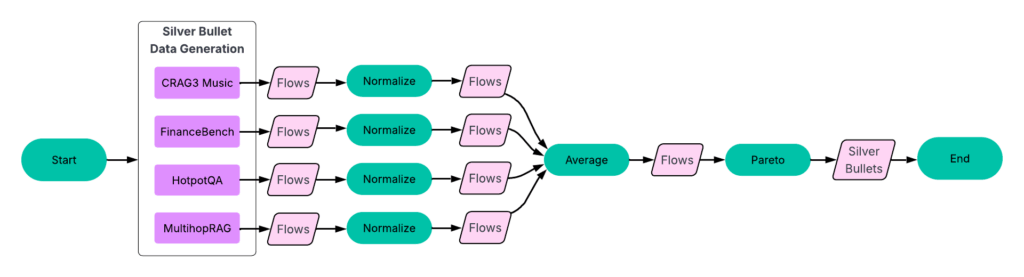
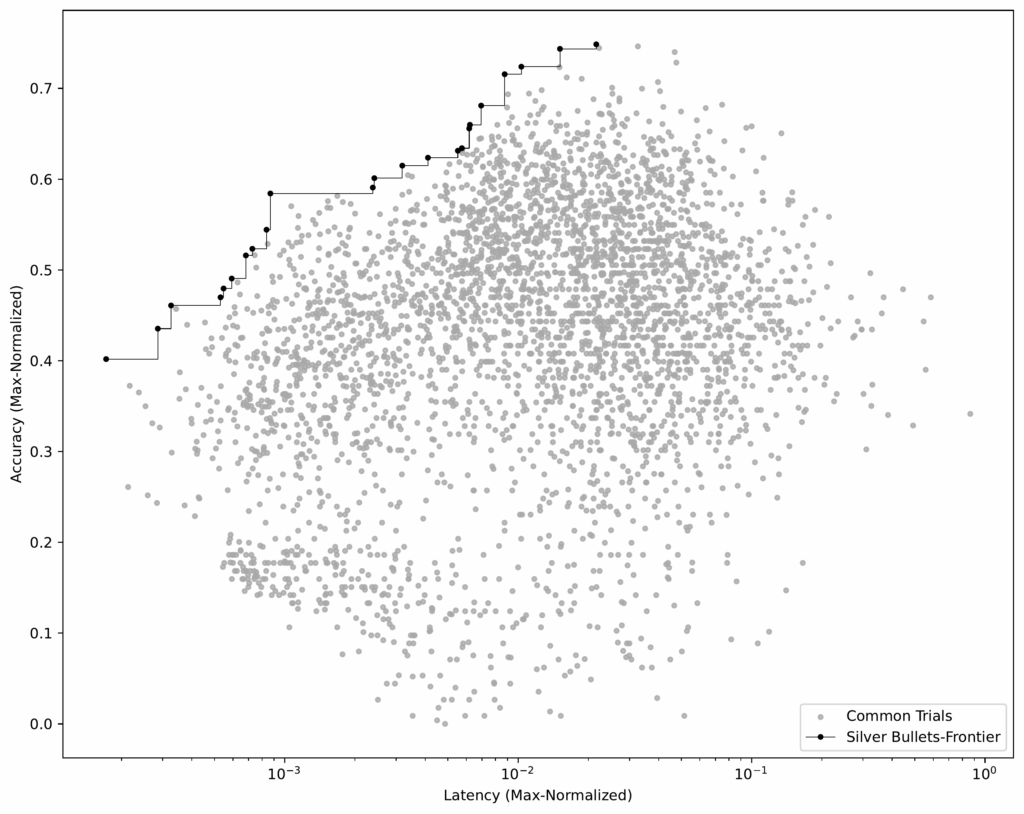
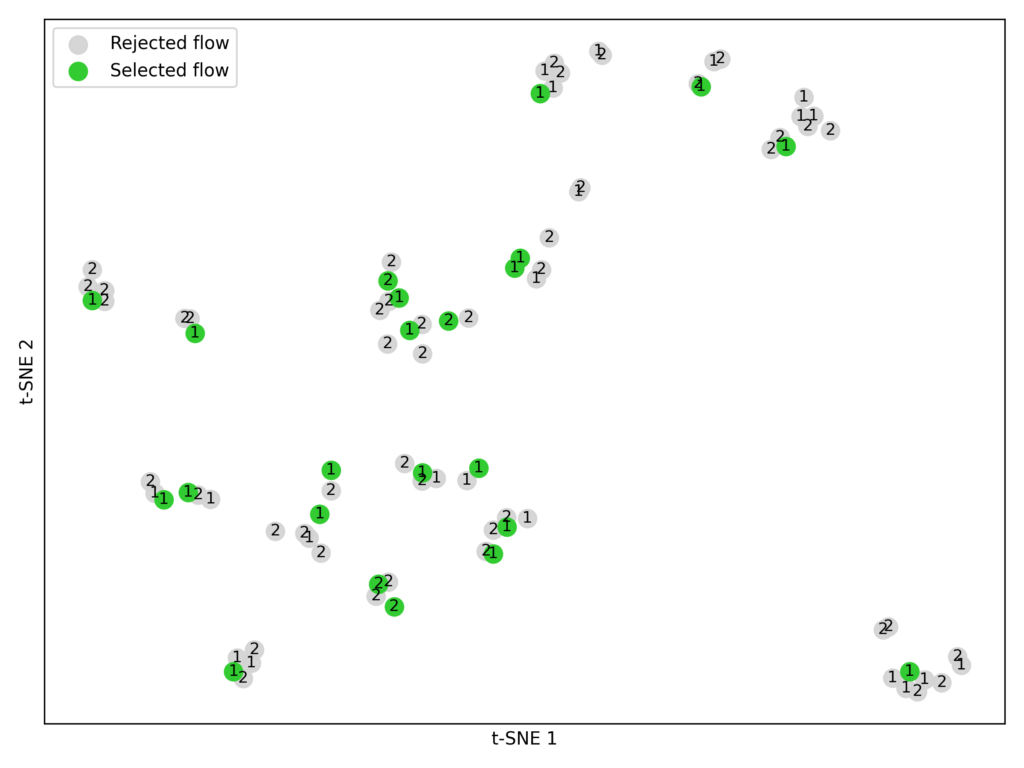
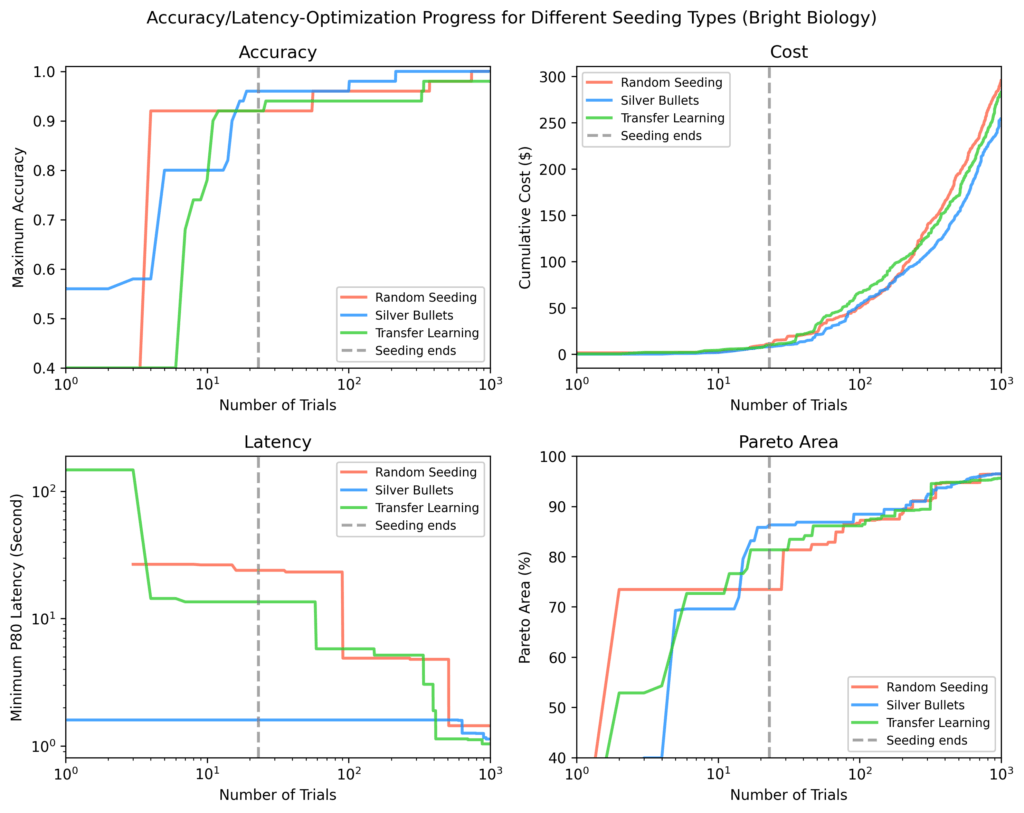
In this interview series, we’re meeting some of the AAAI/SIGAI Doctoral Consortium participants to find out more about their research. In this latest interview, Haimin Hu tells us about his research on the algorithmic foundations of human-centered autonomy and his plans for future projects, and gives some advice for PhD students looking to take the next step in their career.
Could you give us an overview of the research you carried out during your PhD?
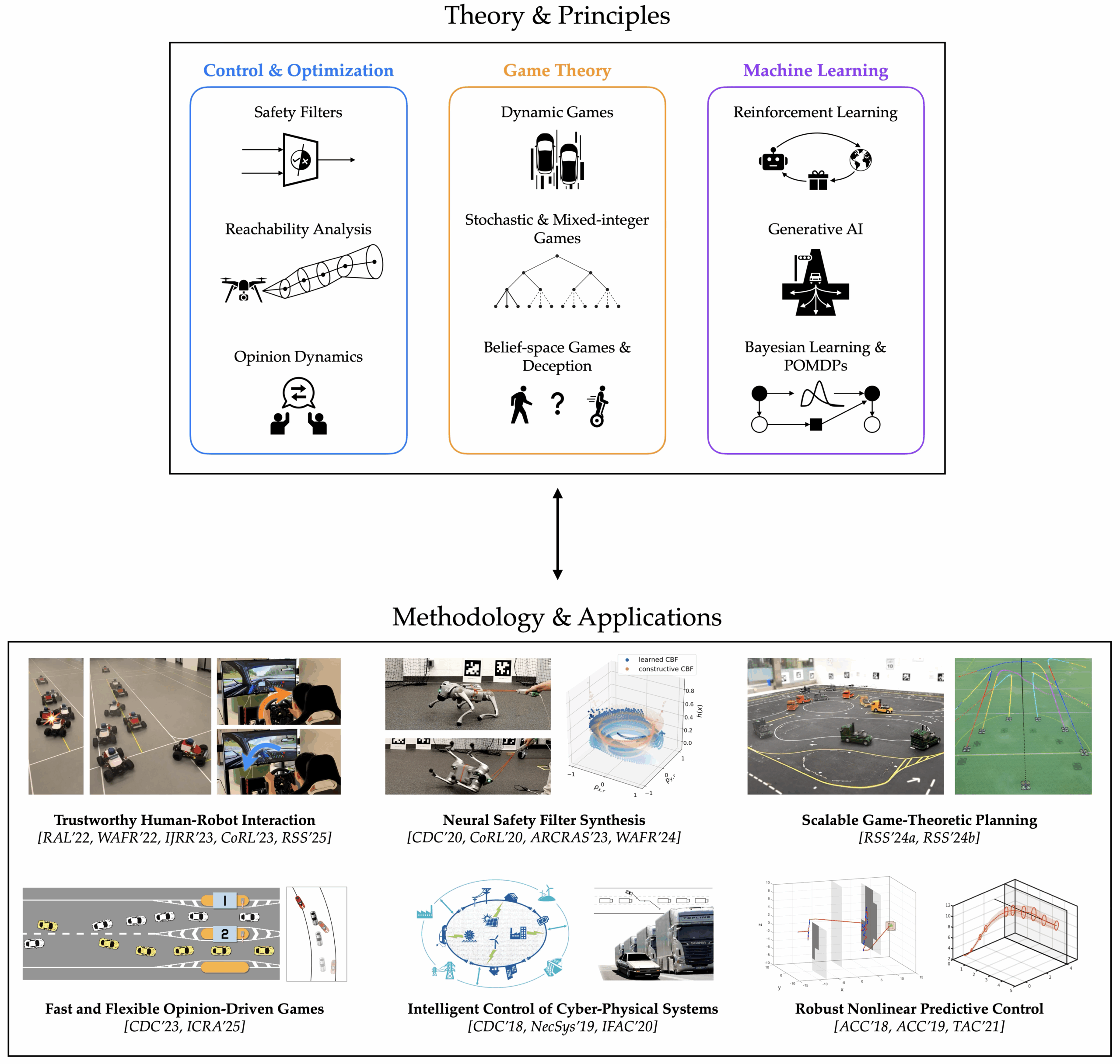
My PhD research, conducted under the supervision of Professor Jaime Fernández Fisac in the Princeton Safe Robotics Lab, focuses on the algorithmic foundations of human-centered autonomy. By integrating dynamic game theory with machine learning and safety-critical control, my work aims to