 The Industrial League arena at RoboCup2025.
The Industrial League arena at RoboCup2025.
RoboCup is an international scientific initiative with the goal of advancing the state of the art of intelligent robots, AI and automation. The annual RoboCup event took place from 15-21 July in Salvador, Brazil. The Logistics League forms part of the Industrial League and is an application-driven league inspired by the industrial scenario of a smart factory. Ahead of the Brazil meeting, we spoke with three key members of the league to find out more. Alexander Ferrein is a RoboCup Trustee overseeing the Industrial League, and Till Hofmann and Wataru Uemura are Logistics League Executive Committee members.
Could you start by giving us an introduction to the Logistics League?
Alexander Ferrein: The idea of the Logistics League is to have robots helping in intra-production logistics. The playing field is set up with different machines and the robots need to bring raw materials and products to the machines and pick products up from them. There are orders coming in for different products of different complexities. The idea is that the robots deliver these products after they have been machined, at a certain handover point, and then the team will be awarded points. The setup is that we have six machines per team, and three robots operating in the smart factory.
There are two teams competing at the same time on different sides of the field. Most of the machines are on the home side of the field, but some machines are also on the opponent’s side of the field. The teams need to show basic robotics skills like navigation skills and collision avoidance. For the production of products we have little discs that have different colours and can be stacked on top of each other, and they have different caps. We have around 550 different items that can be produced. We don’t focus so much on the handling of the parts, therefore the manipulating mechanisms are quite simple and are usually custom built by the teams. They just need to grab these discs and drive them around and put them on conveyor belts on the machines.
The main focus is on the production logistics and the planning phase. The complex products need to be produced or machined by a team of robots – without this planning and team work it wouldn’t be possible to deliver the products within the allotted time in the competition.
Until now, we had been supported by Festo didactics, who supplied the machines. However, they pulled out in February and told us that they won’t support us in bringing the machines to Brazil. Our team in Aachen has a complete field set up, so we are in the (not so easy) process of packing the machines up in pallets and shipping them to Brazil.
Till Hofmann: One important detail is that all the products that need to be manufactured, the orders for those come online, and the number of possible products is very high. Therefore, you can’t do any planning in advance – you can’t just create a big database that contains one sequence that you execute for every possible product, that doesn’t really work. So the robots need to do online planning. Due to the fact that we have multiple robots in the team and then also the opponents teams’ robots on the field, many things go differently than planned, so a very big aspect of the competition is execution monitoring and online replanning. Basically you create an initial plan, but you need to constantly adapt that plan to what actually happens during execution. I just want to stress that in contrast to other RoboCup competitions, it’s really a long-horizon planning task in the sense that we usually need to do actions on a time horizon of five to ten minutes to actually get to an intermediate goal of producing one of those products.
Wataru Uemura: The focus of our league is on how to handle the production line. The three mobile robots are a very important part. At first these were autonomous guided robots, but now they are completely autonomous mobile robots. The robots need to decide on their path to make the product.

Could you talk about some of the challenges the teams face in the league, and is there a challenge or aspect of the competition that the teams have found particularly difficult?
Alexander: First of all, one needs to say that it is a really tough problem that we are facing here. So the teams that are starting new, they have to deal with all of the robotic aspects, so mobile robots, autonomous intelligence systems, they need to drive around, map, interact with the machines. As these items that we are pushing around are non-standard things, they also need to build their own manipulating devices. And then there is this massive planning aspect of the league, which is also not so easy. When we started this in 2011, 2012, we were thinking that this must be a solved problem, that one could use scheduling systems, that production is digital, and that everything would be easy. However, we found out it’s not actually easy, and there are no off-the-shelf solutions for a fleet of robots doing planning and production.
Looking at our team (which has become particularly successful over the years) and from observing the other teams as a trustee, I think that the integration aspect of all the different tasks is really a hard thing. Having a software system that is capable of so many things, communicating with the centralized referee box, and making it run within the time limit of a match, is the major challenge. Today, navigation of a robot is not the big issue, basically, but getting it integrated into your software system and building all the rest around the planning components and so on, this is, from my point of view, the major challenge.
