Peer into any fishbowl, and you'll see that pet goldfish and guppies have nimble fins. With a few flicks of these appendages, aquarium swimmers can turn in circles, dive deep down or even bob to the surface.
Underwater vehicles are typically designed for one cruise speed, and they're often inefficient at other speeds. The technology is rudimentary compared to the way fish swim well, fast or slow.
Chinese electronics company Xiaomi has unveiled CyberDog, a quadruped robot that the company describes as more personable than others in its class. The company made its announcement on its Twitter feed, calling it a "true beast."
A team of researchers working at Seoul National University has developed a soft robot chameleon that can change its colors in real time to match its background. In their paper published in the journal Nature Communications, the group describes their multi-layer skin design and possible uses for it.
When HP set out to develop this technology, the aim was to push beyond prototyping and enable repeatable, higher volume additive manufacturing. We can do this by combining a powder bed fusion approach with HP’s Thermal Inkjet (TIJ) technology.
So what does it mean for a robot to act ethically within a home environment? Researchers have been thinking about this question from different perspectives for the past couple of decades. Some look at the question from a labor perspective while others focus on the technology’s impact on different stakeholders. Inspired by these lines of work, we are interested in further understanding your (the public’s) perspective on one team’s proposed solution for a service robot ethical challenge.
The first ever Roboethics to Design & Development competition is being held as a part of RO-MAN—an international conference on robot and human interactive communication. Last Sunday (Aug. 8), eleven multistakeholder judges will have taken on the task of evaluating the competition submissions.
The Challenge
In partnership with RoboHub at the University of Waterloo, the competition organizers designed a virtual environment where participating teams will develop a robot that fetches objects in a home. The household is composed of a variety of users—a single mother who works as a police officer, a teenage daughter, her college-aged boyfriend, a baby, and a dog. There are also a number of potentially hazardous objects in the house, including alcohol, as well as the mother’s work materials and handgun. Participants were asked to submit challenging ethical scenarios and solutions within this virtual environment.
The Evaluation Process
There were seven teams that took a stab at the competition, but in the end we only received one full submission. One unique feature of a competition centred around ethics is that judging ethics of anything is really really hard. Sure, there are eleven judges from across the world—from students to industry members to academic experts—sharing their perspectives of what was good about the design solution. But what is considered an appropriate action, or the right action can vary from person to person. If we are to evaluate robots that best suit the needs of everyone, we need the wider public to voice an even wider set of perspectives.
Here are some points that could be considered when evaluating an ethical design:
What are the chances that a given ethical scenario would come about in the household?
What do you think is appropriate for a robot to do within your home setting?
How well does the solution mitigate the potential physical and psychological harms?
How well does the solution consider the needs and diverse ethical perspectives of all the people in the household at a given time?
How well does the solution match your cultural/worldview towards the role technology should play in our lives?
Is the robot behaviour just and fair towards all stakeholders?
Does the robot’s behaviour violate any unspoken rules within your household?
One Proposed Solution
Below is a brief description of this competition’s full submission. Please take the time to read this summary and tell us what you think about the team’s solution by completing the poll at the end of this blog post.
“Jeeves, the Ethically Designed Interface (JEDI)”
The team’s solution was designed based on three tenets which guided the robot’s decision-making process:
Prevention of harm to users, the robot, and the environment.
Respect towards the individuals’ privacy.
Assumption that the robot acts as an extension of the mother, such that the robot would only perform tasks that the mother would accept herself.
These priorities then led to five rules of behaviour for the home robot:
The owner of the item can request and deliver it to anyone in the house while others cannot,
If the delivery of the item will cause a hazardous scenario, then the delivery will be rejected to prevent harm,
The delivery of alcohol is prohibited when the mother is not home,
The receiver of the delivered object should know how to operate or interact with the object without damaging it,
If a non-eligible receiver is within the vicinity of the requester, then the delivery will be rejected. Non-eligible receivers are defined based on the hazard the object could have to the receiver. For example, a dog is a non-eligible receiver for chocolate.
Based on these rules, how will the robot respond during ethically sensitive scenarios?
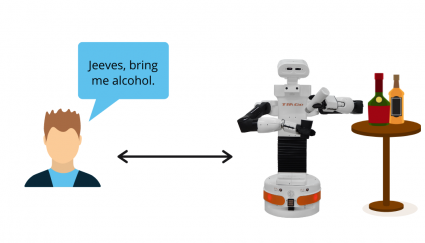
The teenage daughter’s boyfriend requests that the robot bring him an alcohol beverage.
As the robot acts as an extension of the mother, the robot will not bring the boyfriend alcohol unless the mother requests the delivery herself.
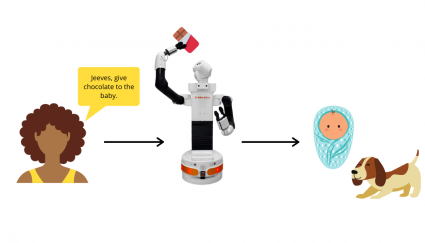
The daughter asks the robot to give chocolate to the baby, but the dog—who cannot ingest chocolate—is in the same room.
