Image editing in Gemini just got a major upgrade
Transform images in amazing new ways with updated native image editing in the Gemini app.
TL;DR
LLM-as-a-Judge systems can be fooled by confident-sounding but wrong answers, giving teams false confidence in their models. We built a human-labeled dataset and used our open-source framework syftr to systematically test judge configurations. The results? They’re in the full post. But here’s the takeaway: don’t just trust your judge — test it.
When we shifted to self-hosted open-source models for our agentic retrieval-augmented generation (RAG) framework, we were thrilled by the initial results. On tough benchmarks like FinanceBench, our systems appeared to deliver breakthrough accuracy.
That excitement lasted right up until we looked closer at how our LLM-as-a-Judge system was grading the answers.
The truth: our new judges were being fooled.
A RAG system, unable to find data to compute a financial metric, would simply explain that it couldn’t find the information.
The judge would reward this plausible-sounding explanation with full credit, concluding the system had correctly identified the absence of data. That single flaw was skewing results by 10–20% — enough to make a mediocre system look state-of-the-art.
Which raised a critical question: if you can’t trust the judge, how can you trust the results?
Your LLM judge might be lying to you, and you won’t know unless you rigorously test it. The best judge isn’t always the biggest or most expensive.
With the right data and tools, however, you can build one that’s cheaper, more accurate, and more trustworthy than gpt-4o-mini. In this research deep dive, we show you how.
The challenge we uncovered went far beyond a simple bug. Evaluating generated content is inherently nuanced, and LLM judges are prone to subtle but consequential failures.
Our initial issue was a textbook case of a judge being swayed by confident-sounding reasoning. For example, in one evaluation about a family tree, the judge concluded:
“The generated answer is relevant and correctly identifies that there’s insufficient information to determine the specific cousin… While the reference answer lists names, the generated answer’s conclusion aligns with the reasoning that the question lacks necessary data.”
In reality, the information was available — the RAG system just failed to retrieve it. The judge was fooled by the authoritative tone of the response.
Digging deeper, we found other challenges:
These failures underscore a key lesson: simply picking a powerful LLM and asking it to grade isn’t enough. Perfect agreement between judges, human or machine, is unattainable without a more rigorous approach.
To address these challenges, we needed a way to evaluate the evaluators. That meant two things:
First, we created our own dataset, now available on HuggingFace. We generated hundreds of question-answer-response triplets using a wide range of RAG systems.
Then, our team hand-labeled all 807 examples.
Every edge case was debated, and we established clear, consistent grading rules.
The process itself was eye-opening, showing just how subjective evaluation can be. In the end, our labeled dataset reflected a distribution of 37.6% failing and 62.4% passing responses.
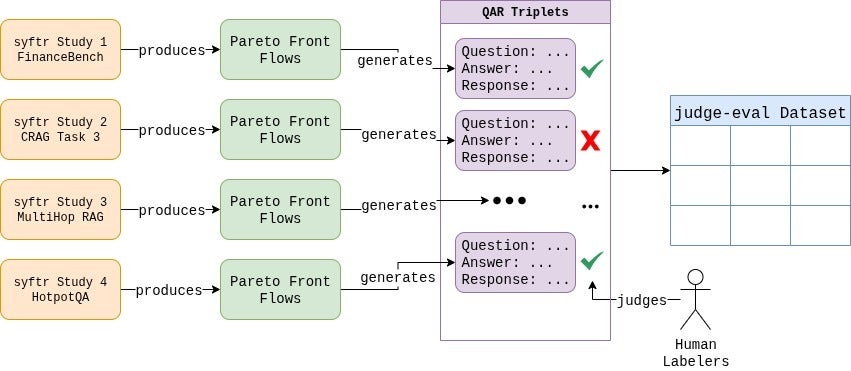
Next, we needed an engine for experimentation. That’s where our open-source framework, syftr, came in.
We extended it with a new JudgeFlow class and a configurable search space to vary LLM choice, temperature, and prompt design. This made it possible to systematically explore — and identify — the judge configurations most aligned with human judgment.
With our framework in place, we began experimenting.
Our first test focused on the Master-RM model, specifically tuned to avoid “reward hacking” by prioritizing content over reasoning phrases.
We pitted it against its base model using four prompts:
The syftr optimization results are shown below in the cost-versus-accuracy plot. Accuracy is the simple percent agreement between the judge and human evaluators, and cost is estimated based on the per-token pricing of Together.ai‘s hosting services.