Till: As I mentioned, I think the combination of long-horizon planning and execution monitoring is particularly difficult. We do have a lot of failures during one production run, because of hardware limitations and problems with the robots. Sometimes the machines themselves fail and they need to deal with this, without being able to solve the problem itself, because it’s not in their control. So they need to do a lot of reasoning that considers all the different cases that may happen. For example, suddenly you have a product appearing in a machine and you no longer know the configuration because this information was lost on the way. How do you deal with this? Another example is that the robot drops a piece while it is driving around and then tries to feed it into the machine. Then the machine reports a failure and the team needs to keep its world model up-to-date to know that this product is no longer where they thought it was. How do we deal with this?
Will there be any new challenges introduced for RoboCup 2025?
Alexander: Because the problem we are trying to solve is so hard, we don’t have many teams in the league. We had a new team at RoboCup2023, in Bordeaux, and they are now consistently coming to the RoboCups, which is nice. Apart from this, we have a core of three to five teams that participate in the league. As the challenge itself is hard to get into, the skills only develop slowly, so new challenges are not really introduced. There are slight changes here and there. One of the major changes in recent years was during Coronavirus times where we had to abandon the whole match aspect because we couldn’t play with two teams at the same time. We introduced aspects of the game as challenges. Now we have a challenge track as well, where teams can just focus on certain aspects of the league and do not need to play the full game.
The skills of the teams are not developing in such a way that we really need to add new challenges because it is still unsolved and hard for all the teams to get the robots running, because we have so many different aspects.
I understand that you are thinking about some changes to the league. Could you say more about this?
Alexander: Yes, we have some ideas for a new Industrial League. As Festo are pulling out we don’t see the need to stick with this particular machine type. We had a workshop earlier this year with all the teams and organising committees and we’re proposing a future challenge, or league. We will discuss this at RoboCup2025.
Till: We actually already had discussions with @work, and agreed that the long-term goal is to merge the two competitions into one big Industrial League. Next year, we will start converging by doing some kind of collaboration challenge or crossover challenge where teams from @work will collaborate with what’s now the Logistics League, but will be the Smart Manufacturing League by that time. Then hopefully, in two or three years, this will be one big league rather than separate industrial competitions. And the idea of the league that we’re currently planning to migrate to is really a broader smart manufacturing scenario where we have different aspects of smart manufacturing. So currently it’s really only the production logistics part. But in the future, we also want to include the assembly itself as part of the competition and also extend this to humanoid robots and also focus on human-robot collaboration in this manufacturing setting.
So this will be very different to the Logistics League as it is right now. How we will do the migration from what we have to that new league without losing all the teams is something that’s still in the making.
Alexander: I also don’t think we shouldn’t restrict ourselves to just one type of robot. As we see, there is something going on with respect to humanoid robots, and the Rescue League is proposing a quadruped robot. In the @Home League there are ideas to introduce the staircases where you need more agility in these settings. So for me, I wouldn’t restrict the type of robots that we’re using. We are just thinking about proposing challenges that are looking towards the future. So far we have been doing things that we thought might be relevant to industry, but industry is not very interested in what we are doing here. At least, they are not knocking at our doors and asking what our solutions are. That’s also another aspect that we will possibly discuss at Robocup 2025 – how we could increase our impact as a league for the outside world.
So that’s one of the aims, I guess, to evolve in a way such that industry will be more interested?
Alexander: Yes, be relevant, right? I mean, you see so much going on, in particular in China with the robot manufacturing OEMs [original equipment manufacturers] that build these robots in a few years that have quite impressive capabilities. And well, we stand aside and just watch. So maybe we should use those robots, and integrate them into our process. It’s very important that we are opening our minds to envision a future that’s different from today.
