Race Avoidance in the Development of Artificial General Intelligence
Olga Afanasjeva, Jan Feyereisl, Marek Havrda, Martin Holec, Seán Ó hÉigeartaigh, Martin Poliak
SUMMARY
◦ Promising strides are being made in research towards artificial general intelligence systems. This progress might lead to an apparent winner-takes-all race for AGI.
◦ Concerns have been raised that such a race could create incentives to skimp on safety and to defy established agreements between key players.
◦ The AI Roadmap Institute held a workshop to begin interdisciplinary discussion on how to avoid scenarios where such dangerous race could occur.
◦ The focus was on scoping the problem, defining relevant actors, and visualizing possible scenarios of the AI race through example roadmaps.
◦ The workshop was the first step in preparation for the AI Race Avoidance round of the General AI Challenge that aims to tackle this difficult problem via citizen science and promote AI safety research beyond the boundaries of the small AI safety community.
Scoping the problem
With the advent of artificial intelligence (AI) in most areas of our lives, the stakes are increasingly becoming higher at every level. Investments into companies developing machine intelligence applications are reaching astronomical amounts. Despite the rather narrow focus of most existing AI technologies, the extreme competition is real and it directly impacts the distribution of researchers among research institutions and private enterprises.
With the goal of artificial general intelligence (AGI) in sight, the competition on many fronts will become acute with potentially severe consequences regarding the safety of AGI.
The first general AI system will be disruptive and transformative. First-mover advantage will be decisive in determining the winner of the race due to the expected exponential growth in capabilities of the system and subsequent difficulty of other parties to catch up. There is a chance that lengthy and tedious AI safety work ceases being a priority when the race is on. The risk of AI-related disaster increases when developers do not devote the attention and resources to safety of such a powerful system [1].
Once this Pandora’s box is opened, it will be hard to close. We have to act before this happens and hence the question we would like to address is:
How can we avoid general AI research becoming a race between researchers, developers and companies, where AI safety gets neglected in favor of faster deployment of powerful, but unsafe general AI?
Motivation for this post
As a community of AI developers, we should strive to avoid the AI race. Some work has been done on this topic in the past [1,2,3,4,5], but the problem is largely unsolved. We need to focus the efforts of the community to tackle this issue and avoid a potentially catastrophic scenario in which developers race towards the first general AI system while sacrificing safety of humankind and their own.
This post marks “step 0” that we have taken to tackle the issue. It summarizes the outcomes of a workshop held by the AI Roadmap Institute on 29th May 2017, at GoodAI head office in Prague, with the participation of Seán Ó hÉigeartaigh (CSER), Marek Havrda, Olga Afanasjeva, Martin Poliak (GoodAI), Martin Holec (KISK MUNI) and Jan Feyereisl (GoodAI & AI Roadmap Institute). We focused on scoping the problem, defining relevant actors, and visualizing possible scenarios of the AI race.
This workshop is the first in a series held by the AI Roadmap Institute in preparation for the AI Race Avoidance round of the General AI Challenge (described at the bottom of this page and planned to launch in late 2017). Posing the AI race avoidance problem as a worldwide challenge is a way to encourage the community to focus on solving this problem, explore this issue further and ignite interest in AI safety research.
By publishing the outcomes of this and the future workshops, and launching the challenge focused on AI race avoidance, we would like to promote AI safety research beyond the boundaries of the small AI safety community.
The issue should be subject to a wider public discourse, and should benefit from cross-disciplinary work of behavioral economists, psychologists, sociologists, policy makers, game theorists, security experts, and many more. We believe that transparency is essential part of solving many of the world’s direst problems and the AI race is no exception. This in turn may reduce regulation over-shooting and unreasonable political control that could hinder AI research.
Proposed line of thinking about the AI race: Example Roadmaps
One approach for starting to tackle the issue of AI race avoidance, and laying down the foundations for thorough discussion, is the creation of concrete roadmaps that outline possible scenarios of the future. Scenarios can be then compared, and mitigation strategies for negative futures can be suggested.
We used two simple methodologies for creating example roadmaps:
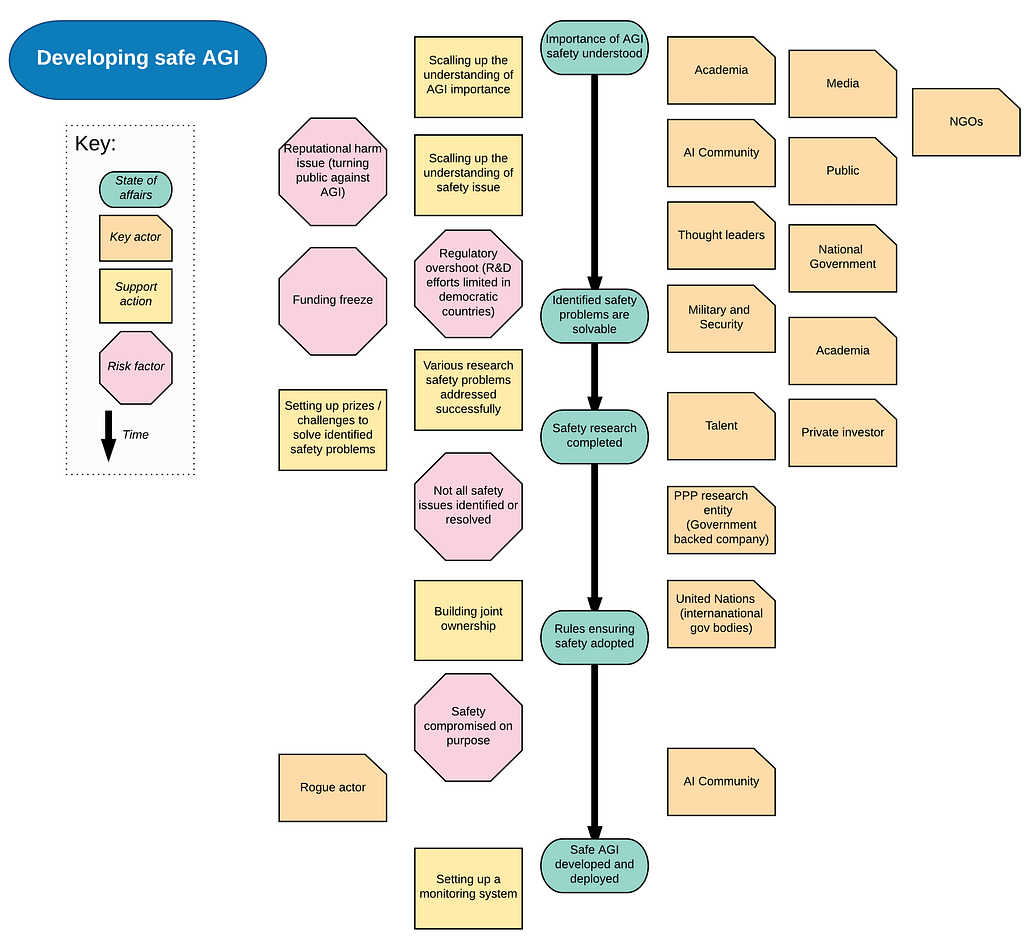
Methodology 1: a simple linear development of affairs is depicted by various shapes and colors representing the following notions: state of affairs, key actor, action, risk factor. The notions are grouped around each state of affairs in order to illustrate principal relevant actors, actions and risk factors.
Figure 1: This example roadmap depicts the safety issue before an AGI is developed. It is meant to be read top-down: arrow connecting ‘state-of-affairs’ depicts time. Entities representing actors, actions and factors, are placed around the time arrow, closest to states of affairs that they influence the most [full-size].
