have developed controllers to produce robust and natural motions for a large corpus of tasks and characters. These methods often leverage human insight to incorporate task-specific control structures that provide strong inductive biases on the motions that can be achieved by the characters (e.g. finite-state machines, reduced models, and inverse dynamics). But as a result of these design decisions, the controllers are often specific to a particular character or task, and controllers developed for walking may not extend to more dynamic skills, where human insight becomes scarce.
In this work, we will draw inspiration from the two fields to take advantage of the generality afforded by deep learning models while also producing naturalistic behaviours that rival the state-of-the-art in full body motion simulation in computer graphics. We present a conceptually simple RL framework that enables simulated characters to learn highly dynamic and acrobatic skills from reference motion clips, which can be provided in the form of mocap data recorded from human subjects. Given a single demonstration of a skill, such as a spin-kick or a backflip, our character is able to learn a robust policy to imitate the skill in simulation. Our policies produce motions that are nearly indistinguishable from mocap.
Motion Imitation
In most RL benchmarks, simulated characters are represented using simple models that provide only a crude approximation of real world dynamics. Characters are therefore prone to exploiting idiosyncrasies of the simulation to develop unnatural behaviours that are infeasible in the real world. Incorporating more realistic biomechanical models can lead to more natural behaviours. But constructing high-fidelity models can be extremely challenging, and the resulting motions may nonetheless be unnatural.
An alternative is to take a data-driven approach, where reference motion capture of humans provides examples of natural motions. The character can then be trained to produce more natural behaviours by imitating the reference motions. Imitating motion data in simulation has a longhistory in computer animation and has seen some recent demonstrations with deep RL. While the results do appear more natural, they are still far from being able to faithfully reproduce a wide variety of motions.
In this work, our policies will be trained through a motion imitation task, where the goal of the character is to reproduce a given kinematic reference motion. Each reference motion is represented by a sequence of target poses ${\hat{q}_0, \hat{q}_1,\ldots,\hat{q}_T}$, where $\hat{q}_t$ is the target pose at timestep $t$. The reward function is to minimize the least squares pose error between the target pose $\hat{q}_t$ and the pose of the simulated character $q_t$,
While more sophisticated methods have been applied for motion imitation, we found that simply minimizing the tracking error (along with a couple of additional insights) works surprisingly well. The policies are trained by optimizing this objective using PPO.
With this framework, we are able to develop policies for a rich repertoire of challenging skills ranging from locomotion to acrobatics, martial arts to dancing.
The humanoid learns to imitate various skills. The blue character is the simulated character, and the green character is replaying the respective mocap clip. Top left: sideflip. Top right: cartwheel. Bottom left: kip-up. Bottom right: speed vault.
Next, we compare our method with previous results that used (e.g. generative adversarial imitation learning (GAIL)) to imitate mocap clips. Our method is substantially simpler than GAIL and it is able to better reproduce the reference motions. The resulting policy avoids many of the artifacts commonly exhibited by deep RL methods, and enables the character to produce a fluid life-like running gait.
Comparison of our method (left) and work from Merel et al. [2017] using GAIL to imitate mocap data. Our motions appear significantly more natural than previous work using deep RL.