About the interviewees

|
Alexander Ferrein received his MSc in Computer Science (Dipl.-Inform.) and his PhD (Dr. rer. nat) from Aachen University in 2001 and 2007, respectively. Between 2009-2011 he joined the Robotics and Agents Research Lab, University of Cape Town, as a postdoctoral research fellow with Feodor-Lynen scholarship granted by the Alexander-von-Humboldt Foundation. He then re-joined the Knowledge-Based Systems Group at Aachen University before he became a professor for Robotics and Computer Science at FH Aachen University of Applied Sciences. He is a heading the Mobile Autonomous Systems & Cognitive Robotics Institute at Aachen Applied Science University. His research focusses on the field of Artificial Intelligence and Cognitive Robotics. Since 2015 he is member of the Advisory Committee of the African-German Network of Excellence in Science whose Vice-president he was between 2019-2023. His research concentrates on the field of cognitive robotics. In particular, he is interested in high-level control and decision making of robots and agents acting under real-time constraints. |

|
Till Hofmann is a Postdoc at RWTH Aachen University. His research focuses on planning, plan execution, generalized planning as well as reactive synthesis, with a particular focus on planning for robotics. He was a participant in the RoboCup Logistics League from 2016 until 2019 and member of the technical committee from 2017 until 2020. Since 2024, he is on the executive committee of the RCLL. |

|
Wataru Uemura was born in 1977, and received B.E, M.E. and D.E. degrees from Osaka City University, in 2000, 2002, and 2005. He is an associate professor in Electronics, Information and Communication Engineering Course, Faculty of Advanced Science and Technology, Ryukoku University in Shiga, Japan. He is a member of IEEE, RoboCup and others. He is a chairperson of the RoboCup Japanese National Committee. He is an executive committee member of RoboCup Logistics League. He was a member of the Industrial Robotics Competition Committee, the World Robot Summit. He was TPC Vice Chairs of GCCE 2012, Conference Chair of GCCE 2016, and Publication Chairs of GCCE (Global Conference on Consumer Electronics). He is a member of the World Skills in Japan organizing committee of Autonomous Mobile Robots. |

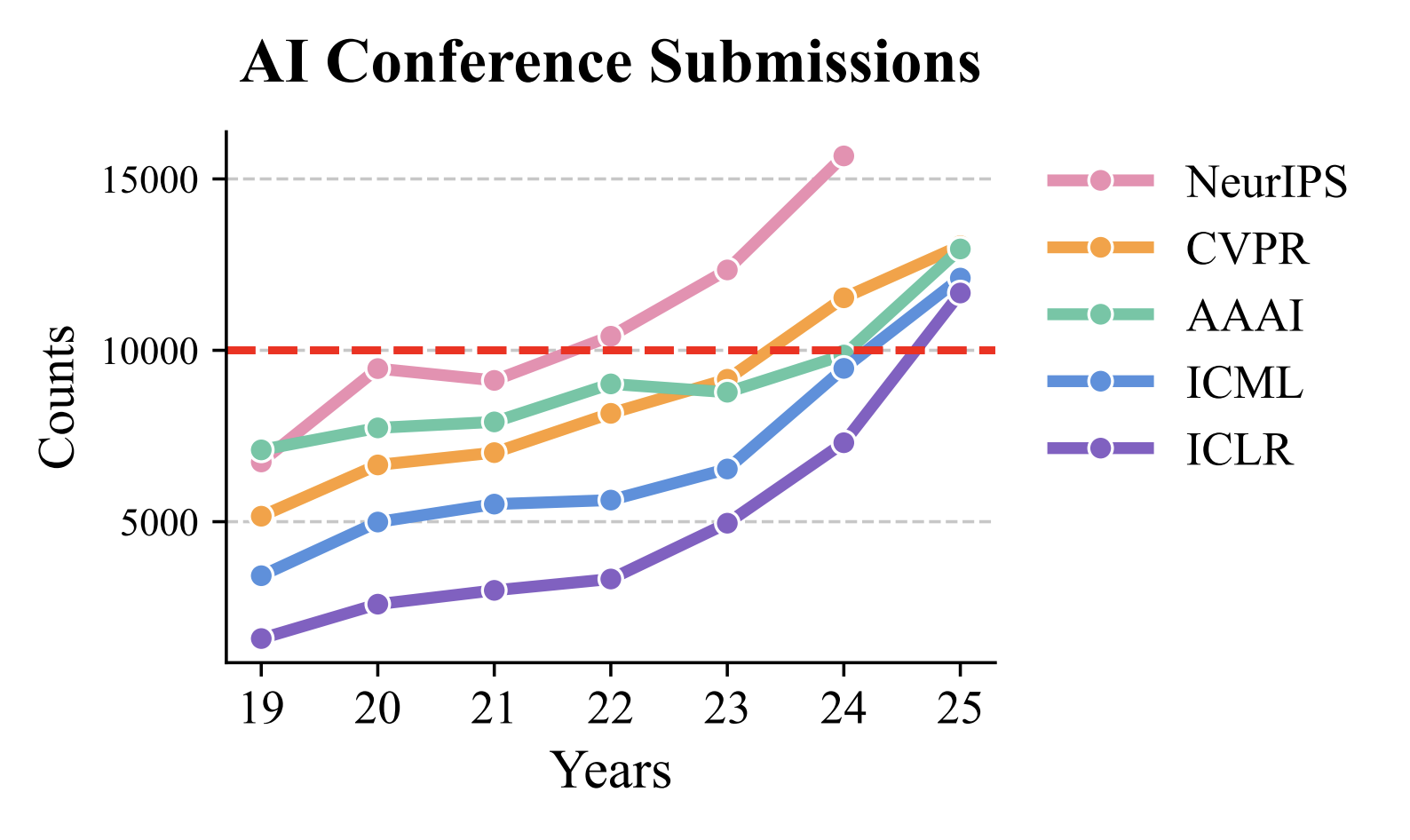 Submissions to some of the major AI conferences over the past few years.