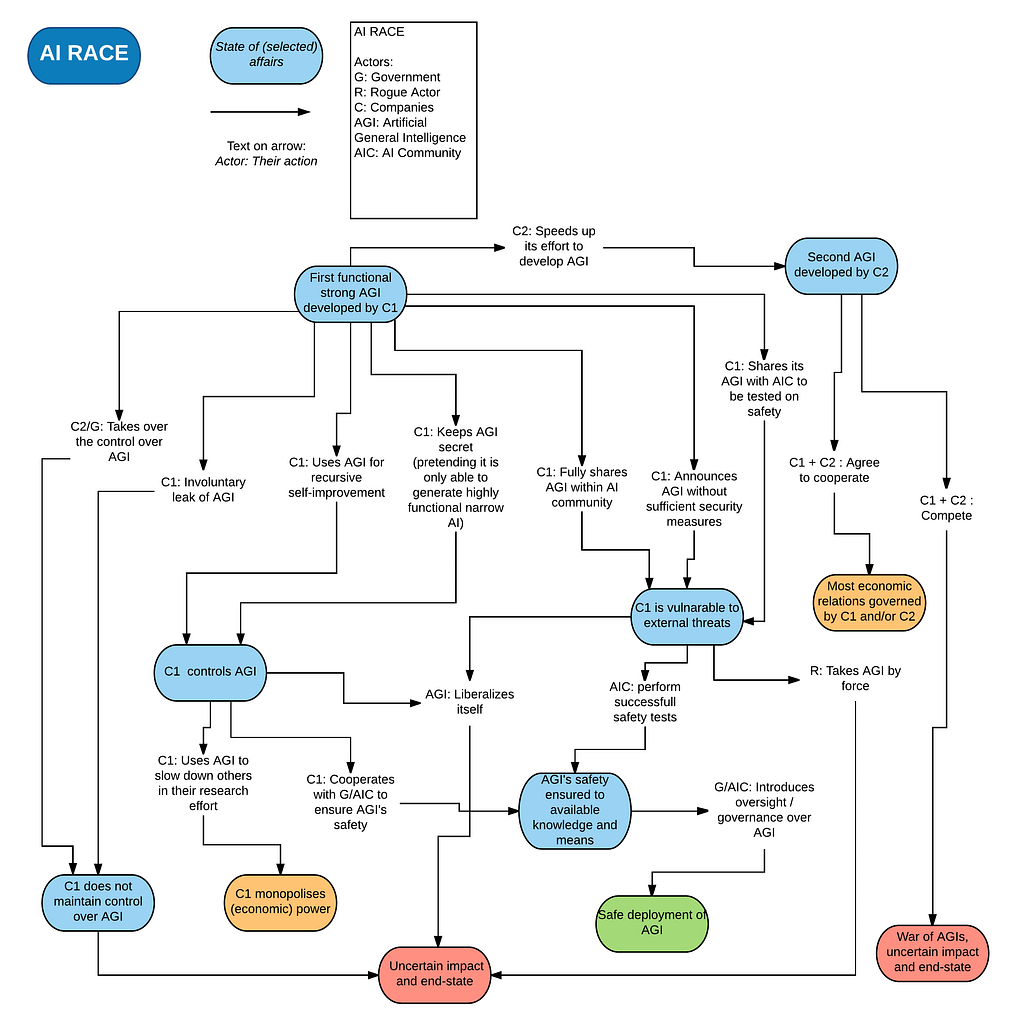
Methodology 2: each node in a roadmap represents a state, and each link, or transition, represents a decision-driven action by one of the main actors (such as a company/AI developer, government, rogue actor, etc.)
Figure 2: The example roadmap above visualises various scenarios from the point when the very first hypothetical company (C1) develops an AGI system. The roadmap primarily focuses on the dilemmas of C1. Furthermore, the roadmap visualises possible decisions made by key identified actors in various States of affairs, in order to depict potential roads to various outcomes. Traffic-light color coding is used to visualize the potential outcomes. Our aim was not to present all the possible scenarios, but a few vivid examples out of the vast spectrum of probable futures [full-size].
During the workshop, a number of important issues were raised. For example, the need to distinguish different time-scales for which roadmaps can be created, and different viewpoints (good/bad scenario, different actor viewpoints, etc.)
Timescale issue
Roadmapping is frequently a subjective endeavor and hence multiple approaches towards building roadmaps exist. One of the first issues that was encountered during the workshop was with respect to time variance. A roadmap created with near-term milestones in mind will be significantly different from long-term roadmaps, nevertheless both timelines are interdependent. Rather than taking an explicit view on short-/long-term roadmaps, it might be beneficial considering these probabilistically. For example, what roadmap can be built, if there was a 25% chance of general AI being developed within the next 15 years and 75% chance of achieving this goal in 15–400 years?
Considering the AI race at different temporal scales is likely to bring about different aspects which should be focused on. For instance, each actor might anticipate different speed of reaching the first general AI system. This can have a significant impact on the creation of a roadmap and needs to be incorporated in a meaningful and robust way. For example, the Boy Who Cried Wolf situation can decrease the established trust between actors and weaken ties between developers, safety researchers, and investors. This in turn could result in the decrease of belief in developing the first general AI system at the appropriate time. For example, a low belief of fast AGI arrival could result in miscalculating the risks of unsafe AGI deployment by a rogue actor.
Furthermore, two apparent time “chunks” have been identified that also result in significantly different problems that need to be solved. Pre- and Post-AGI era, i.e. before the first general AI is developed, compared to the scenario after someone is in possession of such a technology.
In the workshop, the discussion focused primarily on the pre-AGI era as the AI race avoidance should be a preventative, rather than a curative effort. The first example roadmap (figure 1) presented here covers the pre-AGI era, while the second roadmap (figure 2), created by GoodAI prior to the workshop, focuses on the time around AGI creation.
Viewpoint issue
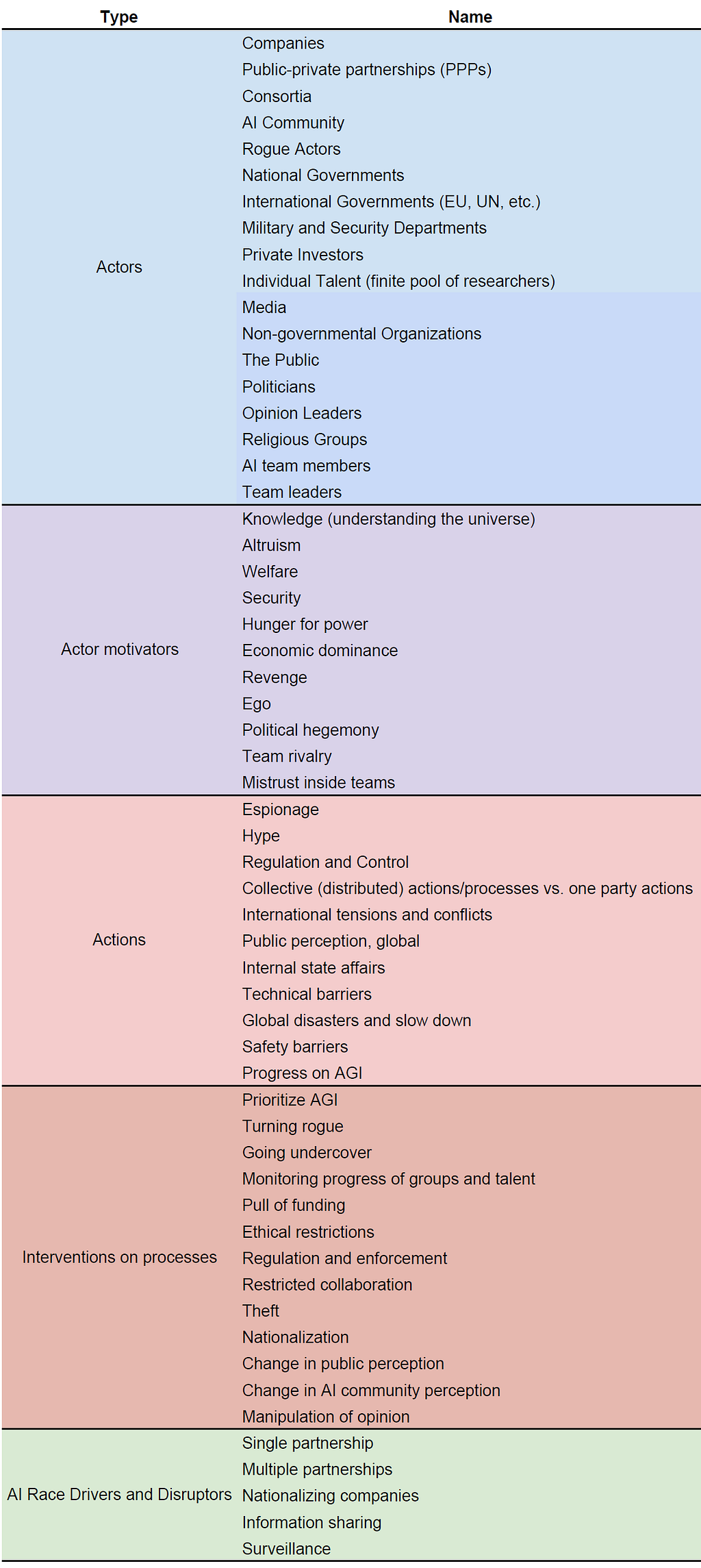
We have identified an extensive (but not exhaustive) list of actors that might participate in the AI race, actions taken by them and by others, as well as the environment in which the race takes place, and states in between which the entire process transitions. Table 1 outlines the identified constituents. Roadmapping the same problem from various viewpoints can help reveal new scenarios and risks.
