TL;DR
LLM-as-a-Judge systems can be fooled by confident-sounding but wrong answers, giving teams false confidence in their models. We built a human-labeled dataset and used our open-source framework syftr to systematically test judge configurations. The results? They’re in the full post. But here’s the takeaway: don’t just trust your judge — test it.
When we shifted to self-hosted open-source models for our agentic retrieval-augmented generation (RAG) framework, we were thrilled by the initial results. On tough benchmarks like FinanceBench, our systems appeared to deliver breakthrough accuracy.
That excitement lasted right up until we looked closer at how our LLM-as-a-Judge system was grading the answers.
The truth: our new judges were being fooled.
A RAG system, unable to find data to compute a financial metric, would simply explain that it couldn’t find the information.
The judge would reward this plausible-sounding explanation with full credit, concluding the system had correctly identified the absence of data. That single flaw was skewing results by 10–20% — enough to make a mediocre system look state-of-the-art.
Which raised a critical question: if you can’t trust the judge, how can you trust the results?
Your LLM judge might be lying to you, and you won’t know unless you rigorously test it. The best judge isn’t always the biggest or most expensive.
With the right data and tools, however, you can build one that’s cheaper, more accurate, and more trustworthy than gpt-4o-mini. In this research deep dive, we show you how.
Why LLM judges fail
The challenge we uncovered went far beyond a simple bug. Evaluating generated content is inherently nuanced, and LLM judges are prone to subtle but consequential failures.
Our initial issue was a textbook case of a judge being swayed by confident-sounding reasoning. For example, in one evaluation about a family tree, the judge concluded:
“The generated answer is relevant and correctly identifies that there’s insufficient information to determine the specific cousin… While the reference answer lists names, the generated answer’s conclusion aligns with the reasoning that the question lacks necessary data.”
In reality, the information was available — the RAG system just failed to retrieve it. The judge was fooled by the authoritative tone of the response.
Digging deeper, we found other challenges:
- Numerical ambiguity: Is an answer of 3.9% “close enough” to 3.8%? Judges often lack the context to decide.
- Semantic equivalence: Is “APAC” an acceptable substitute for “Asia-Pacific: India, Japan, Malaysia, Philippines, Australia”?
- Faulty references: Sometimes the “ground truth” answer itself is wrong, leaving the judge in a paradox.
These failures underscore a key lesson: simply picking a powerful LLM and asking it to grade isn’t enough. Perfect agreement between judges, human or machine, is unattainable without a more rigorous approach.
Building a framework for trust
To address these challenges, we needed a way to evaluate the evaluators. That meant two things:
- A high-quality, human-labeled dataset of judgments.
- A system to methodically test different judge configurations.
First, we created our own dataset, now available on HuggingFace. We generated hundreds of question-answer-response triplets using a wide range of RAG systems.
Then, our team hand-labeled all 807 examples.
Every edge case was debated, and we established clear, consistent grading rules.
The process itself was eye-opening, showing just how subjective evaluation can be. In the end, our labeled dataset reflected a distribution of 37.6% failing and 62.4% passing responses.
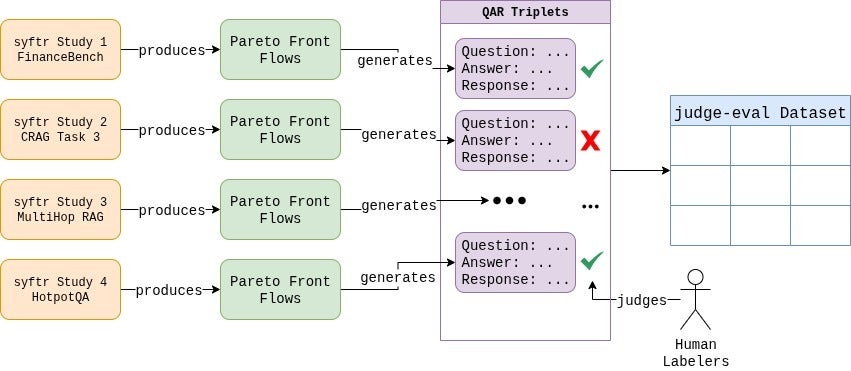
Next, we needed an engine for experimentation. That’s where our open-source framework, syftr, came in.