Submissions to some of the major AI conferences over the past few years.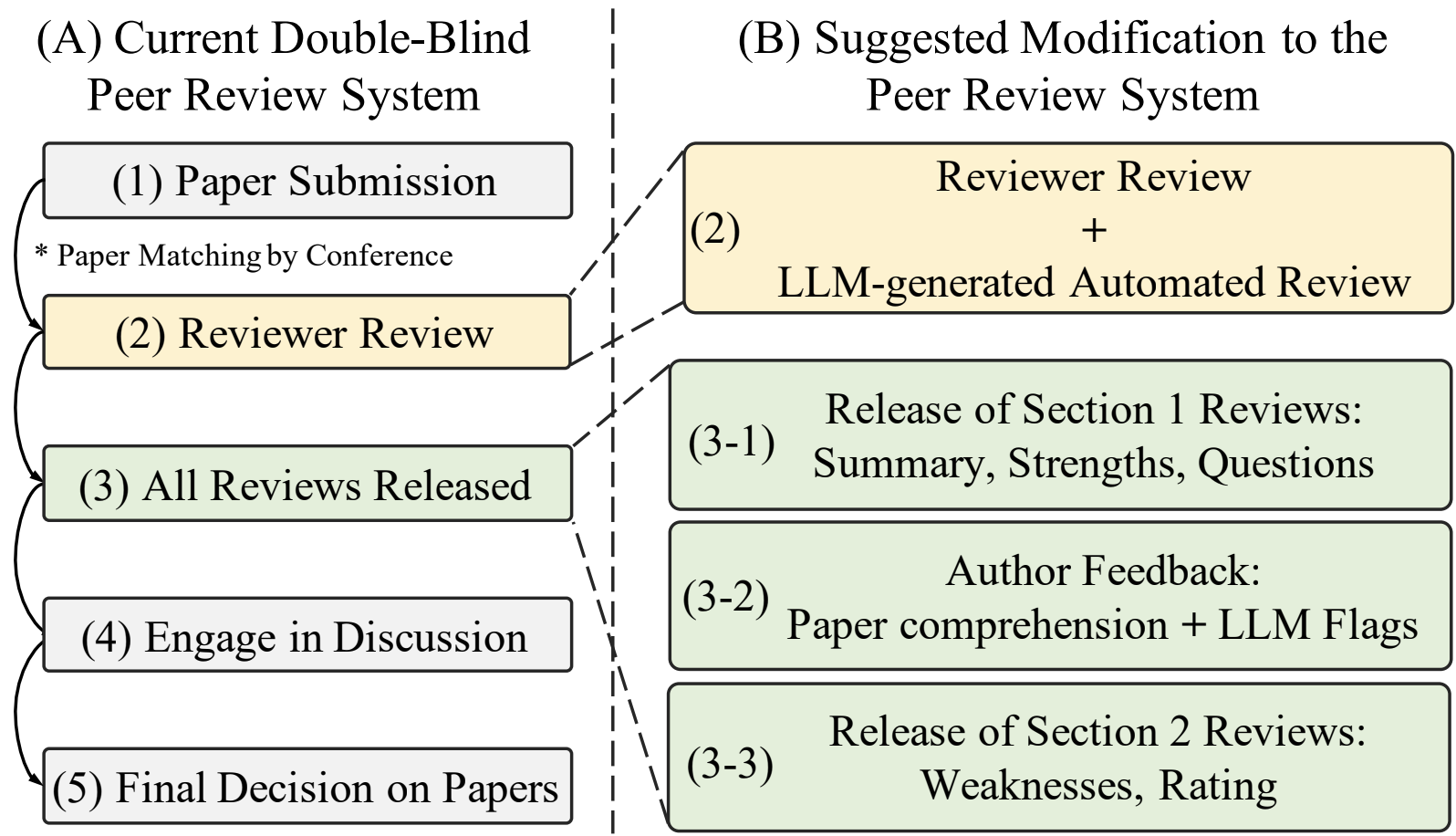 The authors’ proposed modification to the peer-review system.