Insights
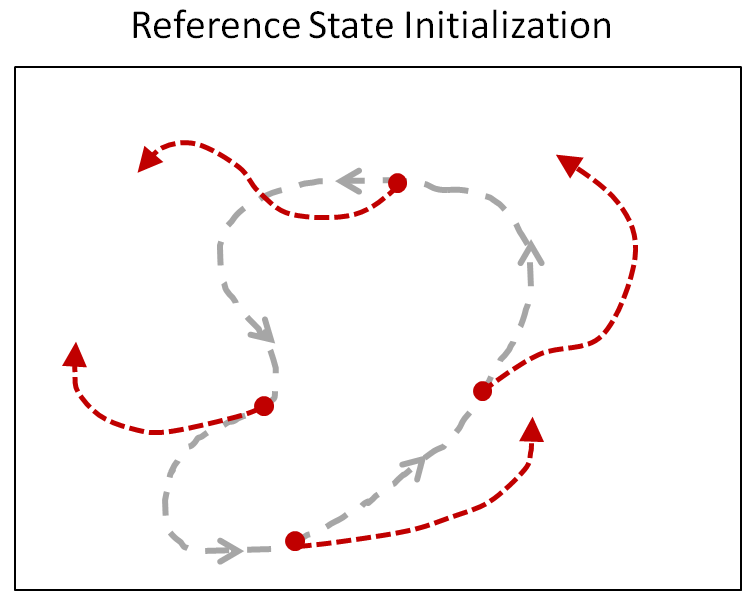
Reference State Initialization (RSI)
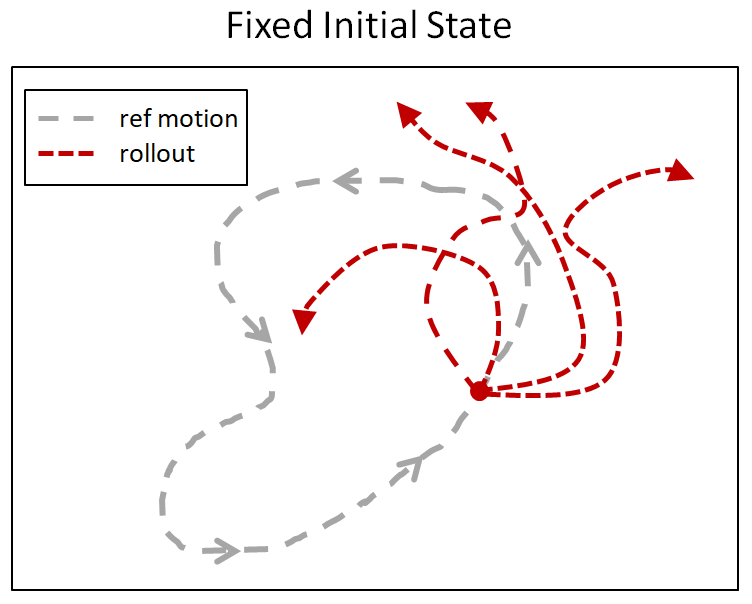
Suppose the character is trying to imitate a backflip. How would it know that doing a full rotation midair will result in high rewards? Since most RL algorithms are retrospective, they only observe rewards for states they have visited. In the case of a backflip, the character will have to observe successful trajectories of a backflip before it learns that those states will yield high rewards. But since a backflip can be very sensitive to the initial conditions at takeoff and landing, the character is unlikely to accidentally execute a successful trajectory through random exploration. To give the character a hint, at the start of each episode, we will initialize the character to a state sampled randomly along the reference motion. So sometimes the character will start on the ground, and sometimes it will start in the middle of the flip. This allows the character to learn which states will result in high rewards even before it has acquired the proficiency to reach those states.
RSI provides the character with a richer initial state distribution by initializing it to random point along the reference motion.
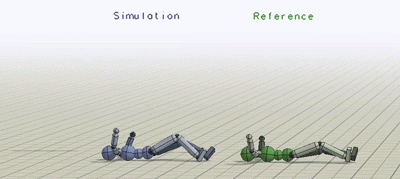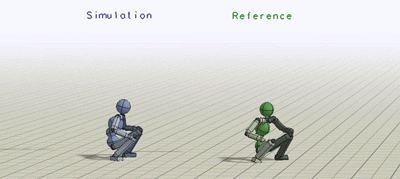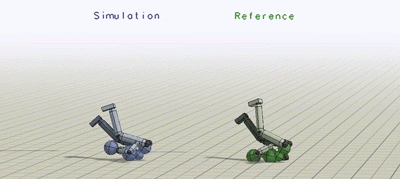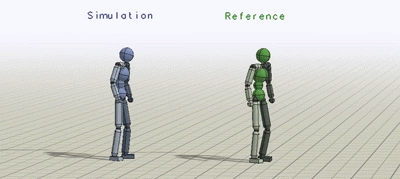
Below is a comparison of the backflip policy trained with RSI and without RSI, where the character is always initialized to a fixed initial state at the start of the motion. Without RSI, instead of learning a flip, the policy just cheats by hopping backwards.
Comparison of policies trained without RSI or ET. RSI and ET can be crucial for learning more dynamics motions. Left: RSI+ET. Middle: No RSI. Right: No ET.