Modelling and investigating decision dilemmas of various actors frequently led to the fact that cooperation could proliferate applications of AI safety measures and lessen the severity of race dynamics.
Cooperation issue
Cooperation among the many actors, and spirit of trust and cooperation in general, is likely to decrease the race dynamics in the overall system. Starting with a low-stake cooperation among different actors, such as talent co-development or collaboration among safety researchers and industry, should allow for incremental building of trust and better understanding of faced issues.
Active cooperation between safety experts and AI industry leaders, including cooperation between different AI developing companies on the questions of AI safety, for example, is likely to result in closer ties and in a positive information propagation up the chain, leading all the way to regulatory levels. Hands-on approach to safety research with working prototypes is likely to yield better results than theoretical-only argumentation.
One area that needs further investigation in this regard are forms of cooperation that might seem intuitive, but might rather reduce the safety of AI development [1].
Finding incentives to avoid the AI race
It is natural that any sensible developer would want to prevent their AI system from causing harm to its creator and humanity, whether it is a narrow AI or a general AI system. In case of a malignant actor, there is presumably a motivation at least not to harm themselves.
When considering various incentives for safety-focused development, we need to find a robust incentive (or a combination of such) that would push even unknown actors towards beneficial A(G)I, or at least an A(G)I that can be controlled [6].
Tying timescale and cooperation issues together
In order to prevent a negative scenario from happening, it should be beneficial to tie the different time-horizons (anticipated speed of AGI’s arrival) and cooperation together. Concrete problems in AI safety (interpretability, bias-avoidance, etc.) [7] are examples of practically relevant issues that need to be dealt with immediately and collectively. At the same time, the very same issues are related to the presumably longer horizon of AGI development. Pointing out such concerns can promote AI safety cooperation between various developers irrespective of their predicted horizon of AGI creation.
Forms of cooperation that maximize AI safety practice
Encouraging the AI community to discuss and attempt to solve issues such as AI race is necessary, however it might not be sufficient. We need to find better and stronger incentives to involve actors from a wider spectrum that go beyond actors traditionally associated with developing AI systems. Cooperation can be fostered through many scenarios, such as:
AI safety research is done openly and transparently,
Access to safety research is free and anonymous: anyone can be assisted and can draw upon the knowledge base without the need to disclose themselves or what they are working on, and without fear of losing a competitive edge (a kind of “AI safety helpline”),
Alliances are inclusive towards new members,
New members are allowed and encouraged to enter global cooperation programs and alliances gradually, which should foster robust trust building and minimize burden on all parties involved. An example of gradual inclusion in an alliance or a cooperation program is to start cooperating on low-stake issues from economic competition point of view, as noted above.
Closing remarks — continuing the work on AI race avoidance
In this post we have outlined our first steps on tackling the AI race. We welcome you to join in the discussion and help us to gradually come up with ways how to minimize the danger of converging to a state in which this could be an issue.
The AI Roadmap Institute will continue to work on AI race roadmapping, identifying further actors, recognizing yet unseen perspectives, time scales and horizons, and searching for risk mitigation scenarios. We will continue to organize workshops to discuss these ideas and publish roadmaps that we create. Eventually we will help build and launch the AI Race Avoidance round of the General AI Challenge. Our aim is to engage the wider research community and to provide it with a sound background to maximize the possibility of solving this difficult problem.
Stay tuned, or even better, join in now.
About the General AI Challenge and its AI Race Avoidance round
The General AI Challenge (Challenge for short) is a citizen science project organized by general artificial intelligence R&D company GoodAI. GoodAI provided a $5mil fund to be given out in prizes throughout various rounds of the multi-year Challenge. The goal of the Challenge is to incentivize talent to tackle crucial research problems in human-level AI development and to speed up the search for safe and beneficial general artificial intelligence.
The independent AI Roadmap Institute, founded by GoodAI, collaborates with a number of other organizations and researchers on various A(G)I related issues including AI safety. The Institute’s mission is to accelerate the search for safe human-level artificial intelligence by encouraging, studying, mapping and comparing roadmaps towards this goal. The AI Roadmap Institute is currently helping to define the second round of the Challenge, AI Race Avoidance, dealing with the question of AI race avoidance (set to launch in late 2017).
Participants of the second round of the Challenge will deliver analyses and/or solutions to the problem of AI race avoidance. Their submissions will be evaluated in a two-phase evaluation process: through a) expert acceptance and b) business acceptance. The winning submissions will receive monetary prizes, provided by GoodAI.
Expert acceptance
The expert jury prize will be awarded for an idea, concept, feasibility study, or preferably an actionable strategy that shows the most promise for ensuring safe development and avoiding rushed deployment of potentially unsafe A(G)I as a result of market and competition pressure.
Business acceptance
Industry leaders will be invited to evaluate top 10 submissions from the expert jury prize and possibly a few more submissions of their choice (these may include proposals which might have a potential for a significant breakthrough while lacking in feasibility criteria)
The business acceptance prize is a way to contribute to establishing a balance between the research and the business communities.
The proposals will be treated under an open licence and will be made public together with the names of their authors. Even in the absence of a “perfect” solution, the goal of this round of the General AI Challenge should be fulfilled by advancing the work on this topic and promoting interest in AI safety across disciplines.
Guest post by José Hernández-Orallo, Professor at Technical University of Valencia
Two decades ago I started working on metrics of machine intelligence. By that time, during the glacial days of the second AI winter, few were really interested in measuring something that AI lacked completely. And very few, such as David L. Dowe and I, were interested in metrics of intelligence linked to algorithmic information theory, where the models of interaction between an agent and the world were sequences of bits, and intelligence was formulated using Solomonoff’s and Wallace’s theories of inductive inference.
In the meantime, seemingly dozens of variants of the Turing test were proposed every year, the CAPTCHAs were introduced and David showed how easy it is to solve some IQ tests using a very simple program based on a big-switch approach. And, today, a new AI spring has arrived, triggered by a blossoming machine learning field, bringing a more experimental approach to AI with an increasing number of AI benchmarks and competitions (see a previous entry in this blog for a survey).
Last year also witnessed the introduction of a different kind of AI evaluation platforms, such as Microsoft’s Malmö, GoodAI’s School, OpenAI’s Gym and Universe, DeepMind’s Lab, Facebook’s TorchCraft and CommAI-env. Based on a reinforcement learning (RL) setting, these platforms make it possible to create many different tasks and connect RL agents through a standard interface. Many of these platforms are well suited for the new paradigms in AI, such as deep reinforcement learning and some open-source machine learning libraries. After thousands of episodes or millions of steps against a new task, these systems are able to excel, with usually better than human performance.
Despite the myriads of applications and breakthroughs that have been derived from this paradigm, there seems to be a consensus in the field that the main open problem lies in how an AI agent can reuse the representations and skills from one task to new ones, making it possible to learn a new task much faster, with a few examples, as humans do. This can be seen as a mapping problem (usually under the term transfer learning) or can be seen as a sequential problem (usually under the terms gradual, cumulative, incremental, continual or curriculum learning).
One of the key notions that is associated with this capability of a system of building new concepts and skills over previous ones is usually referred to as “compositionality”, which is well documented in humans from early childhood. Systems are able to combine the representations, concepts or skills that have been learned previously in order to solve a new problem. For instance, an agent can combine the ability of climbing up a ladder with its use as a possible way out of a room, or an agent can learn multiplication after learning addition.
In my opinion, two of the previous platforms are better suited for compositionality: Malmö and CommAI-env. Malmö has all the ingredients of a 3D game, and AI researchers can experiment and evaluate agents with vision and 3D navigation, which is what many research papers using Malmö have done so far, as this is a hot topic in AI at the moment. However, to me, the most interesting feature of Malmö is building and crafting, where agents must necessarily combine previous concepts and skills in order to create more complex things.