The authors’ proposed modification to the peer-review system.
 RoboCup@Work League teams at the event in Brazil.
RoboCup@Work League teams at the event in Brazil. Three robots from the @Work competition in Brazil.
Three robots from the @Work competition in Brazil.







 RoboCup 2025 – Salvador, Brazil (@robocup2025)
RoboCup 2025 – Salvador, Brazil (@robocup2025)

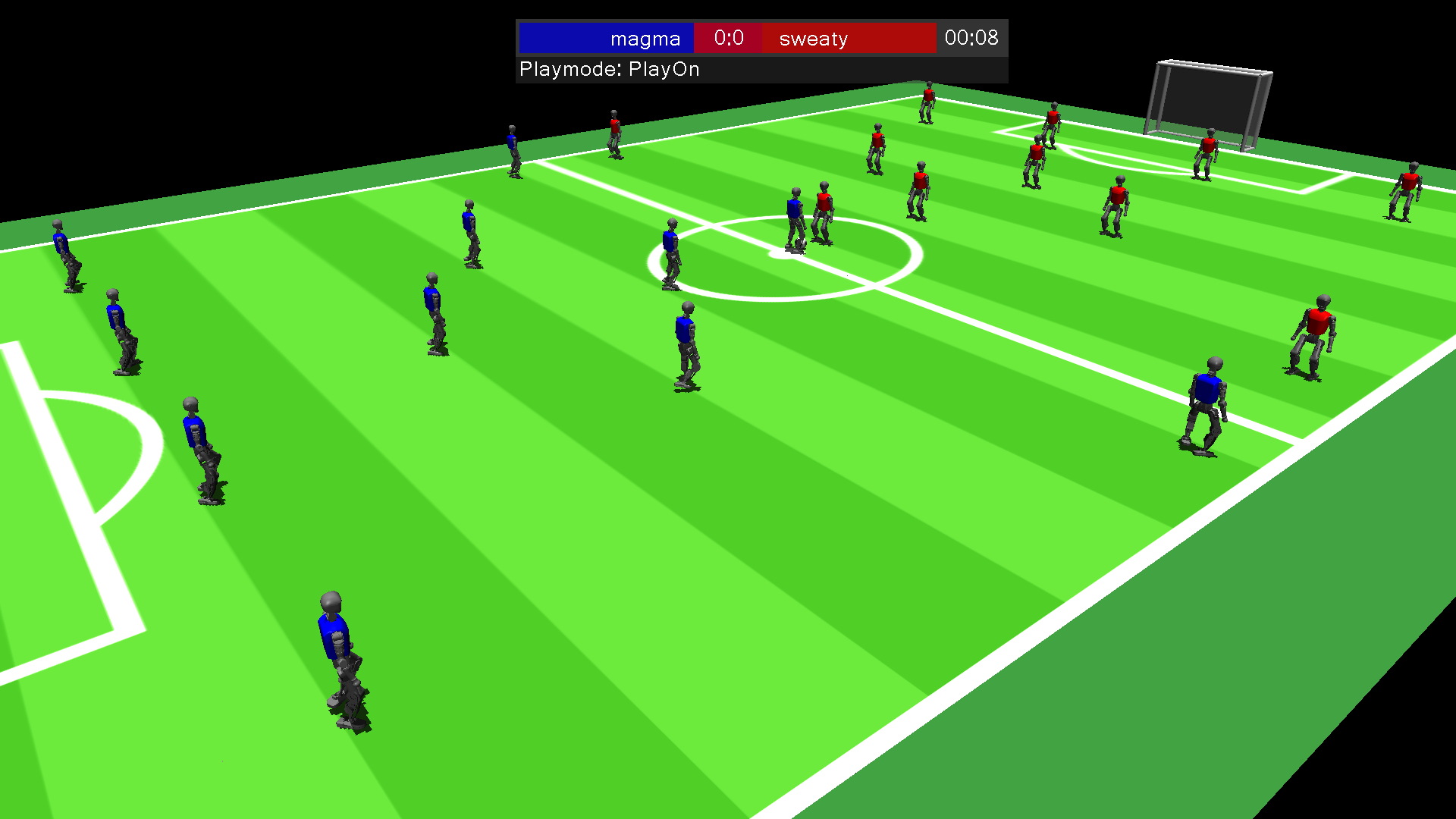 A screenshot from the new simulator that will be trialled for a special challenge at RoboCup2025.
