Every week, new models are released, along with dozens of benchmarks. But what does that mean for a practitioner deciding which model to use? How should they approach assessing the quality of a newly released model? And how do benchmarked capabilities like reasoning translate into real-world value?
In this post, we’ll evaluate the newly released NVIDIA Llama Nemotron Super 49B 1.5 model. We use syftr, our generative AI workflow exploration and evaluation framework, to ground the analysis in a real business problem and explore the tradeoffs of a multi-objective analysis.
After examining more than a thousand workflows, we offer actionable guidance on the use cases where the model shines.
The number of parameters count, but they’re not everything
It should be no surprise that parameter count drives much of the cost of serving LLMs. Weights need to be loaded into memory, and key-value (KV) matrices cached. Bigger models typically perform better — frontier models are almost always massive. GPU advancements were foundational to AI’s rise by enabling these increasingly large models.
But scale alone doesn’t guarantee performance.
Newer generations of models often outperform their larger predecessors, even at the same parameter count. The Nemotron models from NVIDIA are a good example. The models build on existing open models, , pruning unnecessary parameters, and distilling new capabilities.
That means a smaller Nemotron model can often outperform its larger predecessor across multiple dimensions: faster inference, lower memory use, and stronger reasoning.
We wanted to quantify those tradeoffs — especially against some of the largest models in the current generation.
How much more accurate? How much more efficient? So, we loaded them onto our cluster and got to work.
How we assessed accuracy and cost
Step 1: Identify the problem
With models in hand, we needed a real-world challenge. One that tests reasoning, comprehension, and performance inside an agentic AI flow.
Picture a junior financial analyst trying to ramp up on a company. They should be able to answer questions like: “Does Boeing have an improving gross margin profile as of FY2022?”
But they also need to explain the relevance of that metric: “If gross margin is not a useful metric, explain why.”
To test our models, we’ll assign it the task of synthesizing data delivered through an agentic AI flow and then measure their ability to efficiently deliver an accurate answer.
To answer both types of questions correctly, the models needs to:
- Pull data from multiple financial documents (such as annual and quarterly reports)
- Compare and interpret figures across time periods
- Synthesize an explanation grounded in context
FinanceBench benchmark is designed for exactly this type of task. It pairs filings with expert-validated Q&A, making it a strong proxy for real enterprise workflows. That’s the testbed we used.
Step 2: Models to workflows
To test in a context like this, you need to build and understand the full workflow — not just the prompt — so you can feed the right context into the model.
And you have to do this every time you evaluate a new model–workflow pair.
With syftr, we’re able to run hundreds of workflows across different models, quickly surfacing tradeoffs. The result is a set of Pareto-optimal flows like the one shown below.
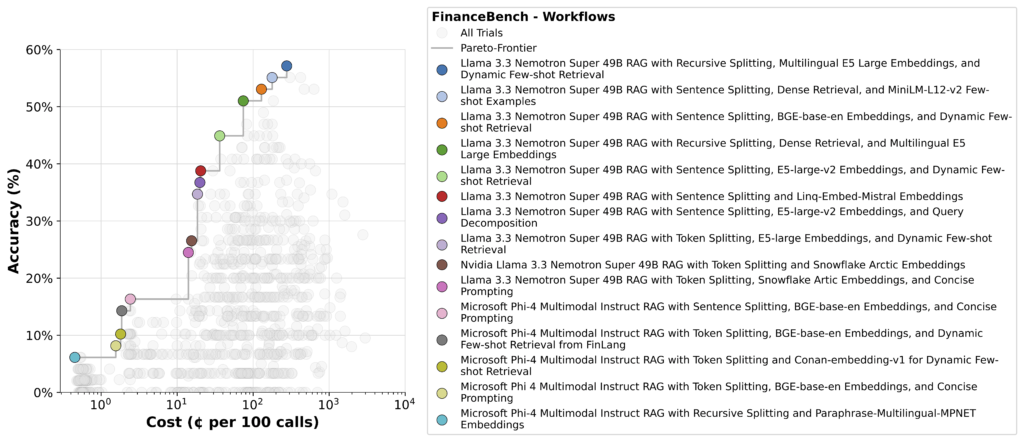
In the lower left, you’ll see simple pipelines using another model as the synthesizing LLM. These are inexpensive to run, but their accuracy is poor.