ensure autonomous systems, from self-driving vehicles to drones and quadrupedal robots, are performant, verifiable, and trustworthy when deployed in human-populated space. The core principle of my PhD research is to plan robots’ motion in the joint space of both physical and information states, actively ensuring safety as they navigate uncertain, changing environments and interact with humans. Its key contribution is a unified algorithmic framework—backed by game theory—that allows robots to safely interact with their human peers, adapt to human preferences and goals, and even help humans refine their skills. Specifically, my PhD work contributes to the following areas in human-centered autonomy and multi-agent systems:
- Trustworthy human–robot interaction: Planning safe and efficient robot trajectories by closing the computation loop between physical human-robot interaction and runtime learning that reduces the robot’s uncertainty about the human.
- Verifiable neural safety analysis for complex robotic systems: Learning robust neural controllers for robots with high-dimensional dynamics; guaranteeing their training-time convergence and deployment-time safety.
- Scalable interactive planning under uncertainty: Synthesizing game-theoretic control policies for complex and uncertain human–robot systems at scale.
Was there a project (or aspect of your research) that was particularly interesting?
Safety in human-robot interaction is especially difficult to define, because it hinges on an, I’d say, almost unanswerable question: How safe is safe enough when humans might behave in arbitrary ways? To give a concrete example: Is it sufficient if an autonomous vehicle can avoid hitting a fallen cyclist 99.9% of the time? What if this rate can only be achieved by the vehicle always stopping and waiting for the human to move out of the way?
I would argue that, for trustworthy deployment of robots in human-populated space, we need to complement standard statistical methods with clear-cut robust safety assurances under a vetted set of operation conditions as well established as those of bridges, power plants, and elevators. We need runtime learning to minimize the robot’s performance loss caused by safety-enforcing maneuvers; this calls for algorithms that can reduce the robot’s inherent uncertainty induced by its human peers, for example, their intent (does a human driver want to merge, cut behind, or stay in the lane?) or response (if the robot comes closer, how will the human react?). We need to close the loop between the robot’s learning and decision-making so that it can optimize efficiency by anticipating how its ongoing interaction with the human may affect the evolving uncertainty, and ultimately, its long-term performance.
What made you want to study AI, and the area of human-centered robotic systems in particular?