A screenshot from the new simulator that will be trialled for a special challenge at RoboCup2025.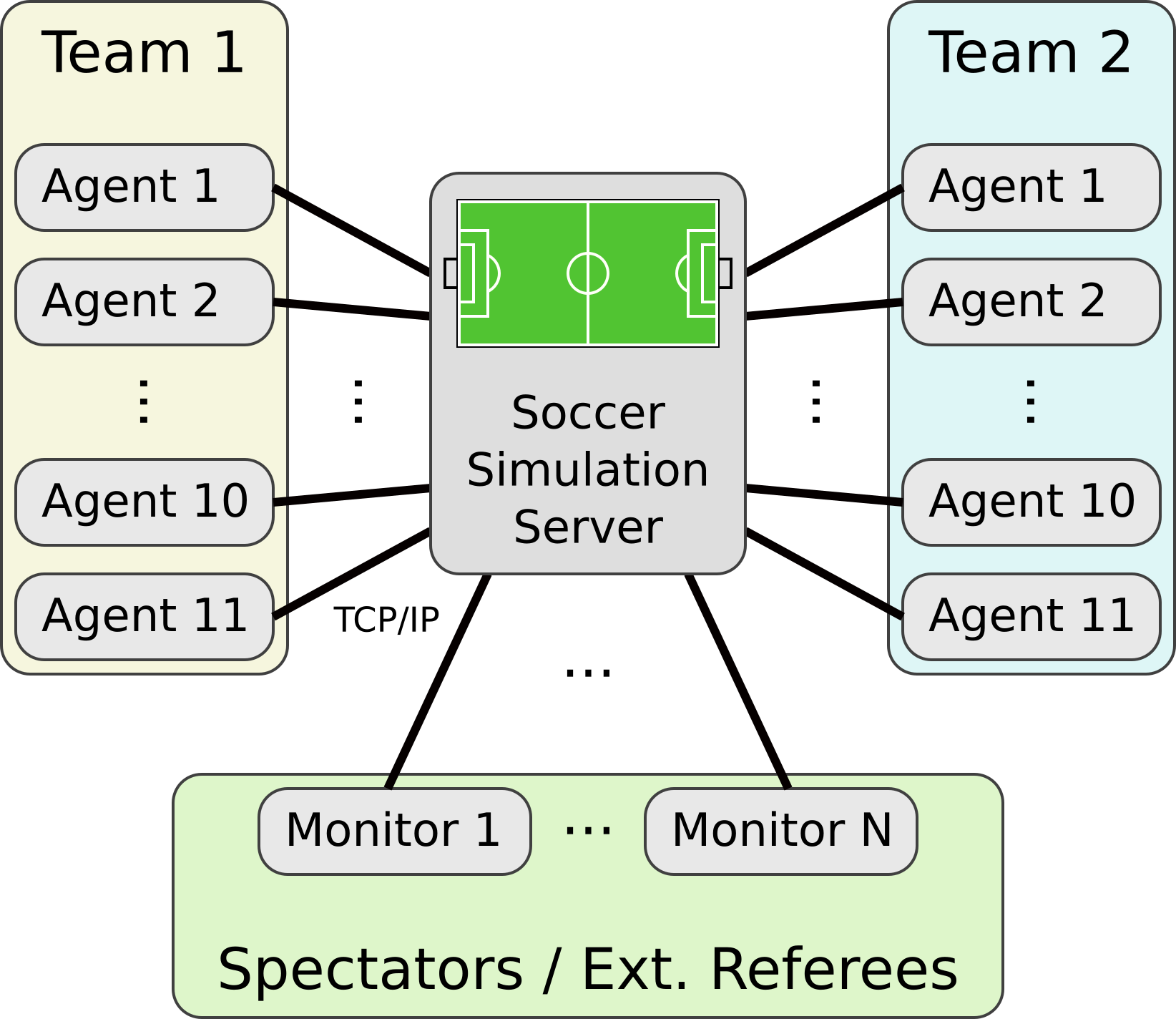 An illustration of the simulator set-up.