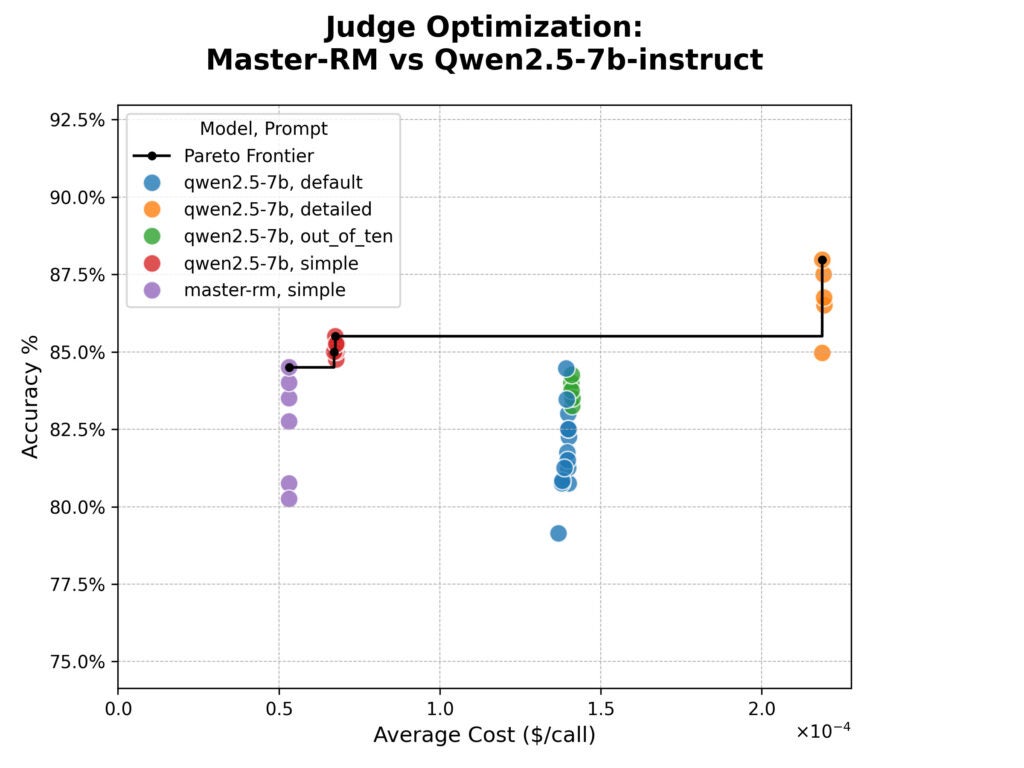
The results were surprising.
Master-RM was no more accurate than its base model and struggled with producing anything beyond the “simple” prompt response format due to its focused training.
While the model’s specialized training was effective in combating the effects of specific reasoning phrases, it did not improve overall alignment to the human judgements in our dataset.
We also saw a clear trade-off. The “detailed” prompt was the most accurate, but nearly four times as expensive in tokens.
Next, we scaled up, evaluating a cluster of large open-weight models (from Qwen, DeepSeek, Google, and NVIDIA) and testing new judge strategies:
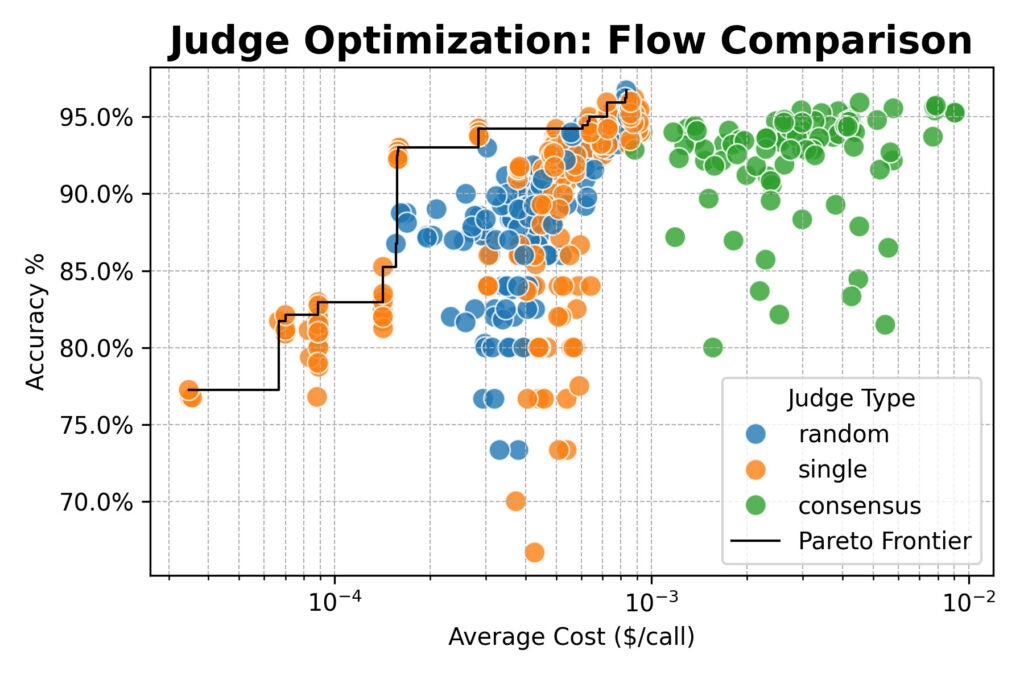
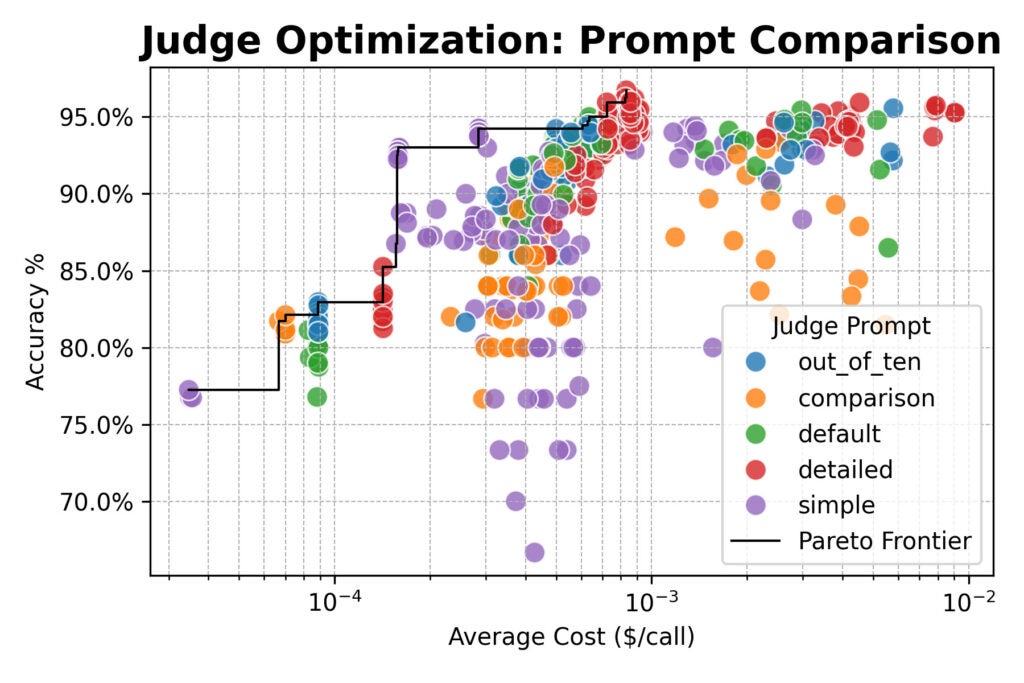
Here the results converged: consensus-based judges offered no accuracy advantage over single or random judges.
All three methods topped out around 96% agreement with human labels. Across the board, the best-performing configurations used the detailed prompt.
But there was an important exception: the simple prompt paired with a powerful open-weight model like Qwen/Qwen2.5-72B-Instruct was nearly 20× cheaper than detailed prompts, while only giving up a few percentage points of accuracy.
For a long time, our rule of thumb was: “Just use gpt-4o-mini.” It’s a common shortcut for teams looking for a reliable, off-the-shelf judge. And while gpt-4o-mini did perform well (around 93% accuracy with the default prompt), our experiments revealed its limits. It’s just one point on a much broader trade-off curve.
A systematic approach gives you a menu of optimized options instead of a single default:
By optimizing across accuracy, cost, and latency, you can make informed choices tailored to the needs of each project — instead of betting everything on a one-size-fits-all judge.
Whether you use our framework or not, our findings can help you build more reliable evaluation systems:
Our journey began with a troubling discovery: instead of following the rubric, our LLM judges were being swayed by long, plausible-sounding refusals.
By treating evaluation as a rigorous engineering problem, we moved from doubt to confidence. We gained a clear, data-driven view of the trade-offs between accuracy, cost, and speed in LLM-as-a-Judge systems.