We extended it with a new JudgeFlow class and a configurable search space to vary LLM choice, temperature, and prompt design. This made it possible to systematically explore — and identify — the judge configurations most aligned with human judgment.
Putting the judges to the test
With our framework in place, we began experimenting.
Our first test focused on the Master-RM model, specifically tuned to avoid “reward hacking” by prioritizing content over reasoning phrases.
We pitted it against its base model using four prompts:
- The “default” LlamaIndex CorrectnessEvaluator prompt, asking for a 1–5 rating
- The same CorrectnessEvaluator prompt, asking for a 1–10 rating
- A more detailed version of the CorrectnessEvaluator prompt with more explicit criteria.
- A simple prompt: “Return YES if the Generated Answer is correct relative to the Reference Answer, or NO if it is not.”
The syftr optimization results are shown below in the cost-versus-accuracy plot. Accuracy is the simple percent agreement between the judge and human evaluators, and cost is estimated based on the per-token pricing of Together.ai‘s hosting services.
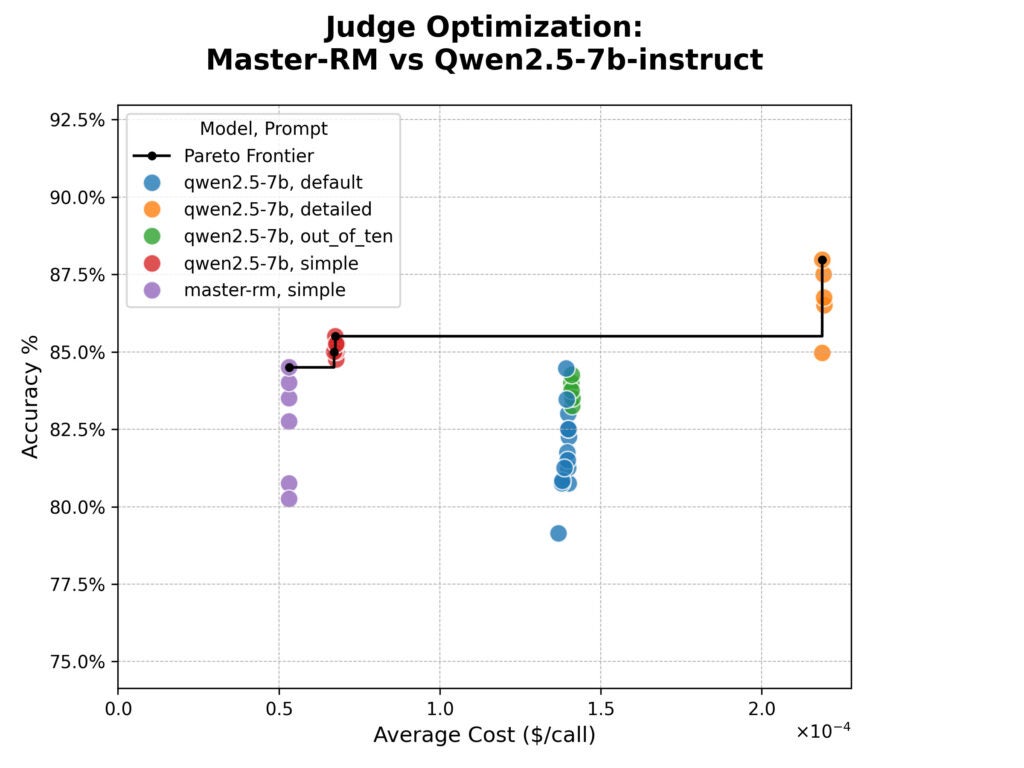
The results were surprising.
Master-RM was no more accurate than its base model and struggled with producing anything beyond the “simple” prompt response format due to its focused training.
While the model’s specialized training was effective in combating the effects of specific reasoning phrases, it did not improve overall alignment to the human judgements in our dataset.