An illustration of the simulator set-up.

 Kick-off in a Small Size League match. Image credit: Nicolai Ommer.
Kick-off in a Small Size League match. Image credit: Nicolai Ommer.
 The RoboCupRescue arena at RoboCup2024, Eindhoven.
The RoboCupRescue arena at RoboCup2024, Eindhoven. The RoboCupRescue arena at ICRA2025 (one of the qualifying events for RoboCup2025). Credit: Adam Jacoff.
The RoboCupRescue arena at ICRA2025 (one of the qualifying events for RoboCup2025). Credit: Adam Jacoff. An example of one of the lanes (challenges) that teams tackle during competition. Credit: Adam Jacoff.
An example of one of the lanes (challenges) that teams tackle during competition. Credit: Adam Jacoff. One of the four-legged robots with wheels as feet. Image from video taken at ICRA 2025, of the robot tackling one of the test lanes. Credit: Adam Jacoff.
One of the four-legged robots with wheels as feet. Image from video taken at ICRA 2025, of the robot tackling one of the test lanes. Credit: Adam Jacoff.
 Action from RoboCupJunior Rescue at RoboCup 2024. Photo: RoboCup/Bart van Overbeeke.
Action from RoboCupJunior Rescue at RoboCup 2024. Photo: RoboCup/Bart van Overbeeke. RoboCupJunior On Stage at RoboCup 2024. Photo: RoboCup/Bart van Overbeeke.
RoboCupJunior On Stage at RoboCup 2024. Photo: RoboCup/Bart van Overbeeke. RoboCupJunior Soccer at RoboCup 2024. Photo: RoboCup/Bart van Overbeeke.
RoboCupJunior Soccer at RoboCup 2024. Photo: RoboCup/Bart van Overbeeke. RoboCupJunior Rescue at RoboCup 2024. Photo: RoboCup/Bart van Overbeeke.
RoboCupJunior Rescue at RoboCup 2024. Photo: RoboCup/Bart van Overbeeke. RoboCupJunior Rescue at RoboCup 2024. Photo: RoboCup/Bart van Overbeeke.
RoboCupJunior Rescue at RoboCup 2024. Photo: RoboCup/Bart van Overbeeke.
 The Salvador Convention Center, where RoboCup 2025 will take place.
The Salvador Convention Center, where RoboCup 2025 will take place. Marco Simões
Marco Simões Photo of participants at RoboCup 2024, which took place in Eindhoven. Photo credit: RoboCup/Bart van Overbeeke
Photo of participants at RoboCup 2024, which took place in Eindhoven. Photo credit: RoboCup/Bart van Overbeeke RoboCup @Home with Toyota HSR robots in the Domestic Standard Platform League, RoboCup 2024. Photo: RoboCup/Bart van Overbeeke.
RoboCup @Home with Toyota HSR robots in the Domestic Standard Platform League, RoboCup 2024. Photo: RoboCup/Bart van Overbeeke. Action from the semi-finals of RoboCup Soccer Humanoid League at RoboCup 2024. Photo: RoboCup/Bart van Overbeeke.
Action from the semi-finals of RoboCup Soccer Humanoid League at RoboCup 2024. Photo: RoboCup/Bart van Overbeeke.