CommAI-env is clearly an outlier in this set of platforms. It is not a video game in 2D or 3D. Video or audio don’t have any role there. Interaction is just produced through a stream of input/output bits and rewards, which are just +1, 0 or -1. Basically, actions and observations are binary. The rationale behind CommAI-env is to give prominence to communication skills, but it still allows for rich interaction, patterns and tasks, while “keeping all further complexities to a minimum”.
Examples of interaction within the CommAI-mini environment.
When I was aware that the General AI Challenge was using CommAI-env for their warm-up round I was ecstatic. Participants could focus on RL agents without the complexities of vision and navigation. Of course, vision and navigation are very important for AI applications, but they create many extra complications if we want to understand (and evaluate) gradual learning. For instance, two equal tasks for which the texture of the walls changes can be seen as requiring higher transfer effort than two slightly different tasks with the same texture. In other words, this would be extra confounding factors that would make the analysis of task transfer and task dependencies much harder. It is then a wise choice to exclude this from the warm-up round. There will be occasions during other rounds of the challenge for including vision, navigation and other sorts of complex embodiment. Starting with a minimal interface to evaluate whether the agents are able to learn incrementally is not only a challenging but an important open problem for general AI.
Also, the warm-up round has modified CommAI-env in such a way that bits are packed into 8-bit (1 byte) characters. This makes the definition of tasks more intuitive and makes the ASCII coding transparent to the agents. Basically, the set of actions and observations is extended to 256. But interestingly, the set of observations and actions is the same, which allows many possibilities that are unusual in reinforcement learning, where these subsets are different. For instance, an agent with primitives such as “copy input to output” and other sequence transformation operators can compose them in order to solve the task. Variables, and other kinds of abstractions, play a key role.
This might give the impression that we are back to Turing machines and symbolic AI. In a way, this is the case, and much in alignment to Turing’s vision in his 1950 paper: “it is possible to teach a machine by punishments and rewards to obey orders given in some language, e.g., a symbolic language”. But in 2017 we have a range of techniques that weren’t available just a few years ago. For instance, Neural Turing Machines and other neural networks with symbolic memory can be very well suited for this problem.
By no means does this indicate that the legion of deep reinforcement learning enthusiasts cannot bring their apparatus to this warm-up round. Indeed they won’t be disappointed by this challenge if they really work hard to adapt deep learning to this problem. They won’t probably need a convolutional network tuned for visual pattern recognition, but there are many possibilities and challenges in how to make deep learning work in a setting like this, especially because the fewer examples, the better, and deep learning usually requires many examples.
As a plus, the simple, symbolic sequential interface opens the challenge to many other areas in AI, not only recurrent neural networks but techniques from natural language processing, evolutionary computation, compression-inspired algorithms or even areas such as inductive programming, with powerful string-handling primitives and its appropriateness for problems with very few examples.
I think that all of the above makes this warm-up round a unique competition. Of course, since we haven’t had anything similar in the past, we might have some surprises. It might happen that an unexpected (or even naïve) technique could behave much better than others (and humans) or perhaps we find that no technique is able to do something meaningful at this time.
I’m eager to see how this round develops and what the participants are able to integrate and invent in order to solve the sequence of micro and mini-tasks. I’m sure that we will learn a lot from this. I hope that machines will, too. And all of us will move forward to the next round!
Guest post by Simon Andersson, Senior Research Scientist @GoodAI
Executive summary
Tracking major unsolved problems in AI can keep us honest about what remains to be achieved and facilitate the creation of roadmaps towards general artificial intelligence.
This document currently identifies 29 open problems.
For each major problem, example tests are suggested for evaluating research progress.
Introduction
This document identifies open problems in AI. It seeks to provide a concise overview of the greatest challenges in the field and of the current state of the art, in line with the “open research questions” theme of focus of the AI Roadmap Institute.
The challenges are grouped into AI-complete problems, closed-domain problems, and fundamental problems in commonsense reasoning, learning, and sensorimotor ability.
I realize that this first attempt at surveying the open problems will necessarily be incomplete and welcome reader feedback.
To help accelerate the search for general artificial intelligence, GoodAI is organizing the General AI Challenge (GoodAI, 2017), that aims to solve some of the problems outlined below, through a series of milestone challenges starting in early 2017.
Sources, method, and related work
The collection of problems presented here is the result of a review of the literature in the areas of
Machine learning
Machine perception and robotics
Open AI problems
Evaluation of AI systems
Tests for the achievement of human-level intelligence
Benchmarks and competitions
To be considered for inclusion, a problem must be
Highly relevant for achieving general artificial intelligence
Closed in scope, not subject to open-ended extension
Testable
Problems vary in scope and often overlap. Some may be contained entirely in others. The second criterion (closed scope) excludes some interesting problems such as learning all human professions; a few problems of this type are mentioned separately from the main list. To ensure that problems are testable, each is presented together with example tests.
Several websites, some listed below, provide challenge problems for AI.
OpenAI Requests for research (OpenAI, 2016) presents machine learning problems of varying difficulty with an emphasis on deep and reinforcement learning.
In the context of evaluating AI systems, Hernández-Orallo (2016a) reviews a number of open AI problems. Lake et al. (2016) offers a critique of the current state of the art in AI and discusses problems like intuitive physics, intuitive psychology, and learning from few examples.
The rest of the document lists AI challenges as outlined below.
AI-complete problems
Closed-domain problems
Commonsense reasoning
Learning
Sensorimotor problems
AI-complete problems
AI-complete problems are ones likely to contain all or most of human-level general artificial intelligence. A few problems in this category are listed below.
Open-domain dialog
Text understanding
Machine translation
Human intelligence and aptitude tests
Coreference resolution (Winograd schemas)
Compound word understanding
Open-domain dialog
Open-domain dialog is the problem of conducting competently a dialog with a human when the subject of the discussion is not known in advance. The challenge includes language understanding, dialog pragmatics, and understanding the world. Versions of the tasks include spoken and written dialog. The task can be extended to include multimodal interaction (e.g., gestural input, multimedia output). Possible success criteria are usefulness and the ability to conduct dialog indistinguishable from human dialog (“Turing test”).
Tests
Dialog systems are typically evaluated by human judges. Events where this has been done include
Text understanding is an unsolved problem. There has been remarkable progress in the area of question answering, but current systems still fail when common-sense world knowledge, beyond that provided in the text, is required.
Tests
McCarthy (1976) provided an early text understanding challenge problem.
Brachman (2006) suggested the problem of reading a textbook and solving its exercises.
Machine translation
Machine translation is AI-complete since it includes problems requiring an understanding of the world (e.g., coreference resolution, discussed below).
Tests
While translation quality can be evaluated automatically using parallel corpora, the ultimate test is human judgement of quality. Corpora such as the Corpus of Contemporary American English (Davies, 2008) contain samples of text from different genres. Translation quality can be evaluated using samples of
Newspaper text
Fiction
Spoken language transcriptions
Intelligence tests
Human intelligence and aptitude tests (Hernández-Orallo, 2017) are interesting in that they are designed to be at the limit of human ability and to be hard or impossible to solve using memorized knowledge. Human-level performance has been reported for Raven’s progressive matrices (Lovett and Forbus, 2017) but artificial systems still lack the general reasoning abilities to deal with a variety of problems at the same time (Hernández-Orallo, 2016b).
Tests
Brachman (2006) suggested using the SAT as an AI challenge problem.
In many languages, there are compound words with set meanings. Novel compound words can be produced, and we are good at guessing their meaning. We understand that a water bird is a bird that lives near water, not a bird that contains or is constituted by water, and that schadenfreude is felt when others, not we, are hurt.
Closed-domain problems are ones that combine important elements of intelligence but reduce the difficulty by limiting themselves to a circumscribed knowledge domain. Game playing agents are examples of this and artificial agents have achieved superhuman performance at Go (Silver et al., 2016) and more recently poker (Aupperlee, 2017; Brown and Sandholm, 2017). Among the open problems are:
Learning to play board, card, and tile games from descriptions
Producing programs from descriptions
Source code understanding
Board, card, and tile games from descriptions
Unlike specialized game players, systems that have to learn new games from descriptions of the rules cannot rely on predesigned algorithms for specific games.
Tests
The problem of learning new games from formal-language descriptions has appeared as a challenge at the AAAI conference (Genesereth et al., 2005; AAAI, 2013).
