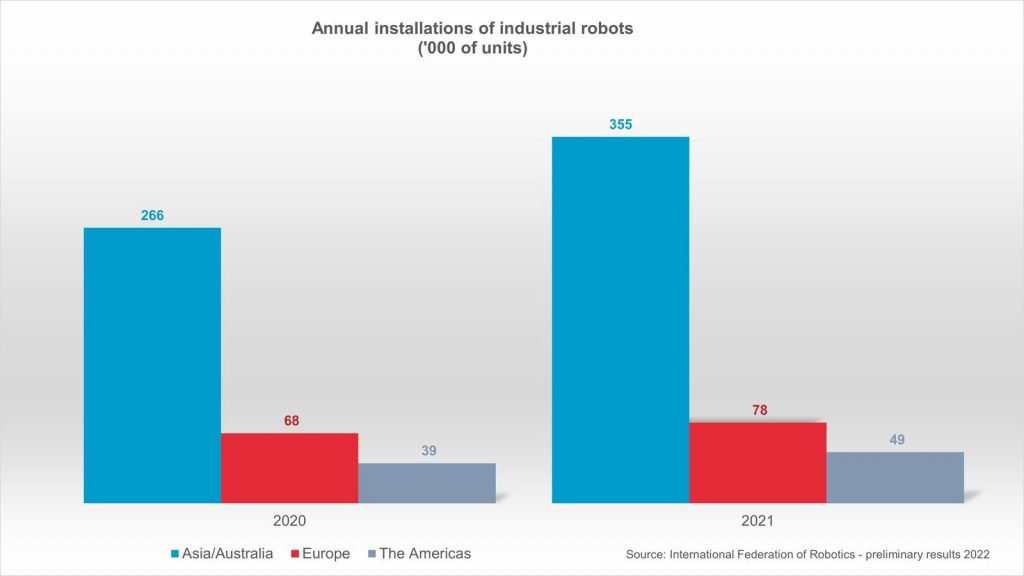
Inspired by fireflies, MIT researchers have created soft actuators that can emit light in different colors or patterns. Credits: Courtesy of the researchers
By Adam Zewe | MIT News Office
Fireflies that light up dusky backyards on warm summer evenings use their luminescence for communication — to attract a mate, ward off predators, or lure prey.
These glimmering bugs also sparked the inspiration of scientists at MIT. Taking a cue from nature, they built electroluminescent soft artificial muscles for flying, insect-scale robots. The tiny artificial muscles that control the robots’ wings emit colored light during flight.
This electroluminescence could enable the robots to communicate with each other. If sent on a search-and-rescue mission into a collapsed building, for instance, a robot that finds survivors could use lights to signal others and call for help.
The ability to emit light also brings these microscale robots, which weigh barely more than a paper clip, one step closer to flying on their own outside the lab. These robots are so lightweight that they can’t carry sensors, so researchers must track them using bulky infrared cameras that don’t work well outdoors. Now, they’ve shown that they can track the robots precisely using the light they emit and just three smartphone cameras.
“If you think of large-scale robots, they can communicate using a lot of different tools — Bluetooth, wireless, all those sorts of things. But for a tiny, power-constrained robot, we are forced to think about new modes of communication. This is a major step toward flying these robots in outdoor environments where we don’t have a well-tuned, state-of-the-art motion tracking system,” says Kevin Chen, who is the D. Reid Weedon, Jr. Assistant Professor in the Department of Electrical Engineering and Computer Science (EECS), the head of the Soft and Micro Robotics Laboratory in the Research Laboratory of Electronics (RLE), and the senior author of the paper.
He and his collaborators accomplished this by embedding miniscule electroluminescent particles into the artificial muscles. The process adds just 2.5 percent more weight without impacting the flight performance of the robot.
Joining Chen on the paper are EECS graduate students Suhan Kim, the lead author, and Yi-Hsuan Hsiao; Yu Fan Chen SM ’14, PhD ’17; and Jie Mao, an associate professor at Ningxia University. The research was published this month in IEEE Robotics and Automation Letters.
A light-up actuator
These researchers previously demonstrated a new fabrication technique to build soft actuators, or artificial muscles, that flap the wings of the robot. These durable actuators are made by alternating ultrathin layers of elastomer and carbon nanotube electrode in a stack and then rolling it into a squishy cylinder. When a voltage is applied to that cylinder, the electrodes squeeze the elastomer, and the mechanical strain flaps the wing.