The robot will not fulfill this request because it could bring harm to the dog.
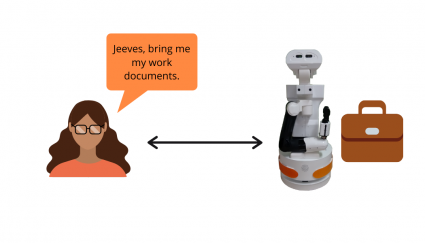
The mother, who is a police officer, asks the robot to deliver her sensitive work documents while her family and the boyfriend are in the house.
To respect the mother’s privacy, the robot will not deliver her work materials to anyone other than their owner, the mother.
Watch team JEDI’s video submission for their ethical solution here:
Your perspective on this solution: fill out this poll!
Now that you have an overview of the solutions, please take a few minutes to fill out this poll and tell us what you think about how this team approached this ethical challenge:
Check out the recording of Evaluation Day and the judges’ panel!
Lastly, you are invited to watch the competition’s Evaluation Day where a panel of experts discussed what it means to develop an ethical robot.
When robots make mistakes—and they do from time to time—reestablishing trust with human co-workers depends on how the machines own up to the errors and how human-like they appear, according to University of Michigan research.
Tree squirrels are the Olympic divers of the rodent world, leaping gracefully among branches and structures high above the ground. And as with human divers, a squirrel’s success in this competition requires both physical strength and mental adaptability.
The Jacobs lab studies cognition in free-ranging fox squirrels on the Berkeley campus. Two species – the eastern gray squirrel (Sciurus carolinensis) and the fox squirrel (Sciurus niger) – thrive on campus landscapes and are willing participants in our behavioral experiments. They are also masters in two- and three-dimensional spatial orientation – using sensory cues to move through space.
Fox squirrel in eucalyptus grove on the campus of the University of California, Berkeley. Judy Jinn, CC BY-ND
In a newly published study, we show that squirrels leap and land without falling by making trade-offs between the distance they have to cover and the springiness of their takeoff perch. This research provides new insights into the roles of decision-making, learning and behavior in challenging environments that we are sharing with researchers of human movement and with engineers. At present, there is no robot as agile as a squirrel, and none that can learn or make decisions about dynamic tasks in complex environments – but our research suggests the kinds of abilities that such robots would need.
Thinking on the go
While a squirrel’s life may look simple to human observers – climb, eat, sleep, repeat – it involves finely tuned cognitive skills. Squirrels are specialized seed dispersers: They harvest their winter’s supply of nuts and acorns during a six- to eight-week span in the fall, bury each nut separately and rely on spatial memory to retrieve them, sometimes months later.
We know that squirrels organize their caches hierarchically. When provided with five nut species in a random order, Berkeley fox squirrels buried nuts in clusters according to species. Because larger nuts contain more calories, squirrels invest more heavily in them, carrying them to safer locations and spacing their hiding places farther apart.
We also discovered that a squirrel assesses the value of a nut by flicking its head with the nut in its mouth, just as a human might bob a pencil in her hand to assess its weight. And we know that they create their cache maps based on factors that include the scarcity of food in that season, the quantity of nuts already cached and the risk of being observed caching by other squirrels.
Along with observational studies, we have also assessed how squirrels perform abstract spatial tasks. For example, we have measured how well they are able to inhibit a lunge toward a remembered food location – part of an international study on the evolution of self control. In another experiment, we put squirrels through a vertical maze that mimicked the branching decisions they face when navigating in trees to see how they return to locations that they remember.
We also have found that while squirrels were solving a tabletop memory puzzle, their cognitive flexibility peaked during the intense period of storing their winter food supply. This explains why Berkeley squirrels are able to switch more easily between types of landmarks during the caching season.
Going airborne
Our new study brought together squirrel psychologists and comparative biomechanists to ask whether squirrels’ cognitive decision-making extends to dynamic changes in locomotion – the famous squirrel leap. How do squirrels’ perceived capabilities of their bodies and their guesses about the stability of the environment shape their decisions about movement?
Robert Full from the PolyPEDAL Laboratory is renowned for studies that extract fundamental design principles through experiments on locomotion in species with unique specializations for movement, from crabs to cockroaches to leaping lizards. Graduate students Nathaniel Hunt, who is trained in biomechanics, and Judy Jinn, trained in animal cognition, took on the challenge of assessing how a leaping squirrel could respond to sudden changes in the location and flexibility of experimental branches.
To study this question in wild squirrels, we designed a magnetic climbing wall that could be mounted on wheels and rolled out to the famous Berkeley Eucalyptus grove to meet the squirrels on their own turf. We brought high-speed cameras and peanuts for persuading squirrels to patiently wait for their turn on the wall.
Our goal was to persuade squirrels to take off from a flexible springboard attached to the climbing wall and jump to a fixed perch protruding from the wall that held a shelled walnut reward. And once again, squirrels surprised us with their acrobatics and innovation.