I’ve been fascinated by robotics and intelligent systems since childhood, when I’d spend entire days watching sci-fi anime like Mobile Suit Gundam, Neon Genesis Evangelion, or Future GPX Cyber Formula. What captivated me wasn’t just the futuristic technology, but the vision of AI as a true partner—augmenting human abilities rather than replacing them. Cyber Formula in particular planted the idea of human-AI co-evolution in my mind: an AI co-pilot that not only helps a human driver navigate high-speed, high-stakes environments, but also adapts to the driver’s style over time, ultimately making the human a better racer and deepening mutual trust along the way. Today, during my collaboration with Toyota Research Institute (TRI), I work on human-centered robotics systems that embody this principle: designing AI systems that collaborate with people in dynamic, safety-critical settings by rapidly aligning with human intent through multimodal inputs, from physical assistance to visual cues and language feedback, bringing to life the very ideas that once lived in my childhood imagination.
You’ve landed a faculty position at Johns Hopkins University (JHU) – congratulations! Could you talk a bit about the process of job searching, and perhaps share some advice and insights for PhD students who may be at a similar stage in their career?
The job search was definitely intense but also deeply rewarding. My advice to PhD students: start thinking early about the kind of long-term impact you want to make, and act early on your application package and job talk. Also, make sure you talk to people, especially your senior colleagues and peers on the job market. I personally benefited a lot from the following resources:
- The Professor Is In
- Faculty Application Advice by Professor Sylvia Herbert
- Tips for Computer Science Faculty Applications by Professor Yisong Yue
- Research Statement by Professor Tom Silver
- Autonomy Talks (examples of great talks in broad areas of autonomy and AI)
Do you have an idea of the research projects you’ll be working on at JHU?
I wish to help create a future where humans can unquestionably embrace the presence of robots around them. Towards this vision, my lab at JHU will investigate the following topics:
- Uncertainty-aware interactive motion planning: How can robots plan safe and efficient motion by accounting for their evolving uncertainty, as well as their ability to reduce it through future interaction, sensing, communication, and learning?
- Human–AI co-evolution and co-adaptation: How can embodied AI systems learn from human teammates while helping them refine existing skills and acquire new ones in a safe, personalized manner?
- Safe human-compatible autonomy: How can autonomous systems ensure prescribed safety while remaining aligned with human values and attuned to human cognitive limitations?
- Scalable and generalizable strategic decision-making: How can multi-robot systems make safe, coordinated decisions in dynamic, human-populated environments?

How was the experience attending the AAAI Doctoral Consortium?
I had the privilege of attending the 2025 AAAI Doctoral Consortium, and it was an incredibly valuable experience. I’m especially grateful to the organizers for curating such a thoughtful and supportive environment for early-career researchers. The highlight for me was the mentoring session with Dr Ming Yin (postdoc at Princeton, now faculty at Georgia Tech CSE), whose insights on navigating the uncertain and competitive job market were both encouraging and eye-opening.
Could you tell us an interesting (non-AI related) fact about you?
I am passionate about skiing. I learned to ski primarily by vision-based imitation learning from a chairlift, though I’m definitely paying the price now for poor generalization! One day, I hope to build an exoskeleton that teaches me to ski better while keeping me safe on the double black diamonds.
About Haimin

|
Haimin Hu is an incoming Assistant Professor of Computer Science at Johns Hopkins University, where he is also a member of the Data Science and AI Institute, the Institute for Assured Autonomy, and the Laboratory for Computational Sensing and Robotics. His research focuses on the algorithmic foundations of human-centered autonomy. He has received several awards and recognitions, including a 2025 Robotics: Science and Systems Pioneer, a 2025 Cyber-Physical Systems Rising Star, and a 2024 Human-Robot Interaction Pioneer. Additionally, he has served as an Associate Editor for IEEE Robotics and Automation Letters since his fourth year as a PhD student. He obtained a PhD in Electrical and Computer Engineering from Princeton University in 2025, an MSE in Electrical Engineering from the University of Pennsylvania in 2020, and a BE in Electronic and Information Engineering from ShanghaiTech University in 2018. |