Early Termination (ET)
Early termination is a staple for RL practitioners, and it is often used to improve simulation efficiency. If the character gets stuck in a state from which there is no chance of success, then the episode is terminated early, to avoid simulating the rest. Here we show that early termination can in fact have a significant impact on the results. Again, let’s consider a backflip. During the early stages of training, the policy is terrible and the character will spend most of its time falling. Once the character has fallen, it can be extremely difficult for it to recover. So the rollouts will be dominated by samples where the character is just struggling in vain on the ground. This is analogous to the class imbalance problem encountered by other methodologies such as supervised learning. This issue can be mitigated by terminating an episode as soon as the character enters such a futile state (e.g. falling). Coupled with RSI, ET helps to ensure that a larger portion of the dataset consists of samples close to the reference trajectory. Without ET the character never learns to perform a flip. Instead, it just falls and then tries to mime the motion on the ground.
More Results
In total, we have been able to learn over 24 skills for the humanoid just by providing it with different reference motions.
Humanoid trained to imitate a rich repertoire of skills.
In addition to imitating mocap clips, we can also train the humanoid to perform some additional tasks like kicking a randomly placed target, or throwing a ball to a target.
Policies trained to kick and throw a ball to a random target.
We can also train a simulated Atlas robot to imitate mocap clips from a human. Though the Atlas has a very different morphology and mass distribution, it is still able to reproduce the desired motions. Not only can the policies imitate the reference motions, they can also recover from pretty significant perturbations.
Atlas trained to perform a spin-kick and backflip. The policies are robust to significant perturbations.
But what do we do if we don’t have mocap clips? Suppose we want to simulate a T-Rex. For various reasons, it is a bit difficult to mocap a T-Rex. So instead, we can have an artist hand-animate some keyframes and then train a policy to imitate those.
Simulated T-Rex trained to imitate artist-authored keyframes.
By why stop at a T-Rex? Let’s train a lion:
Simulated lion. Reference motion courtesy of Ziva Dynamics.
and a dragon:
Simulated dragon with a 418D state space and 94D action space.
The story here is that a simple method ends up working surprisingly well. Just by minimizing the tracking error, we are able to train policies for a diverse collection of characters and skills. We hope this work will help inspire the development of more dynamic motor skills for both simulated characters and robots in the real world. Exploring methods for imitating motions from more prevalent sources such as video is also an exciting avenue for scenarios that are challenging to mocap, such as animals and cluttered environments.
We would like to thank the co-authors of this work: Pieter Abbeel, Sergey Levine, and Michiel van de Panne. This project was done in collaboration with the University of British Columbia. This article was initially published on the BAIR blog, and appears here with the authors’ permission.


 The choice of gait, that is whether we walk or run, comes to us so naturally that we hardly ever think about it. We walk at slow speeds and run at high speeds. If we get on a treadmill and slowly crank up the speed, we will start out with walking, but at some point we will switch to running; involuntarily and simply because it feels right. We are so accustomed to this, that we find it rather amusing to see someone walking at high speeds, for example, during the racewalk at the Olympics. This automatic choice of gait happens in almost all animals, though sometimes with different gaits. Horses, for example, tend to walk at slow speeds, trot at intermediate speeds, and gallop at high speeds. What is it that makes walking better suited for low speeds and running better for high speeds? How do we know that we have to switch, and why don’t we skip or gallop like horses? What exactly is it that constitutes walking, running, trotting, galloping, and all the other gaits that can be found in nature?
The choice of gait, that is whether we walk or run, comes to us so naturally that we hardly ever think about it. We walk at slow speeds and run at high speeds. If we get on a treadmill and slowly crank up the speed, we will start out with walking, but at some point we will switch to running; involuntarily and simply because it feels right. We are so accustomed to this, that we find it rather amusing to see someone walking at high speeds, for example, during the racewalk at the Olympics. This automatic choice of gait happens in almost all animals, though sometimes with different gaits. Horses, for example, tend to walk at slow speeds, trot at intermediate speeds, and gallop at high speeds. What is it that makes walking better suited for low speeds and running better for high speeds? How do we know that we have to switch, and why don’t we skip or gallop like horses? What exactly is it that constitutes walking, running, trotting, galloping, and all the other gaits that can be found in nature?