Even more challenging is the problem of learning games from natural language descriptions; such descriptions for card and tile games are available from a number of websites (e.g., McLeod, 2017).
Programs from descriptions
Producing programs in a programming language such as C from natural language input is a problem of obvious practical interest.
Tests
The “Description2Code” challenge proposed at (OpenAI, 2016) has 5000 descriptions for programs collected by Ethan Caballero.
Source code understanding
Related to source code production is source code understanding, where the system can interpret the semantics of code and detect situations where the code differs in non-trivial ways from the likely intention of its author. Allamanis et al. (2016) reports progress on the prediction of procedure names.
Tests
The International Obfuscated C Code Contest (OCCC, 2016) publishes code that is intentionally hard to understand. Source code understanding could be tested as the ability to improve the readability of the code as scored by human judges.
Commonsense reasoning
Commonsense reasoning is likely to be a central element of general artificial intelligence. Some of the main problems in this area are listed below.
Causal reasoning
Counterfactual reasoning
Intuitive physics
Intuitive psychology
Causal reasoning
Causal reasoning requires recognizing and applying cause-effect relations.
Counterfactual reasoning is required for answering hypothetical questions. It uses causal reasoning together with the system’s other modeling and reasoning capabilities to consider situations possibly different from anything that ever happened in the world.
Despite remarkable advances in machine learning, important learning-related problems remain mostly unsolved. They include:
Gradual learning
Unsupervised learning
Strong generalization
Category learning from few examples
Learning to learn
Compositional learning
Learning without forgetting
Transfer learning
Knowing when you don’t know
Learning through action
Gradual learning
Humans are capable of lifelong learning of increasingly complex tasks. Artificial agents should be, too. Versions of this idea have been discussed under the rubrics of life-long (Thrun and Mitchell, 1995), continual, and incremental learning. At GoodAI, we have adopted the term gradual learning (Rosa et al., 2016) for the long-term accumulation of knowledge and skills. It requires the combination of several abilities discussed below:
Compositional learning
Learning to learn
Learning without forgetting
Transfer learning
Tests
A possible test applies to a household robot that learns household and house maintenance tasks, including obtaining tools and materials for the work. The test evaluates the agent on two criteria: Continuous operation (Nilsson in Brooks, et al., 1996) where the agent needs to function autonomously without reprogramming during its lifetime, and improving capability, where the agent must exhibit, at different points in its evolution, capabilities not present at an earlier time.
Unsupervised learning
Unsupervised learning has been described as the next big challenge in machine learning (LeCun 2016). It appears to be fundamental to human lifelong learning (supervised and reinforcement signals do not provide nearly enough data) and is closely related to prediction and common-sense reasoning (“filling in the missing parts”). A hard problem (Yoshua Bengio, in the “Brains and bits” panel at NIPS 2016) is unsupervised learning in hierarchical systems, with components learning jointly.
Tests
In addition to the possible tests in the vision domain, speech recognition also presents opportunities for unsupervised learning. While current state-of-the-art speech recognizers rely largely on supervised learning on large corpora, unsupervised recognition requires discovering, without supervision, phonemes, word segmentation, and vocabulary. Progress has been reported in this direction, so far limited to small-vocabulary recognition (Riccardi and Hakkani-Tur, 2003, Park and Glass, 2008, Kamper et al., 2016).
A full-scale test of unsupervised speech recognition could be to train on the audio part of a transcribed speech corpus (e.g., TIMIT (Garofolo, 1993)), then learn to predict the transcriptions with only very sparse supervision.
Strong generalization
Humans can transfer knowledge and skills across situations that share high-level structure but are otherwise radically different, adapting to the particulars of a new setting while preserving the essence of the skill, a capacity that (Tarlow, 2016; Gaunt et al., 2016) refer to as strong generalization. If we learn to clean up a room, we know how to clean up most other rooms.
Tests
A general assembly robot could learn to build a toy castle in one material (e.g., lego blocks) and be tested on building it from other materials (sand, stones, sticks).
A household robot could be trained on cleaning and cooking tasks in one environment and be tested in highly dissimilar environments.
Category learning from few examples
Lake et al. (2015) achieved human-level recognition and generation of characters using few examples. However, learning more complex categories from few examples remains an open problem.
Tests
The ImageNet database (Deng et al., 2009) contains images organized by the semantic hierarchy of WordNet (Miller, 1995). Correctly determining ImageNet categories from images with very little training data could be a challenging test of learning from few examples.
Learning to learn
Learning to learn or meta-learning (e.g., Harlow, 1949; Schmidhuber, 1987; Thrun and Pratt, 1998; Andrychowicz et al., 2016; Chen et al., 2016; de Freitas, 2016; Duan et al., 2016; Lake et al., 2016; Wang et al., 2016) is the acquisition of skills and inductive biases that facilitate future learning. The scenarios considered in particular are ones where a more general and slower learning process produces a faster, more specialized one. An example is biological evolution producing efficient learners such as human beings.
Tests
Learning to play Atari video games is an area that has seen some remarkable recent successes, including in transfer learning (Parisotto et al., 2016). However, there is so far no system that first learns to play video games, then is capable of learning a new game, as humans can, from a few minutes of play (Lake et al., 2016).
Compositional learning
Compositional learning (de Freitas, 2016; Lake et al., 2016) is the ability to recombine primitive representations to accelerate the acquisition of new knowledge. It is closely related to learning to learn.
Tests
Tests for compositional learning need to verify both that the learner is effective and that it uses compositional representations.
Some ImageNet categories correspond to object classes defined largely by their arrangements of component parts, e.g., chairs and stools, or unicycles, bicycles, and tricycles. A test could evaluate the agent’s ability to learn categories with few examples and to report the parts of the object in an image.
Compositional learning should be extremely helpful in learning video games (Lake et al., 2016). A learner could be tested on a game already mastered, but where component elements have changed appearance (e.g., different-looking fish in the Frostbite game). It should be able to play the variant game with little or no additional learning.
Learning without forgetting
In order to learn continually over its lifetime, an agent must be able to generalize over new observations while retaining previously acquired knowledge. Recent progress towards this goal is reported in (Kirkpatrick et al., 2016) and (Li and Hoiem, 2016). Work on memory augmented neural networks (e.g., Graves et al., 2016) is also relevant.
Tests
A test for learning without forgetting needs to present learning tasks sequentially (earlier tasks are not repeated) and test for retention of early knowledge. It may also test for declining learning time for new tasks, to verify that the agent exploits the knowledge acquired so far.
A challenging test for learning without forgetting would be to learn to recognize all the categories in ImageNet, presented sequentially.
Transfer learning
Transfer learning (Pan and Yang, 2010) is the ability of an agent trained in one domain to master another. Results in the area of text comprehension are currently poor unless the agent is given some training on the new domain (Kadlec, et al., 2016).
Tests
Sentiment classification (Blitzer et al., 2007) provides a possible testing ground for transfer learning. Learners can be trained on one corpus, tested on another, and compared to a baseline learner trained directly on the target domain.
Reviews of movies and of businesses are two domains dissimilar enough to make knowledge transfer challenging. Corpora for the domains are Rotten Tomatoes movie reviews (Pang and Lee, 2005) and the Yelp Challenge dataset (Yelp, 2017).
Knowing when you don’t know
While uncertainty is modeled differently by different learning algorithms, it seems to be true in general that current artificial systems are not nearly as good as humans at “knowing when they don’t know.” An example are deep neural networks that achieve state-of-the-art accuracy on image recognition but assign 99.99% confidence to the presence of objects in images completely unrecognizable to humans (Nguyen et al., 2015).
Human performance on confidence estimation would include
In induction tasks, like program induction or sequence completion, knowing when the provided examples are insufficient for induction (multiple reasonable hypotheses could account for them)
In speech recognition, knowing when an utterance has not been interpreted reliably
In visual tasks such as pedestrian detection, knowing when a part of the image has not been analyzed reliably
Tests
A speech recognizer can be compared against a human baseline, measuring the ratio of the average confidence to the confidence on examples where recognition fails.
The confidence of image recognition systems can be tested on generated adversarial examples.
Learning through action
Human infants are known to learn about the world through experiments, observing the effects of their own actions (Smith and Gasser, 2005; Malik, 2015). This seems to apply both to higher-level cognition and perception. Animal experiments have confirmed that the ability to initiate movement is crucial to perceptual development (Held and Hein, 1963) and some recent progress has been made on using motion in learning visual perception (Agrawal et al., 2015). In (Agrawal et al., 2016), a robot learns to predict the effects of a poking action.