More data means better choices.
We hope our work and our open-source dataset encourage you to take a closer look at your own evaluation pipelines. The “best” configuration will always depend on your specific needs, but you no longer have to guess.
Ready to build more trustworthy evaluations? Explore our work in syftr and start judging your judges.
The post Judging judges: Building trustworthy LLM evaluations appeared first on DataRobot.
 “One of the dreams I had as a kid was about the first day of school, and being able to build and be creative, and it was the happiest day of my life. And at MIT, I felt like that dream became reality,” says Ballesteros. Credit: Ryan A Lannom, Jet Propulsion Laboratory.
“One of the dreams I had as a kid was about the first day of school, and being able to build and be creative, and it was the happiest day of my life. And at MIT, I felt like that dream became reality,” says Ballesteros. Credit: Ryan A Lannom, Jet Propulsion Laboratory.
By Jennifer Chu
Growing up in the suburban town of Spring, Texas, just outside of Houston, Erik Ballesteros couldn’t help but be drawn in by the possibilities for humans in space.
It was the early 2000s, and NASA’s space shuttle program was the main transport for astronauts to the International Space Station (ISS). Ballesteros’ hometown was less than an hour from Johnson Space Center (JSC), where NASA’s mission control center and astronaut training facility are based. And as often as they could, he and his family would drive to JSC to check out the center’s public exhibits and presentations on human space exploration.
For Ballesteros, the highlight of these visits was always the tram tour, which brings visitors to JSC’s Astronaut Training Facility. There, the public can watch astronauts test out spaceflight prototypes and practice various operations in preparation for living and working on the International Space Station.
“It was a really inspiring place to be, and sometimes we would meet astronauts when they were doing signings,” he recalls. “I’d always see the gates where the astronauts would go back into the training facility, and I would think: One day I’ll be on the other side of that gate.”
Today, Ballesteros is a PhD student in mechanical engineering at MIT, and has already made good on his childhood goal. Before coming to MIT, he interned on multiple projects at JSC, working in the training facility to help test new spacesuit materials, portable life support systems, and a propulsion system for a prototype Mars rocket. He also helped train astronauts to operate the ISS’ emergency response systems.
Those early experiences steered him to MIT, where he hopes to make a more direct impact on human spaceflight. He and his advisor, Harry Asada, are building a system that will quite literally provide helping hands to future astronauts. The system, dubbed SuperLimbs, consists of a pair of wearable robotic arms that extend out from a backpack, similar to the fictional Inspector Gadget, or Doctor Octopus (“Doc Ock,” to comic book fans). Ballesteros and Asada are designing the robotic arms to be strong enough to lift an astronaut back up if they fall. The arms could also crab-walk around a spacecraft’s exterior as an astronaut inspects or makes repairs.
Ballesteros is collaborating with engineers at the NASA Jet Propulsion Laboratory to refine the design, which he plans to introduce to astronauts at JSC in the next year or two, for practical testing and user feedback. He says his time at MIT has helped him make connections across academia and in industry that have fueled his life and work.
“Success isn’t built by the actions of one, but rather it’s built on the shoulders of many,” Ballesteros says. “Connections — ones that you not just have, but maintain — are so vital to being able to open new doors and keep great ones open.”
Getting a jumpstart
Ballesteros didn’t always seek out those connections. As a kid, he counted down the minutes until the end of school, when he could go home to play video games and watch movies, “Star Wars” being a favorite. He also loved to create and had a talent for cosplay, tailoring intricate, life-like costumes inspired by cartoon and movie characters.
In high school, he took an introductory class in engineering that challenged students to build robots from kits, that they would then pit against each other, BattleBots-style. Ballesteros built a robotic ball that moved by shifting an internal weight, similar to Star Wars’ fictional, sphere-shaped BB-8.
“It was a good introduction, and I remember thinking, this engineering thing could be fun,” he says.
After graduating high school, Ballesteros attended the University of Texas at Austin, where he pursued a bachelor’s degree in aerospace engineering. What would typically be a four-year degree stretched into an eight-year period during which Ballesteros combined college with multiple work experiences, taking on internships at NASA and elsewhere.
In 2013, he interned at Lockheed Martin, where he contributed to various aspects of jet engine development. That experience unlocked a number of other aerospace opportunities. After a stint at NASA’s Kennedy Space Center, he went on to Johnson Space Center, where, as part of a co-op program called Pathways, he returned every spring or summer over the next five years, to intern in various departments across the center.