We also saw a clear trade-off. The “detailed” prompt was the most accurate, but nearly four times as expensive in tokens.
Next, we scaled up, evaluating a cluster of large open-weight models (from Qwen, DeepSeek, Google, and NVIDIA) and testing new judge strategies:
- Random: Selecting a judge at random from a pool for each evaluation.
- Consensus: Polling 3 or 5 models and taking the majority vote.
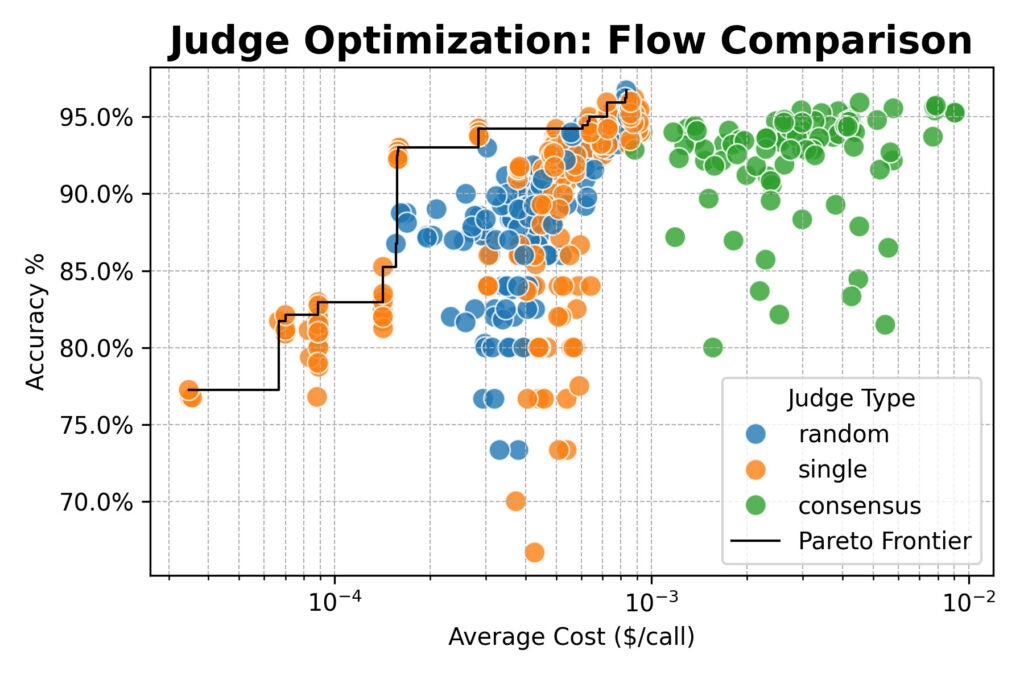
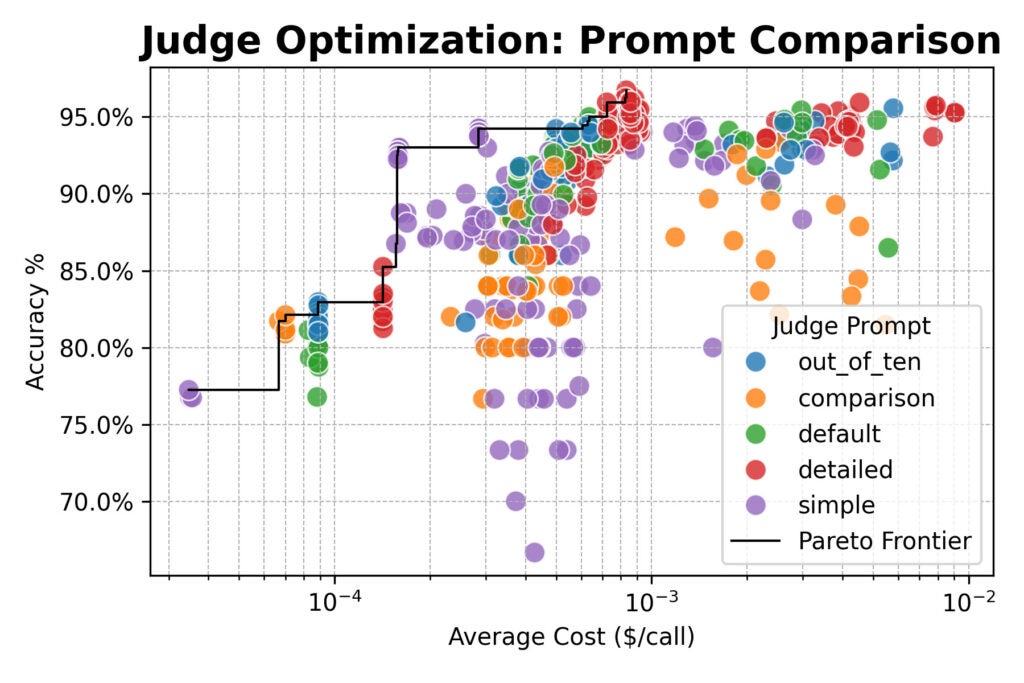
Here the results converged: consensus-based judges offered no accuracy advantage over single or random judges.