“Learning through action” thus encompasses several areas, including
Active learning, where the agent selects the training examples most likely to be instructive
Undertaking epistemological actions, i.e., activities aimed primarily at gathering information
Learning to perceive through action
Learning about causal relationships through action
Perhaps most importantly, for artificial systems, learning the causal structure of the world through experimentation is still an open problem.
Tests
For learning through action, it is natural to consider problems of motor manipulation where in addition to the immediate effects of the agent’s actions, secondary effects must be considered as well.
Learning to play billiards: An agent with little prior knowledge and no fixed training data is allowed to explore a real or virtual billiard table and should learn to play billiards well.
Sensorimotor problems
Outstanding problems in robotics and machine perception include:
Autonomous navigation in dynamic environments
Scene analysis
Robust general object recognition and detection
Robust, life-time simultaneous location and mapping (SLAM)
Multimodal integration
Adaptive dexterous manipulation
Autonomous navigation
Despite recent progress in self-driving cars by companies like Tesla, Waymo (formerly the Google self-driving car project) and many others, autonomous navigation in highly dynamic environments remains a largely unsolved problem, requiring knowledge of object semantics to reliably predict future scene states (Ess et al., 2010).
Tests
Fully automatic driving in crowded city streets and residential areas is still a challenging test for autonomous navigation.
Scene analysis
The challenge of scene analysis extends far beyond object recognition and includes the understanding of surfaces formed by multiple objects, scene 3D structure, causal relations (Lake et al., 2016), and affordances. It is not limited to vision but can depend on audition, touch, and other modalities, e.g., electroreception and echolocation (Lewicki et al., 2014; Kondo et al., 2017). While progress has been made, e.g., in recognizing anomalous and improbable scenes (Choi et al., 2012), predicting object dynamics (Fouhey and Zitnick, 2014), and discovering object functionality (Yao et al., 2013), we are still far from human-level performance in this area.
Tests
Some possible challenges for understanding the causal structure in visual scenes are:
Recognizing dangerous situations: A corpus of synthetic images could be created where the same objects are recombined to form “dangerous” and “safe” scenes as classified by humans.
Recognizing physically improbable scenes: A synthetic corpus could be created to show physically plausible and implausible scenes containing the same objects.
Recognizing useless objects: Images of useless objects have been created by (Kamprani, 2017).
Object recognition
While object recognition has seen great progress in recent years (e.g., Han et al., 2016), matches or surpasses human performance for many problems (Karpathy, 2014), and can approach perfection in closed environments (Song et al., 2015), state-of-the-art systems still struggle with the harder cases such as open objects (interleaved with background), broken objects, truncation and occlusion in dynamic environments (e.g., Rajaram et al., 2015).
Tests
Environments that are cluttered and contain objects drawn from a large, open-ended, and changing set of types are likely to be challenging for an object recognition system. An example would be
Seeing photos of the insides of pantries and refrigerators and listing the ingredients available to the owners
Simultaneous location and mapping
While the problem of simultaneous location and mapping (SLAM) is considered solved for some applications, the challenge of SLAM for long-lived autonomous robots, in large-scale, time-varying environments, remains open (Cadena et al., 2016).
Tests
Lifetime location and mapping, without detailed maps provided in advance and robust to changes in the environment, for an autonomous car based in a large city
Multimodal integration
The integration of multiple senses (Lahat, 2015) is important, e.g., in human communication (Morency, 2015) and scene understanding (Lewicki et al., 2014; Kondo et al., 2017). Having multiple overlapping sensory systems seems to be essential for enabling human children to educate themselves by perceiving and acting in the world (Smith and Gasser, 2005).
Tests
Spoken communication in noisy environments, where lip reading and gestural cues are indispensable, can provide challenges for multimodal fusion. An example would be
A robot bartender: The agent needs to interpret customer requests in a noisy bar.
Adaptive dexterous manipulation
Current robot manipulators do not come close to the versatility of the human hand (Ciocarlie, 2015). Hard problems include manipulating deformable objects and operating from a mobile platform.
Tests
Taking out clothes from a washing machine and hanging them on clothes lines and coat hangers in varied places while staying out of the way of humans
Open-ended problems
Some noteworthy problems were omitted from the list for having a too open-ended scope: they encompass sets of tasks that evolve over time or can be endlessly extended. This makes it hard to decide whether a problem has been solved. Problems of this type include
Enrolling in a human university and take classes like humans (Goertzel, 2012)
Automating all types of human work (Nilsson, 2005)
Puzzlehunt challenges, e.g., the annual TMOU game in the Czech republic (TMOU, 2016)
Conclusion
I have reviewed a number of open problems in an attempt to delineate the current front lines of AI research. The problem list in this first version, as well as the problem descriptions, example tests, and mentions of ongoing work in the research areas, are necessarily incomplete. I plan to extend and improve the document incrementally and warmly welcome suggestions either in the comment section below or at the institute’s discourse forum.
Acknowledgements
I thank Jan Feyereisl, Martin Poliak, Petr Dluhoš, and the rest of the GoodAI team for valuable discussion and suggestions.
Agrawal, Pulkit, Joao Carreira, and Jitendra Malik. “Learning to see by moving.” Proceedings of the IEEE International Conference on Computer Vision. 2015.
Agrawal, Pulkit, et al. “Learning to poke by poking: Experiential learning of intuitive physics.” arXiv preprint arXiv:1606.07419 (2016).
AI•ON. “The AI•ON collection of open research problems.” Online under http://ai-on.org/projects(2016)
Allamanis, Miltiadis, Hao Peng, and Charles Sutton. “A convolutional attention network for extreme summarization of source code.” arXiv preprint arXiv:1602.03001 (2016).
Andrychowicz, Marcin, et al. “Learning to learn by gradient descent by gradient descent.” Advances in Neural Information Processing Systems. 2016.
Blitzer, John, Mark Dredze, and Fernando Pereira. “Biographies, bollywood, boom-boxes and blenders: Domain adaptation for sentiment classification.” ACL. Vol. 7. 2007.
Brachman, Ronald J. “AI more than the sum of its parts.” AI Magazine 27.4 (2006): 19.
Brooks, R., et al. “Challenge problems for artificial intelligence.” Thirteenth National Conference on Artificial Intelligence-AAAI. 1996.
Cadena, Cesar, et al. “Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age.” IEEE Transactions on Robotics 32.6 (2016): 1309–1332.
Chang, Michael B., et al. “A compositional object-based approach to learning physical dynamics.” arXiv preprint arXiv:1612.00341 (2016).
Chen, Yutian, et al. “Learning to Learn for Global Optimization of Black Box Functions.” arXiv preprint arXiv:1611.03824 (2016).
Choi, Myung Jin, Antonio Torralba, and Alan S. Willsky. “Context models and out-of-context objects.” Pattern Recognition Letters 33.7 (2012): 853–862.
de Freitas, Nando. “Learning to Learn and Compositionality with Deep Recurrent Neural Networks: Learning to Learn and Compositionality.” Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 2016.
Degrave, Jonas, Michiel Hermans, and Joni Dambre. “A Differentiable Physics Engine for Deep Learning in Robotics.” arXiv preprint arXiv:1611.01652 (2016).
Deng, Jia, et al. “Imagenet: A large-scale hierarchical image database.” Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on. IEEE, 2009.
Denil, Misha, et al. “Learning to Perform Physics Experiments via Deep Reinforcement Learning.” arXiv preprint arXiv:1611.01843 (2016).
Duan, Yan, et al. “RL²: Fast Reinforcement Learning via Slow Reinforcement Learning.” arXiv preprint arXiv:1611.02779 (2016).
Ess, Andreas, et al. “Object detection and tracking for autonomous navigation in dynamic environments.” The International Journal of Robotics Research 29.14 (2010): 1707–1725.
Finn, Chelsea, and Sergey Levine. “Deep Visual Foresight for Planning Robot Motion.” arXiv preprint arXiv:1610.00696 (2016).
Fouhey, David F., and C. Lawrence Zitnick. “Predicting object dynamics in scenes.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2014.
Fragkiadaki, Katerina, et al. “Learning visual predictive models of physics for playing billiards.” arXiv preprint arXiv:1511.07404 (2015).