In the upper right are the most accurate — but more expensive since these typically rely on agentic strategies that break down the question, make multiple LLM calls, and analyze each chunk independently. This is why reasoning requires efficient computing and optimizations to keep inference costs in check.
Nemotron shows up strongly here, holding its own across the remaining Pareto frontier.
Step 3: Deep dive
To better understand model performance, we grouped workflows by the LLM used at each step and plotted the Pareto frontier for each.
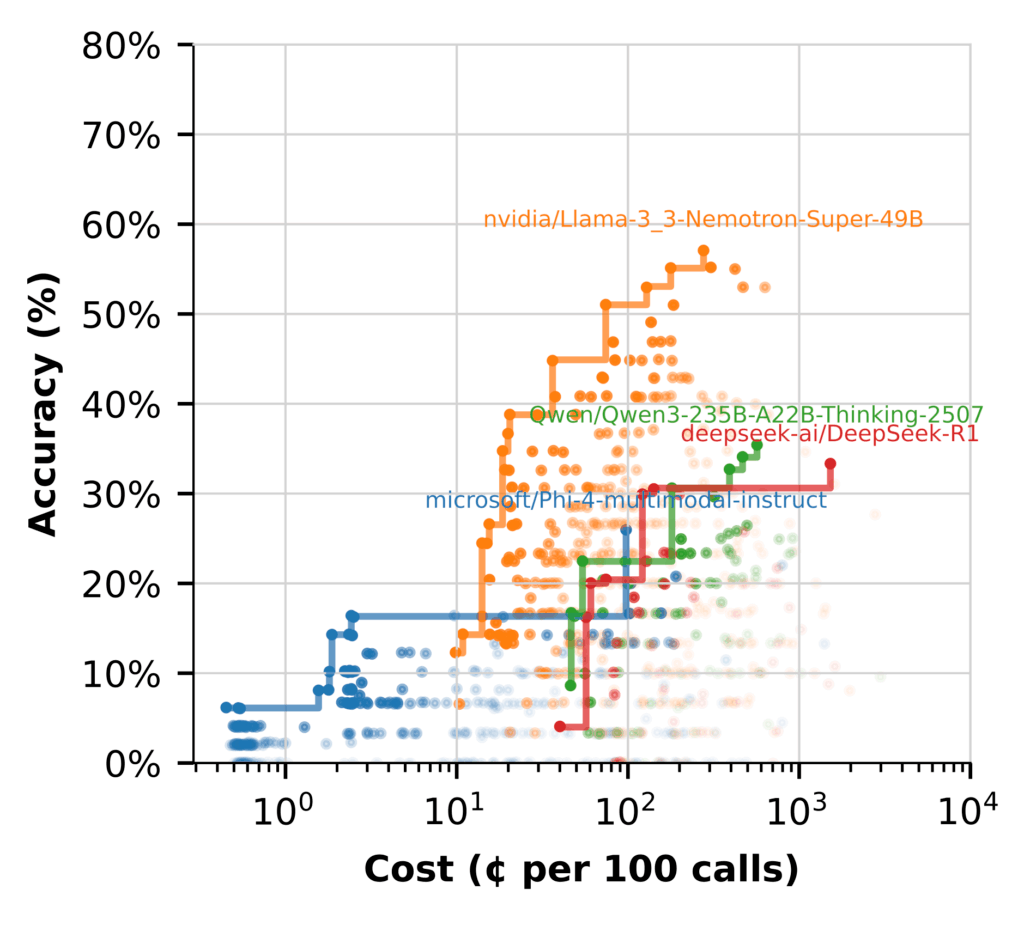
The performance gap is clear. Most models struggle to get anywhere near Nemotron’s performance. Some have trouble generating reasonable answers without heavy context engineering. Even then, it remains less accurate and more expensive than larger models.
But when we switch to using the LLM for (Hypothetical Document Embeddings) HyDE, the story changes. (Flows marked N/A don’t include HyDE.)