While the time at JSC gave him a huge amount of practical engineering experience, Ballesteros still wasn’t sure if it was the right fit. Along with his childhood fascination with astronauts and space, he had always loved cinema and the special effects that forged them. In 2018, he took a year off from the NASA Pathways program to intern at Disney, where he spent the spring semester working as a safety engineer, performing safety checks on Disney rides and attractions.
During this time, he got to know a few people in Imagineering — the research and development group that creates, designs, and builds rides, theme parks, and attractions. That summer, the group took him on as an intern, and he worked on the animatronics for upcoming rides, which involved translating certain scenes in a Disney movie into practical, safe, and functional scenes in an attraction.
“In animation, a lot of things they do are fantastical, and it was our job to find a way to make them real,” says Ballesteros, who loved every moment of the experience and hoped to be hired as an Imagineer after the internship came to an end. But he had one year left in his undergraduate degree and had to move on.
After graduating from UT Austin in December 2019, Ballesteros accepted a position at NASA’s Jet Propulsion Laboratory in Pasadena, California. He started at JPL in February of 2020, working on some last adjustments to the Mars Perseverance rover. After a few months during which JPL shifted to remote work during the Covid pandemic, Ballesteros was assigned to a project to develop a self-diagnosing spacecraft monitoring system. While working with that team, he met an engineer who was a former lecturer at MIT. As a practical suggestion, she nudged Ballesteros to consider pursuing a master’s degree, to add more value to his CV.
“She opened up the idea of going to grad school, which I hadn’t ever considered,” he says.
Full circle
In 2021, Ballesteros arrived at MIT to begin a master’s program in mechanical engineering. In interviewing with potential advisors, he immediately hit it off with Harry Asada, the Ford Professor of Enginering and director of the d’Arbeloff Laboratory for Information Systems and Technology. Years ago, Asada had pitched JPL an idea for wearable robotic arms to aid astronauts, which they quickly turned down. But Asada held onto the idea, and proposed that Ballesteros take it on as a feasibility study for his master’s thesis.
The project would require bringing a seemingly sci-fi idea into practical, functional form, for use by astronauts in future space missions. For Ballesteros, it was the perfect challenge. SuperLimbs became the focus of his master’s degree, which he earned in 2023. His initial plan was to return to industry, degree in hand. But he chose to stay at MIT to pursue a PhD, so that he could continue his work with SuperLimbs in an environment where he felt free to explore and try new things.
“MIT is like nerd Hogwarts,” he says. “One of the dreams I had as a kid was about the first day of school, and being able to build and be creative, and it was the happiest day of my life. And at MIT, I felt like that dream became reality.”
Ballesteros and Asada are now further developing SuperLimbs. The team recently re-pitched the idea to engineers at JPL, who reconsidered, and have since struck up a partnership to help test and refine the robot. In the next year or two, Ballesteros hopes to bring a fully functional, wearable design to Johnson Space Center, where astronauts can test it out in space-simulated settings.
In addition to his formal graduate work, Ballesteros has found a way to have a bit of Imagineer-like fun. He is a member of the MIT Robotics Team, which designs, builds, and runs robots in various competitions and challenges. Within this club, Ballesteros has formed a sub-club of sorts, called the Droid Builders, that aim to build animatronic droids from popular movies and franchises.
“I thought I could use what I learned from Imagineering and teach undergrads how to build robots from the ground up,” he says. “Now we’re building a full-scale WALL-E that could be fully autonomous. It’s cool to see everything come full circle.”
While AI coders push the tech to ever-loftier heights, one thing we already know for sure is AI can write emails at the world-class level — in a flash.
Yes, long-term, AI may one day trigger a world in which AI-powered machines do all the work as we navigate a world resplendent with abundance.

But in the here and now, AI is already saving businesses and organizations serious coin in terms of slashing time spent on email, synthesizing ideas in new ways, boosting morale and ending email drudgery we know it.
Essentially: There are all sorts of reasons for businesses and organizations to bring-in bleeding edge AI tools like ChatGPT, Gemini, Anthropic, Claude and similar to take over the heavy lifting when it comes to email.
Here are the top ten:
*Expect Real Time Savings: 68,000 employees at Vodafone are saving an average of three hours each week on emails after switching to Copilot – a Microsoft chatbot that offers ChatGPT as its primary AI engine.
Workers say the gains come from the AI’s ability to quickly draft emails, dig-up information, and more. Nearly 90% of workers in Vodafone’s pilot trial of Microsoft Copilot rated the new tool as beneficial. And 60% said that along with speed, AI-assisted email also improved their overall work performance.