Garofolo, John, et al. “TIMIT Acoustic-Phonetic Continuous Speech Corpus LDC93S1.” Web Download. Philadelphia: Linguistic Data Consortium, 1993.
Gaunt, Alexander L., et al. “Terpret: A probabilistic programming language for program induction.” arXiv preprint arXiv:1608.04428 (2016).
Genesereth, Michael, Nathaniel Love, and Barney Pell. “General game playing: Overview of the AAAI competition.” AI magazine 26.2 (2005): 62.
Graves, Alex, et al. “Hybrid computing using a neural network with dynamic external memory.” Nature 538.7626 (2016): 471–476.
Hamrick, Jessica B., et al. “Imagination-Based Decision Making with Physical Models in Deep Neural Networks.” Online under http://phys.csail.mit.edu/papers/5.pdf(2016)
Han, Dongyoon, Jiwhan Kim, and Junmo Kim. “Deep Pyramidal Residual Networks.” arXiv preprint arXiv:1610.02915 (2016).
Harlow, Harry F. “The formation of learning sets.” Psychological review 56.1 (1949): 51.
Held, Richard, and Alan Hein. “Movement-produced stimulation in the development of visually guided behavior.” Journal of comparative and physiological psychology 56.5 (1963): 872.
Hernández-Orallo, José. “Evaluation in artificial intelligence: from task-oriented to ability-oriented measurement.” Artificial Intelligence Review(2016a): 1–51.
Hernández-Orallo, José, et al. “Computer models solving intelligence test problems: progress and implications.” Artificial Intelligence 230 (2016b): 74–107.
Hernández-Orallo, José. “The measure of all minds.” Cambridge University Press, 2017.
IOCCC. “The International Obfuscated C Code Contest.” Online under http://www.ioccc.org(2016)
Kadlec, Rudolf, et al. “Finding a jack-of-all-trades: an examination of semi-supervised learning in reading comprehension.” Under review at ICLR 2017, online under https://openreview.net/pdf?id=rJM69B5xx
Kamper, Herman, Aren Jansen, and Sharon Goldwater. “Unsupervised word segmentation and lexicon discovery using acoustic word embeddings.” IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP) 24.4 (2016): 669–679.
Kirkpatrick, James, et al. “Overcoming catastrophic forgetting in neural networks.” arXiv preprint arXiv:1612.00796 (2016).
Kondo, H. M., et al. “Auditory and visual scene analysis: an overview.” Philosophical transactions of the Royal Society of London. Series B, Biological sciences 372.1714 (2017).
Lahat, Dana, Tülay Adali, and Christian Jutten. “Multimodal data fusion: an overview of methods, challenges, and prospects.” Proceedings of the IEEE 103.9 (2015): 1449–1477.
Lake, Brenden M., Ruslan Salakhutdinov, and Joshua B. Tenenbaum. “Human-level concept learning through probabilistic program induction.” Science 350.6266 (2015): 1332–1338.
Lake, Brenden M., et al. “Building machines that learn and think like people.” arXiv preprint arXiv:1604.00289 (2016).
Lewicki, Michael S., et al. “Scene analysis in the natural environment.” Frontiers in psychology 5 (2014): 199.
Li, Wenbin, Aleš Leonardis, and Mario Fritz. “Visual stability prediction and its application to manipulation.” arXiv preprint arXiv:1609.04861 (2016).
Li, Zhizhong, and Derek Hoiem. “Learning without forgetting.” European Conference on Computer Vision. Springer International Publishing, 2016.
McLeod, John. “Card game rules — card games and tile games from around the world.” Online under https://www.pagat.com (2017)
Miller, George A. “WordNet: a lexical database for English.” Communications of the ACM 38.11 (1995): 39–41.
Mottaghi, Roozbeh, et al. ““What happens if…” Learning to Predict the Effect of Forces in Images.” European Conference on Computer Vision. Springer International Publishing, 2016.
Nair, Ashvin, et al. “Combining Self-Supervised Learning and Imitation for Vision-Based Rope Manipulation.” Online under http://phys.csail.mit.edu/papers/15.pdf (2016)
Nguyen, Anh, Jason Yosinski, and Jeff Clune. “Deep neural networks are easily fooled: High confidence predictions for unrecognizable images.” 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, 2015.
Nilsson, Nils J. “Human-level artificial intelligence? Be serious!.” AI magazine 26.4 (2005): 68.
Pan, Sinno Jialin, and Qiang Yang. “A survey on transfer learning.” IEEE Transactions on knowledge and data engineering 22.10 (2010): 1345–1359.
Pang, Bo, and Lillian Lee. “Seeing stars: Exploiting class relationships for sentiment categorization with respect to rating scales.” Proceedings of the 43rd annual meeting on association for computational linguistics. Association for Computational Linguistics, 2005.
Parisotto, Emilio, Jimmy Lei Ba, and Ruslan Salakhutdinov. “Actor-mimic: Deep multitask and transfer reinforcement learning.” arXiv preprint arXiv:1511.06342 (2015).
Park, Alex S., and James R. Glass. “Unsupervised pattern discovery in speech.” IEEE Transactions on Audio, Speech, and Language Processing 16.1 (2008): 186–197.
Rajaram, Rakesh Nattoji, Eshed Ohn-Bar, and Mohan M. Trivedi. “An exploration of why and when pedestrian detection fails.” 2015 IEEE 18th International Conference on Intelligent Transportation Systems. IEEE, 2015.
Riccardi, Giuseppe, and Dilek Z. Hakkani-Tür. “Active and unsupervised learning for automatic speech recognition.” Interspeech. 2003.
Rosa, Marek, Jan Feyereisl, and The GoodAI Collective. “A Framework for Searching for General Artificial Intelligence.” arXiv preprint arXiv:1611.00685 (2016).
Schmidhuber, Jurgen. “Evolutionary principles in self-referential learning.” On learning how to learn: The meta-meta-… hook.) Diploma thesis, Institut f. Informatik, Tech. Univ. Munich (1987).
Silver, David, et al. “Mastering the game of Go with deep neural networks and tree search.” Nature 529.7587 (2016): 484–489.
Smith, Linda, and Michael Gasser. “The development of embodied cognition: Six lessons from babies.” Artificial life 11.1–2 (2005): 13–29.
Song, Shuran, Linguang Zhang, and Jianxiong Xiao. “Robot in a room: Toward perfect object recognition in closed environments.” CoRR (2015).
Stewart, Russell, and Stefano Ermon. “Label-free supervision of neural networks with physics and domain knowledge.” arXiv preprint arXiv:1609.05566 (2016).
Verschae, Rodrigo, and Javier Ruiz-del-Solar. “Object detection: current and future directions.” Frontiers in Robotics and AI 2 (2015): 29.
Wang, Jane X., et al. “Learning to reinforcement learn.” arXiv preprint arXiv:1611.05763 (2016).
Yao, Bangpeng, Jiayuan Ma, and Li Fei-Fei. “Discovering object functionality.” Proceedings of the IEEE International Conference on Computer Vision. 2013.
Guest post by Martin Stránský, Research Scientist @GoodAI
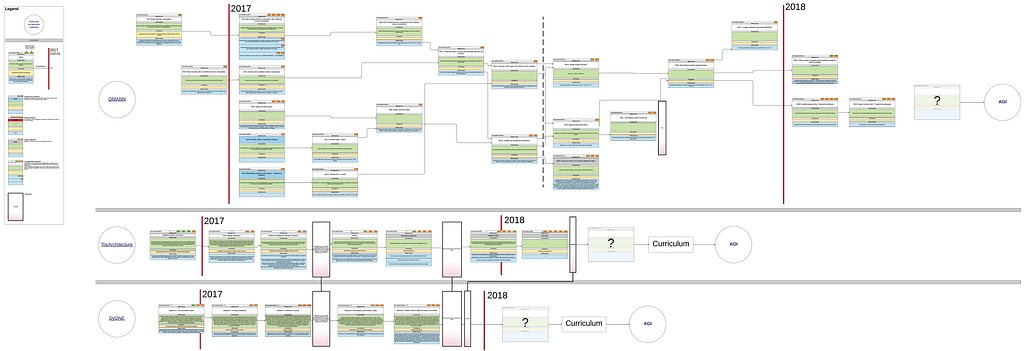
Figure 1. GoodAI architecture development roadmap comparison (full-size)
Recent progress in artificial intelligence, especially in the area of deep learning, has been breath-taking. This is very encouraging for anyone interested in the field, yet the true progress towards human-level artificial intelligence is much harder to evaluate.
