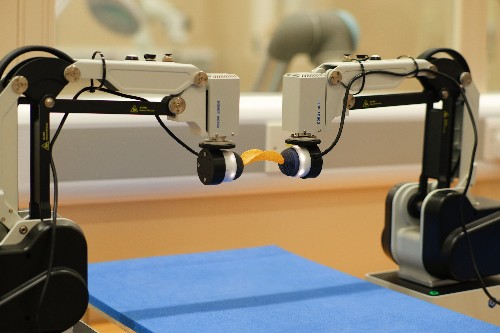
Dual arm robot holding crisp. Image: Yijiong Lin
The new Bi-Touch system, designed by scientists at the University of Bristol and based at the Bristol Robotics Laboratory, allows robots to carry out manual tasks by sensing what to do from a digital helper.
The findings, published in IEEE Robotics and Automation Letters, show how an AI agent interprets its environment through tactile and proprioceptive feedback, and then control the robots’ behaviours, enabling precise sensing, gentle interaction, and effective object manipulation to accomplish robotic tasks.
This development could revolutionise industries such as fruit picking, domestic service, and eventually recreate touch in artificial limbs.
Lead author Yijiong Lin from the Faculty of Engineering, explained: “With our Bi-Touch system, we can easily train AI agents in a virtual world within a couple of hours to achieve bimanual tasks that are tailored towards the touch. And more importantly, we can directly apply these agents from the virtual world to the real world without further training.
“The tactile bimanual agent can solve tasks even under unexpected perturbations and manipulate delicate objects in a gentle way.”
Bimanual manipulation with tactile feedback will be key to human-level robot dexterity. However, this topic is less explored than single-arm settings, partly due to the availability of suitable hardware along with the complexity of designing effective controllers for tasks with relatively large state-action spaces. The team were able to develop a tactile dual-arm robotic system using recent advances in AI and robotic tactile sensing.
The researchers built up a virtual world (simulation) that contained two robot arms equipped with tactile sensors. They then design reward functions and a goal-update mechanism that could encourage the robot agents to learn to achieve the bimanual tasks and developed a real-world tactile dual-arm robot system to which they could directly apply the agent.
The robot learns bimanual skills through Deep Reinforcement Learning (Deep-RL), one of the most advanced techniques in the field of robot learning. It is designed to teach robots to do things by letting them learn from trial and error akin to training a dog with rewards and punishments.
For robotic manipulation, the robot learns to make decisions by attempting various behaviours to achieve designated tasks, for example, lifting up objects without dropping or breaking them. When it succeeds, it gets a reward, and when it fails, it learns what not to do. With time, it figures out the best ways to grab things using these rewards and punishments. The AI agent is visually blind relying only on proprioceptive feedback – a body’s ability to sense movement, action and location and tactile feedback.
They were able to successfully enable to the dual arm robot to successfully safely lift items as fragile as a single Pringle crisp.
Co-author Professor Nathan Lepora added: “Our Bi-Touch system showcases a promising approach with affordable software and hardware for learning bimanual behaviours with touch in simulation, which can be directly applied to the real world. Our developed tactile dual-arm robot simulation allows further research on more different tasks as the code will be open-source, which is ideal for developing other downstream tasks.”
Yijiong concluded: “Our Bi-Touch system allows a tactile dual-arm robot to learn sorely from simulation, and to achieve various manipulation tasks in a gentle way in the real world.
“And now we can easily train AI agents in a virtual world within a couple of hours to achieve bimanual tasks that are tailored towards the touch.”
- PAPER – Bi-Touch: Bimanual Tactile Manipulation With Sim-to-Real Deep Reinforcement Learning. Yijiong Lin, Alex Church, Max Yang, Haoran Li, John Lloyd, Dandan Zhang, and Nathan F. Lepora. IEEE Robotics and Automation Letters, vol. 8, no. 9, pp. 5472-5479, Sept. 2023, doi: 10.1109/LRA.2023.3295991.