Guest post by Martin Stránský, Research Scientist @GoodAI
{kind=link}
Recent progress in artificial intelligence, especially in the area of deep learning, has been breath-taking. This is very encouraging for anyone interested in the field, yet the true progress towards human-level artificial intelligence is much harder to evaluate.
The evaluation of artificial intelligence is a very difficult problem for a number of reasons. For example, the lack of consensus on the basic desiderata necessary for intelligent machines is one of the primary barriers to the development of unified approaches towards comparing different agents. Despite a number of researchers specifically focusing on this topic (e.g. José Hernández-Orallo or Kristinn R. Thórisson to name a few), the area would benefit from more attention from the AI community.
Methods for evaluating AI are important tools that help to assess the progress of already built agents. The comparison and evaluation of roadmaps and approaches towards building such agents is however less explored. Such comparison is potentially even harder, due to the vagueness and limited formal definitions within such forward-looking plans.
Nevertheless, we believe that in order to steer towards promising areas of research and to identify potential dead-ends, we need to be able to meaningfully compare existing roadmaps. Such comparison requires the creation of a framework that defines processes on how to acquire important and comparable information from existing documents outlining their respective roadmaps. Without such a unified framework, each roadmap might not only differ in its target (e.g. general AI, human-level AI, conversational AI, etc…) but also in its approaches towards achieving that goal that might be impossible to compare and contrast.
This post offers a glimpse of how we, at GoodAI, are starting to look at this problem internally (comparing the progress of our three architecture teams), and how this might scale to comparisons across the wider community. This is still very much a work-in-progress, but we believe it might be beneficial to share these initial thoughts with the community, to start the discussion about, what we believe, is an important topic.
Overview
In the first part of this article, a comparison of three GoodAI architecture development roadmaps is presented and a technique for comparing them is discussed. The main purpose is to estimate the potential and completeness of plans for every architecture to be able to direct our effort to the most promising one.
To manage adding roadmaps from other teams we have developed a general plan of human-level AI development called a meta-roadmap. This meta-roadmap consists of 10 steps which must be passed in order to reach an ‘ultimate’ target. We hope that most of the potentially disparate plans solve one or more problems identified in the meta-roadmap.
Next, we tried to compare our approaches with that of Mikolov et. al by assigning the current documents and open tasks to problems in the meta-roadmap. We found that useful, as it showed us what is comparable and that different techniques of comparison are needed for every problem.
Architecture development plans comparison
Three teams from GoodAI have been working on their architectures for a few months. Now we need a method to measure the potential of the architectures to be able to, for example, direct our effort more efficiently by allocating more resources to the team with the highest potential. We know that determining which way is the most promising based on the current state is still not possible, so we asked the teams working on unfinished architectures to create plans for future development, i.e. to create their roadmaps.
Based on the provided responses, we have iteratively unified requirements for those plans. After numerous discussions, we came up with the following structure:
- A Unit of a plan is called a milestone and describes some piece of work on a part of the architecture (e.g. a new module, a different structure, an improvement of a module by adding functionality, tuning parameters etc.)
- Each milestone contains — Time Estimate, i.e. expected time spent on milestone assuming current team size, Characteristic of work or new features and Test of new features.
- A plan can be interrupted by checkpoints which serve as common tests for two or more architectures.
Now we have a set of basic tools to monitor progress:
- We will see whether a particular team will achieve their self-designed tests and thereby can fulfill their original expectations on schedule.
- Due to checkpoints it is possible to compare architectures in the middle of development.
- We can see how far a team sees. Ideally after finishing the last milestone, the architecture should be prepared to pass through a curriculum (which will be developed in the meantime) and a final test afterwards.
- Total time estimates. We can compare them as well.
- We are still working on a unified set (among GoodAI architectures) of features which we will require from an architecture (desiderata for an architecture).
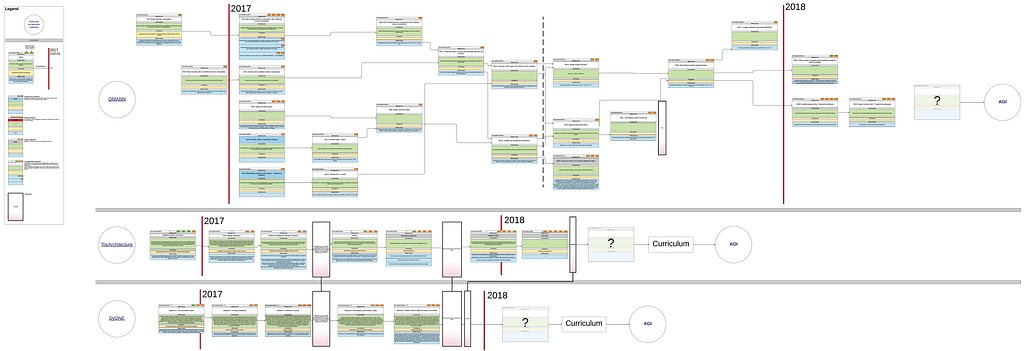
The particular plans were placed side by side (c.f. Figure 1) and a few checkpoints were (currently vaguely) defined. As we can see, teams have rough plans of their work for more than one year ahead, still the plans are not complete in a sense that the architectures will not be ready for any curriculum. Two architectures use a connectivist approach and they are easy to compare. The third, OMANN, manipulates symbols, thus from the beginning it can perform tasks which are hard for the other two architectures and vice versa. This means that no checkpoints for OMANN have been defined yet. We see a lack of common tests as a serious issue with the plan and are looking for changes to make the architecture more comparable with the others, although it may cause some delays with the development.