*Be More Efficient With Every Email: Twenty companies that have adopted AI-powered email across a wide spectrum of departments – including finance, HR and operations – say their workers are able to shave minutes off every, single email they auto-write with AI.
Managers especially love AI’s knack for just the right tone, with 47% saying the emails auto-written by AI sound both more professional and less robotic – and forever dump in the trash-bin of history the line, “per my last email.”
*Generate First-Drafts in an Eyeblink: 90% of workers at Amadeus – an IT services provider for the travel industry – find they’re able to cut 30-60 minutes off the first draft of important emails by using AI writing powered by Copilot, which uses ChatGPT as its primary AI engine.
In fact, one Amadeus user reports she’s able to auto-write a working draft for any email in an average of 5-10 minutes. And another says he was able to reduce his nearly 1,000 email queue of unread messages to less than 100 by turning over first-draft writing of emails to AI.
*Expect a Much Deeper Frame-of-Reference With Every Email: Gmail’s AI-assisted ‘Smart Replies’ now goes beyond simply reading the email you’re responding to when auto-writing a reply.
Instead, the AI tool has been enhanced to also draw information and insight for its reply from related emails in your inbox, as well as related data – such as PDFs and docs – that you have stored in your Google Drive.
*Email Effortlessly in Multiple Languages: While English-to-another-language auto-translation has been with us for a number of years now, Google has made it even easier to use by building the function into Gmail’s ‘Help Me Write.’
Now, once you’re finished using Help Me Write to auto-write an email, select its tone and edit it for clarity, word-length or similar, you can use the same AI tool to auto-translate the email into Italian, French, German, Spanish and Portuguese.
*Get More Email Done on Mobile: Google has also made it easier to use AI writing on your smartphone with its next generation of ‘Smart Replies.’
Going beyond auto-generating quick, one-line replies to your emails, Smart Replies can now read multiple threads before responding to an email and send longer, more context aware emails on your behalf – often with just a few taps.
*Auto-Synthesize Sales Notes and Buyer Intent in Sales Email Replies: AI sales email tool Outreach helps teams come up with the perfect email at any moment. Sales reps choose buyer cues and sales assets they want the AI to work with — and seconds later, a draft email emerges offering the optimum combination of all.
The overarching approach: Once sales reps have a working draft, they can quickly tweak and further humanize the copy to create an ideal message.
*Auto-Write More Empathetic, More Human-Sounding Emails: Allstate has grown so enamored with AI, nearly all of its 50,000 customer service emails are now drafted with the tech – helping free-up 23,000 claims reps to do higher-end tasks.
The result: The insurer says the AI emails come across as more empathetic – even though they’re written by a machine. Plus, they also feature much less jargon.
In a phrase: So long clunky abbreviations, insider gobbledygook and toneless prose.
*End Email Drudgery As We Know It: Customer service staff at Zendesk – a customer support software provider – report that since AI has been tasked to handle common requests coming in via email, they’re able to spend more time handling more complex cases that require judgment and caring.
All told, early pilots found that AI can handle up to 60% of incoming customer emails at Zendesk. And there’s been a 22% reduction in ‘ticket fatigue,’ or the human burnout triggered by replying to hundreds-upon-hundreds of the same kind of emails, week after week.

*Boost Morale: 20,000 U.K. civil servants in a three-month trial of Copilot – a Microsoft chatbot powered primarily by ChatGPT – report their moods are a lot brighter, now that AI has taken on a huge bulk of their email and related chores.
Specifically, more than 70% of those surveyed said Copilot eliminated a significant swath of workday drudgery. And more than 80% say they’ll never go back to hand-hewn messaging.

Share a Link: Please consider sharing a link to https://RobotWritersAI.com from your blog, social media post, publication or emails. More links leading to RobotWritersAI.com helps everyone interested in AI-generated writing.
–Joe Dysart is editor of RobotWritersAI.com and a tech journalist with 20+ years experience. His work has appeared in 150+ publications, including The New York Times and the Financial Times of London.
The post Bringing in ChatGPT for Email appeared first on Robot Writers AI.
This past week in New York, Google didn’t just launch a new set of phones; it laid out its most cohesive and aggressive vision yet for an AI-powered future, presenting a direct and compelling challenge to Apple’s dominance. The event […]
The post Google’s AI-Powered Ambition: A New Pixel Ecosystem Takes Aim at Apple appeared first on TechSpective.