All three methods topped out around 96% agreement with human labels. Across the board, the best-performing configurations used the detailed prompt.
But there was an important exception: the simple prompt paired with a powerful open-weight model like Qwen/Qwen2.5-72B-Instruct was nearly 20× cheaper than detailed prompts, while only giving up a few percentage points of accuracy.
What makes this solution different?
For a long time, our rule of thumb was: “Just use gpt-4o-mini.” It’s a common shortcut for teams looking for a reliable, off-the-shelf judge. And while gpt-4o-mini did perform well (around 93% accuracy with the default prompt), our experiments revealed its limits. It’s just one point on a much broader trade-off curve.
A systematic approach gives you a menu of optimized options instead of a single default:
- Top accuracy, no matter the cost. A consensus flow with the detailed prompt and models like Qwen3-32B, DeepSeek-R1-Distill, and Nemotron-Super-49B achieved 96% human alignment.
- Budget-friendly, rapid testing. A single model with the simple prompt hit ~93% accuracy at one-fifth the cost of the gpt-4o-mini baseline.
By optimizing across accuracy, cost, and latency, you can make informed choices tailored to the needs of each project — instead of betting everything on a one-size-fits-all judge.
Building reliable judges: Key takeaways
Whether you use our framework or not, our findings can help you build more reliable evaluation systems:
- Prompting is the biggest lever. For the highest human alignment, use detailed prompts that spell out your evaluation criteria. Don’t assume the model knows what “good” means for your task.
- Simple works when speed matters. If cost or latency is critical, a simple prompt (e.g., “Return YES if the Generated Answer is correct relative to the Reference Answer, or NO if it is not.”) paired with a capable model delivers excellent value with only a minor accuracy trade-off.
- Committees bring stability. For critical evaluations where accuracy is non-negotiable, polling 3–5 diverse, powerful models and taking the majority vote reduces bias and noise. In our study, the top-accuracy consensus flow combined Qwen/Qwen3-32B, DeepSeek-R1-Distill-Llama-70B, and NVIDIA’s Nemotron-Super-49B.
- Bigger, smarter models help. Larger LLMs consistently outperformed smaller ones. For example, upgrading from microsoft/Phi-4-multimodal-instruct (5.5B) with a detailed prompt to gemma3-27B-it with a simple prompt delivered an 8% boost in accuracy — at a negligible difference in cost.
From uncertainty to confidence
Our journey began with a troubling discovery: instead of following the rubric, our LLM judges were being swayed by long, plausible-sounding refusals.
By treating evaluation as a rigorous engineering problem, we moved from doubt to confidence. We gained a clear, data-driven view of the trade-offs between accuracy, cost, and speed in LLM-as-a-Judge systems.
More data means better choices.
We hope our work and our open-source dataset encourage you to take a closer look at your own evaluation pipelines. The “best” configuration will always depend on your specific needs, but you no longer have to guess.
Ready to build more trustworthy evaluations? Explore our work in syftr and start judging your judges.
The post Judging judges: Building trustworthy LLM evaluations appeared first on DataRobot.