There was an effort to include another architecture in the comparison, but we have not been able to find a document describing future work in such detail, with the exception of Weston’s et al. paper. After further analysis, we determined that the paper was focused on a slightly different problem than the development of an architecture. We will address this later in the post.
Assumptions for a common approach
We would like to take a look at the problem from the perspective of the unavoidable steps required to develop an intelligent agent. First we must make a few assumptions about the whole process. We realize that these are somewhat vague — we want to make them acceptable to other AI researchers.
- A target is to produce a software (referred to as an architecture), which can be a part of some agent in some world.
- In the world there will be tasks that the agent should solve, or a reward based on world states that the agent should seek.
- An intelligent agent can adapt to an unknown/changing environment and solve previously unseen tasks.
- To check whether the ultimate goal was reached (no matter how defined), every approach needs some well defined final test, which shows how intelligent the agent is (preferably compared to humans).
Before the agent is able to pass their final test, there must be a learning phase in order to teach the agent all necessary skills or abilities. If there is a possibility that the agent can pass the final test without learning anything, the final test is insufficient with respect to point 3. Description of the learning phase (which can include also a world description) is called curriculum.
Meta-roadmap
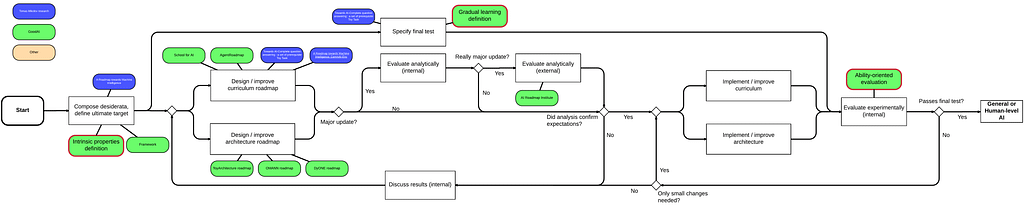
Using the above assumptions (and a few more obvious ones which we won’t enumerate here) we derive Figure 2 describing the list of necessary steps and their order. We call this diagram a meta-roadmap.

{kind=link}
The most important and imminent tasks in the diagram are
- The definition of an ultimate target,
- A final test specification,
- The proposed design of a curriculum, and
- A roadmap for the development of an architecture.
We think that the majority of current approaches solve one or more of these open problems; from different points of view according to an ultimate target and beliefs of authors. In order to make the effort more clear, we will divide approaches described in published papers into groups according to the problem that they solve and compare them within those groups. Of course, approaches are hard to compare among groups (yet it is not impossible, for example final test can be comparable to a curriculum under specific circumstances). Even within one group it can be very hard in some situations, where requirements (which are the first thing that should be defined according to our diagram) differ significantly.
Also an analysis of complexity and completeness of an approach can be made within this framework. For example, if a team omits one or more of the open problems, it indicates that the team may not have considered that particular issue and are proceeding without a complete notion of the ‘big picture’.
Problem assignment
We would like to show an attempt to assign approaches to problems and compare them. First, we have analyzed GoodAI’s and Mikolov/Weston’s approach as the latter is well described. You can see the result in Figure 3 below.
{kind=link}
As the diagram suggests, we work on a few common problems. We will not provide the full analysis here, but will make several observations to demonstrate the meaningfulness of the meta-roadmap. In desiderata, according to Mikolov’s “A Roadmap towards Machine Intelligence”, a target is an agent which can understand human language. In contrast with the GoodAI approach, other modalities than text are not considered as important. In the curriculum, GoodAI wants to teach an agent in a more anthropocentric way — visual input first, language later — while the entirety of Weston’s curriculum comprises of language-oriented tasks.
Mikolov et al. do not provide a development plan for their architecture, so we can compare their curriculum roadmap to ours, but it is not possible to include their desiderata into the diagram in Figure 1.
Conclusion
We have presented our meta-roadmap and a comparison of three GoodAI development roadmaps. We hope that this post will offer a glimpse into how we started this process at GoodAI and will invigorate a discussion on how this could be improved and scaled beyond internal comparisons. We will be glad to receive any feedback — the generality of our meta-roadmap should be discussed further, as well as our methods for estimating roadmap completeness and their potential to achieve human-level AI.
Roadmap Comparison at GoodAI was originally published in AI Roadmap Institute Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.