To fabricate a glowing actuator, the team incorporated electroluminescent zinc sulphate particles into the elastomer but had to overcome several challenges along the way.
First, the researchers had to create an electrode that would not block light. They built it using highly transparent carbon nanotubes, which are only a few nanometers thick and enable light to pass through.
However, the zinc particles only light up in the presence of a very strong and high-frequency electric field. This electric field excites the electrons in the zinc particles, which then emit subatomic particles of light known as photons. The researchers use high voltage to create a strong electric field in the soft actuator, and then drive the robot at a high frequency, which enables the particles to light up brightly.
“Traditionally, electroluminescent materials are very energetically costly, but in a sense, we get that electroluminescence for free because we just use the electric field at the frequency we need for flying. We don’t need new actuation, new wires, or anything. It only takes about 3 percent more energy to shine out light,” Kevin Chen says.
As they prototyped the actuator, they found that adding zinc particles reduced its quality, causing it to break down more easily. To get around this, Kim mixed zinc particles into the top elastomer layer only. He made that layer a few micrometers thicker to accommodate for any reduction in output power.
While this made the actuator 2.5 percent heavier, it emitted light without impacting flight performance.
“We put a lot of care into maintaining the quality of the elastomer layers between the electrodes. Adding these particles was almost like adding dust to our elastomer layer. It took many different approaches and a lot of testing, but we came up with a way to ensure the quality of the actuator,” Kim says.
Adjusting the chemical combination of the zinc particles changes the light color. The researchers made green, orange, and blue particles for the actuators they built; each actuator shines one solid color.
They also tweaked the fabrication process so the actuators could emit multicolored and patterned light. The researchers placed a tiny mask over the top layer, added zinc particles, then cured the actuator. They repeated this process three times with different masks and colored particles to create a light pattern that spelled M-I-T.

These artificial muscles, which control the wings of featherweight flying robots, light up while the robot is in flight, which provides a low-cost way to track the robots and also could enable them to communicate. Credits: Courtesy of the researchers
Following the fireflies
Once they had finetuned the fabrication process, they tested the mechanical properties of the actuators and used a luminescence meter to measure the intensity of the light.
From there, they ran flight tests using a specially designed motion-tracking system. Each electroluminescent actuator served as an active marker that could be tracked using iPhone cameras. The cameras detect each light color, and a computer program they developed tracks the position and attitude of the robots to within 2 millimeters of state-of-the-art infrared motion capture systems.
“We are very proud of how good the tracking result is, compared to the state-of-the-art. We were using cheap hardware, compared to the tens of thousands of dollars these large motion-tracking systems cost, and the tracking results were very close,” Kevin Chen says.
In the future, they plan to enhance that motion tracking system so it can track robots in real-time. The team is working to incorporate control signals so the robots could turn their light on and off during flight and communicate more like real fireflies. They are also studying how electroluminescence could even improve some properties of these soft artificial muscles, Kevin Chen says.
“This work is really interesting because it minimizes the overhead (weight and power) for light generation without compromising flight performance,” says Kaushik Jayaram, an assistant professor in Department of Mechanical Engineering at the University of Colorado at Boulder, who was not involved with this research. “The wingbeat synchronized flash generation demonstrated in this work will make it easier for motion tracking and flight control of multiple microrobots in low-light environments both indoors and outdoors.”
“While the light production, the reminiscence of biological fireflies, and the potential use of communication presented in this work are extremely interesting, I believe the true momentum is that this latest development could turn out to be a milestone toward the demonstration of these robots outside controlled laboratory conditions,” adds Pakpong Chirarattananon, an associate professor in the Department of Biomedical Engineering at the City University of Hong Kong, who also was not involved with this work. “The illuminated actuators potentially act as active markers for external cameras to provide real-time feedback for flight stabilization to replace the current motion capture system. The electroluminescence would allow less sophisticated equipment to be used and the robots to be tracked from distance, perhaps via another larger mobile robot, for real-world deployment. That would be a remarkable breakthrough. I would be thrilled to see what the authors accomplish next.”
This work was supported by the Research Laboratory of Electronics at MIT.