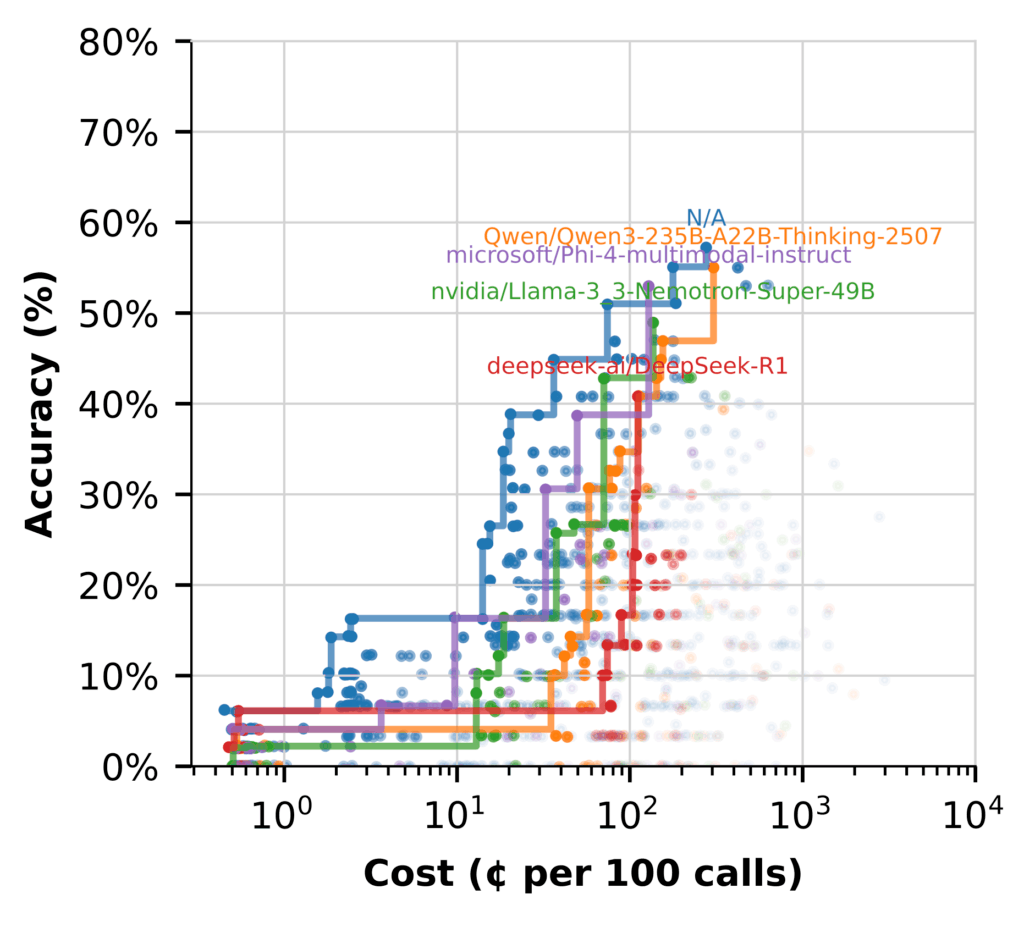
Here, several models perform well, with affordability while delivering high‑accuracy flows.
Key takeaways:
- Nemotron shines in synthesis, producing high‑fidelity answers without added cost
- Using other models that excel at HyDE frees Nemotron to focus on high-value reasoning
- Hybrid flows are the most efficient setup, using each model where it performs best
Optimizing for value, not just size
When evaluating new models, success isn’t just about accuracy. It’s about finding the right balance of quality, cost, and fit for your workflow. Measuring latency, efficiency, and overall impact helps ensure you’re getting real value
NVIDIA Nemotron models are built with this in mind. They’re designed not only for power, but for practical performance that helps teams drive impact without runaway costs.
Pair that with a structured, Syftr-guided evaluation process, and you’ve got a repeatable way to stay ahead of model churn while keeping compute and budget in check.
To explore syftr further, check out the GitHub repository.
The post Balancing accuracy, cost, and real‑world performance with NVIDIA Nemotron models appeared first on DataRobot.