The evaluation of artificial intelligence is a very difficult problem for a number of reasons. For example, the lack of consensus on the basic desiderata necessary for intelligent machines is one of the primary barriers to the development of unified approaches towards comparing different agents. Despite a number of researchers specifically focusing on this topic (e.g. José Hernández-Orallo or Kristinn R. Thórisson to name a few), the area would benefit from more attention from the AI community.
Methods for evaluating AI are important tools that help to assess the progress of already built agents. The comparison and evaluation of roadmaps and approaches towards building such agents is however less explored. Such comparison is potentially even harder, due to the vagueness and limited formal definitions within such forward-looking plans.
Nevertheless, we believe that in order to steer towards promising areas of research and to identify potential dead-ends, we need to be able to meaningfully compare existing roadmaps. Such comparison requires the creation of a framework that defines processes on how to acquire important and comparable information from existing documents outlining their respective roadmaps. Without such a unified framework, each roadmap might not only differ in its target (e.g. general AI, human-level AI, conversational AI, etc…) but also in its approaches towards achieving that goal that might be impossible to compare and contrast.
This post offers a glimpse of how we, at GoodAI, are starting to look at this problem internally (comparing the progress of our three architecture teams), and how this might scale to comparisons across the wider community. This is still very much a work-in-progress, but we believe it might be beneficial to share these initial thoughts with the community, to start the discussion about, what we believe, is an important topic.
Overview
In the first part of this article, a comparison of three GoodAI architecture development roadmaps is presented and a technique for comparing them is discussed. The main purpose is to estimate the potential and completeness of plans for every architecture to be able to direct our effort to the most promising one.
To manage adding roadmaps from other teams we have developed a general plan of human-level AI development called a meta-roadmap. This meta-roadmap consists of 10 steps which must be passed in order to reach an ‘ultimate’ target. We hope that most of the potentially disparate plans solve one or more problems identified in the meta-roadmap.
Next, we tried to compare our approaches with that of Mikolov et. al by assigning the current documents and open tasks to problems in the meta-roadmap. We found that useful, as it showed us what is comparable and that different techniques of comparison are needed for every problem.
Architecture development plans comparison
Three teams from GoodAI have been working on their architectures for a few months. Now we need a method to measure the potential of the architectures to be able to, for example, direct our effort more efficiently by allocating more resources to the team with the highest potential. We know that determining which way is the most promising based on the current state is still not possible, so we asked the teams working on unfinished architectures to create plans for future development, i.e. to create their roadmaps.
Based on the provided responses, we have iteratively unified requirements for those plans. After numerous discussions, we came up with the following structure:
A Unit of a plan is called a milestone and describes some piece of work on a part of the architecture (e.g. a new module, a different structure, an improvement of a module by adding functionality, tuning parameters etc.)
Each milestone contains — Time Estimate, i.e. expected time spent on milestone assuming current team size, Characteristicof work or new features and Test of new features.
A plan can be interrupted by checkpoints which serve as common tests for two or more architectures.
Now we have a set of basic tools to monitor progress:
We will see whether a particular team will achieve their self-designed tests and thereby can fulfill their original expectations on schedule.
Due to checkpoints it is possible to compare architectures in the middle of development.
We can see how far a team sees. Ideally after finishing the last milestone, the architecture should be prepared to pass through a curriculum (which will be developed in the meantime) and a final test afterwards.
Total time estimates. We can compare them as well.
We are still working on a unified set (among GoodAI architectures) of features which we will require from an architecture (desiderata for an architecture).
The particular plans were placed side by side (c.f. Figure 1) and a few checkpoints were (currently vaguely) defined. As we can see, teams have rough plans of their work for more than one year ahead, still the plans are not complete in a sense that the architectures will not be ready for any curriculum. Two architectures use a connectivist approach and they are easy to compare. The third, OMANN, manipulates symbols, thus from the beginning it can perform tasks which are hard for the other two architectures and vice versa. This means that no checkpoints for OMANN have been defined yet. We see a lack of common tests as a serious issue with the plan and are looking for changes to make the architecture more comparable with the others, although it may cause some delays with the development.
There was an effort to include another architecture in the comparison, but we have not been able to find a document describing future work in such detail, with the exception of Weston’s et al. paper. After further analysis, we determined that the paper was focused on a slightly different problem than the development of an architecture. We will address this later in the post.
Assumptions for a common approach
We would like to take a look at the problem from the perspective of the unavoidable steps required to develop an intelligent agent. First we must make a few assumptions about the whole process. We realize that these are somewhat vague — we want to make them acceptable to other AI researchers.
A target is to produce a software (referred to as an architecture), which can be a part of some agent in some world.
In the world there will be tasks that the agent should solve, or a reward based on world states that the agent should seek.
An intelligent agent can adapt to an unknown/changing environment and solve previously unseen tasks.
To check whether the ultimate goal was reached (no matter how defined), every approach needs some well defined final test, which shows how intelligent the agent is (preferably compared to humans).
Before the agent is able to pass their final test, there must be a learning phase in order to teach the agent all necessary skills or abilities. If there is a possibility that the agent can pass the final test without learning anything, the final test is insufficient with respect to point 3. Description of the learning phase (which can include also a world description) is called curriculum.
Meta-roadmap
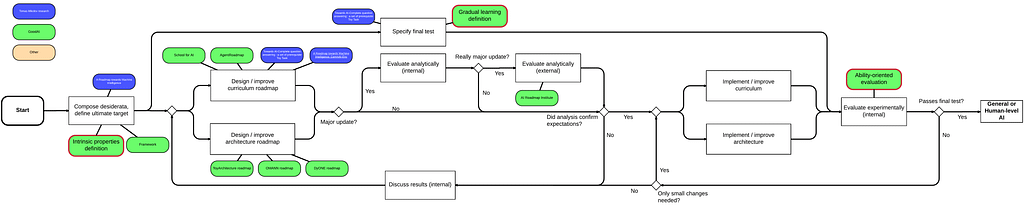
Using the above assumptions (and a few more obvious ones which we won’t enumerate here) we derive Figure 2 describing the list of necessary steps and their order. We call this diagram a meta-roadmap.
The most important and imminent tasks in the diagram are
The definition of an ultimate target,
A final test specification,
The proposed design of a curriculum, and
A roadmapfor the development of an architecture.
We think that the majority of current approaches solve one or more of these open problems; from different points of view according to an ultimate target and beliefs of authors. In order to make the effort more clear, we will divide approaches described in published papers into groups according to the problem that they solve and compare them within those groups. Of course, approaches are hard to compare among groups (yet it is not impossible, for example final test can be comparable to a curriculum under specific circumstances). Even within one group it can be very hard in some situations, where requirements (which are the first thing that should be defined according to our diagram) differ significantly.
Also an analysis of complexity and completeness of an approach can be made within this framework. For example, if a team omits one or more of the open problems, it indicates that the team may not have considered that particular issue and are proceeding without a complete notion of the ‘big picture’.
Problem assignment
We would like to show an attempt to assign approaches to problems and compare them. First, we have analyzed GoodAI’s and Mikolov/Weston’s approach as the latter is well described. You can see the result in Figure 3 below.
Figure 3. Meta-roadmap with incorporated desiderata for different roadmaps (full-size)
As the diagram suggests, we work on a few common problems. We will not provide the full analysis here, but will make several observations to demonstrate the meaningfulness of the meta-roadmap. In desiderata, according to Mikolov’s “A Roadmap towards Machine Intelligence”, a target is an agent which can understand human language. In contrast with the GoodAI approach, other modalities than text are not considered as important. In the curriculum, GoodAI wants to teach an agent in a more anthropocentric way — visual input first, language later — while the entirety of Weston’s curriculum comprises of language-oriented tasks.
Mikolov et al. do not provide a development plan for their architecture, so we can compare their curriculum roadmap to ours, but it is not possible to include their desiderata into the diagram in Figure 1.
Conclusion
We have presented our meta-roadmap and a comparison of three GoodAI development roadmaps. We hope that this post will offer a glimpse into how we started this process at GoodAI and will invigorate a discussion on how this could be improved and scaled beyond internal comparisons. We will be glad to receive any feedback — the generality of our meta-roadmap should be discussed further, as well as our methods for estimating roadmap completeness and their potential to achieve human-level AI.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}