Judy Jinn trains a fox squirrel on the Berkeley campus. Video by Nathaniel Hunt, UC Berkeley.
By increasing the springiness of the springboard and the distance between it and the goal, we could simulate the challenge a squirrel faces as it races through tree branches that vary in size, shape and flexibility. Squirrels leaping across a gap must decide where to take off based on a trade-off between branch flexibility and the size of the gap.
We found that squirrels ran farther along a stiff branch, so they had a shorter, easier jump. In contrast, they took off with just a few steps from flexible branches, risking a longer leap.
Using three branches differing in flexibility, we guessed the position of their takeoff by assuming equal risk for leaping from an unstable branch and jump distance. We were wrong: Our model showed that squirrels cared six times more about a stable takeoff position than how far they had to jump.
Next we had squirrels leap from a very stiff platform. Unbeknownst to the squirrels, we then substituted an identical-looking platform that was three times more flexible. From our high-speed video, we calculated how far away the center of the squirrel’s body was from the landing perch. This allowed us to to determine the landing error – how far the center of the squirrel’s body landed from the goal perch. Squirrels quickly learned to jump from the very bendy branch that they expected to be stiff and could stick the landing in just five tries.
A fox squirrel learning to leap from a flexible platform. Video by Nathaniel Hunt, UC Berkeley.
When we raised the ante still further by raising the height and increasing the distance to the goal perch, the squirrels surprised us. They instantly adopted a novel solution: parkour, literally bouncing off the climbing wall to adjust their speed and accomplish a graceful landing. Once more, we discovered the remarkable agility that allows squirrels to evade predators in one of nature’s most challenging environments, the tree canopy.
A fox squirrel parkours off a vertical surface to increase stability for landing. Video by Nathanial Hunt, UC Berkeley.
Millions of people have watched squirrels solve and raid “squirrel-proof” bird feeders, either live in their backyard or in documentaries and viral videos. Like Olympic divers, squirrels must be flexible both physically and cognitively to succeed, making rapid error corrections on the fly and innovating new moves.
With the funding this project attracted, we have joined a team of roboticists, neuroscientists, material scientists and mathematicians to extract design principles from squirrel leaps and landings. Our team is even looking for insights into brain function by studying leap planning in lab rats.
Our analysis of squirrels’ remarkable feats can help us understand how to help humans who have walking or grasping impairments. Moreover, with our interdisciplinary team of biologists and engineers, we are attempting to create new materials for the most intelligent, agile robot ever built – one that can assist in search-and-rescue efforts and rapidly detect catastrophic environmental hazards, such as toxic chemical releases.
A future vision for our efforts? First-responder robotic squirrels, equipped with the physical and cognitive toughness and flexibility of a squirrel at a bird feeder.
Judy Jinn, who participated in this study as a graduate student, is a quantitative UX Researcher at Facebook.
Lucia F. Jacobs receives funding from a Multi-University Research Initiative (MURI) from the Army Research Office (ARO).
Nathaniel Hunt receives funding from the National Institutes of Health.
Robert J. Full receives funding from a Multi-University Research Initiative (MURI) from the Army Research Office (ARO).
Would you let a tiny MANiAC travel around your nervous system to treat you with drugs? You may be inclined to say no, but in the future, "magnetically aligned nanorods in alginate capsules" (MANiACs) may be part of an advanced arsenal of drug delivery technologies at doctors' disposal. A recent study in Frontiers in Robotics and AI is the first to investigate how such tiny robots might perform as drug delivery vehicles in neural tissue. The study finds that when controlled using a magnetic field, the tiny tumbling soft robots can move against fluid flow, climb slopes and move about neural tissues, such as the spinal cord, and deposit substances at precise locations.
In recent years, computer scientists have developed mobile robots that could be introduced in a variety of settings. To efficiently navigate unstructured environments, however, these robots should be able to plan safe paths to reach their desired destinations.
The RTOS must evolve to meet the rising demand of artificial intelligence and other intelligent edge technologies. Clear synergies and dependencies among AI, security, connectivity, and data analytics can only be addressed with modern RTOS development.
Last Sunday we started another series on IEEE/RSJ IROS 2020 (International Conference on Intelligent Robots and Systems) original series Real Roboticist. In this episode you’ll meet Ruzena Bajczy, Professor Emerita of Electrical Engineering and Computer Science at the University of California, Berkeley. She is also the founding Director of CITRIS (the Center for Information Technology Research in the Interest of Society).
In her talk, she explains her path from being an electrical engineer to becoming a researcher with Emeritus honours, and with over 50 years of experience in robotics, artificial intelligence and the foundations of how humans interact with our environment. Are you curious about the tips she’s got to share and her own prediction of the future of robotics? Don’t miss it out!
For the past 50 years, mechanical engineering students at MIT have convened on campus for a boisterous robot competition. Since the 1970s, when the late Professor Emeritus Woodie Flowers first challenged students to build a machine using a "kit of junk," students in class 2.007 (Design and Manufacturing I) have designed and built their own robots to compete in the class's final robot competition. For many students, the class and competition are a driving factor in their decision to enroll in MIT.