By Oleh Rybkin, Danijar Hafner and Deepak Pathak
To operate successfully in unstructured open-world environments, autonomous intelligent agents need to solve many different tasks and learn new tasks quickly. Reinforcement learning has enabled artificial agents to solve complex tasks both in simulation and real-world. However, it requires collecting large amounts of experience in the environment for each individual task.
Self-supervised reinforcement learning has emerged as an alternative, where the agent only follows an intrinsic objective that is independent of any individual task, analogously to unsupervised representation learning. After acquiring general and reusable knowledge about the environment through self-supervision, the agent can adapt to specific downstream tasks more efficiently.
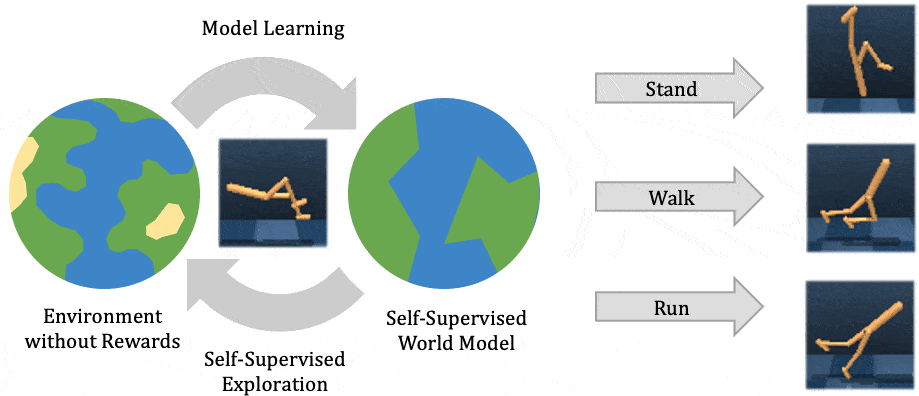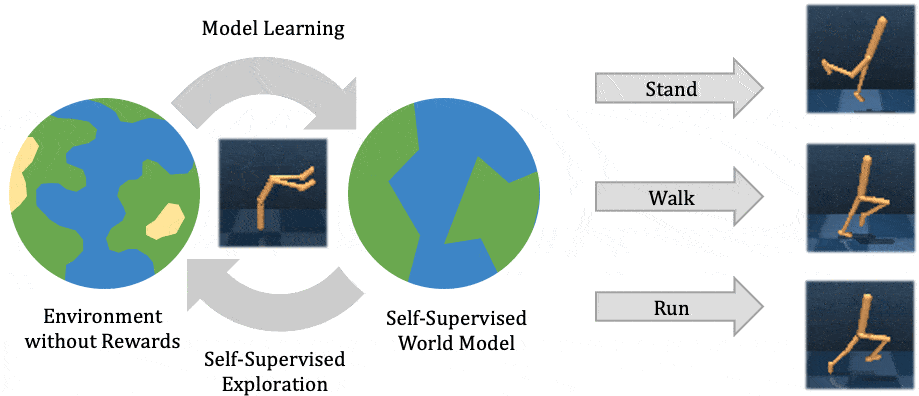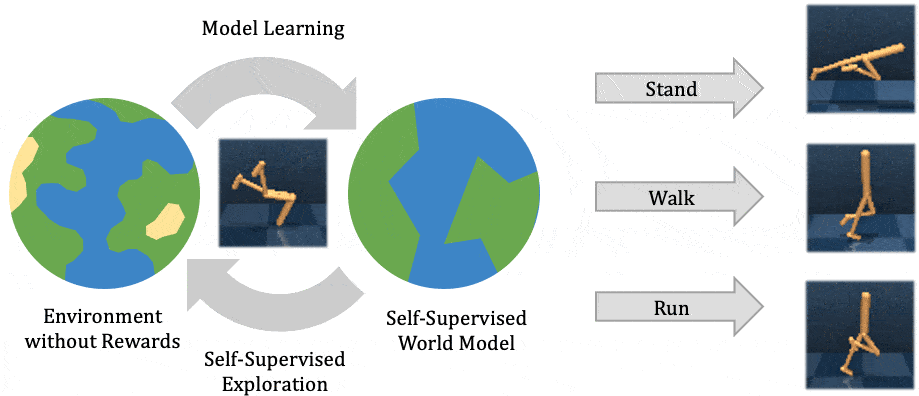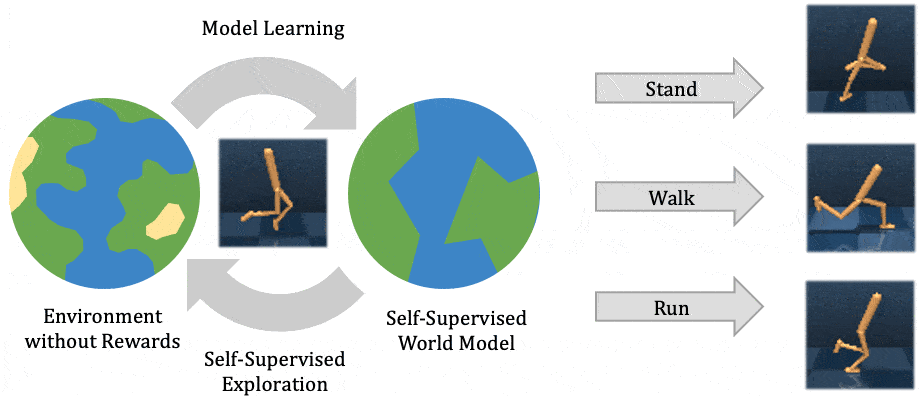
In this post, we explain our recent publication that develops Plan2Explore. While many recent papers on self-supervised reinforcement learning have focused on model-free agents, our agent learns an internal world model that predicts the future outcomes of potential actions. The world model captures general knowledge, allowing Plan2Explore to quickly solve new tasks through planning in its own imagination. The world model further enables the agent to explore what it expects to be novel, rather than repeating what it found novel in the past. Plan2Explore obtains state-of-the-art zero-shot and few-shot performance on continuous control benchmarks with high-dimensional input images. To make it easy to experiment with our agent, we are open-sourcing the complete source code.
How does Plan2Explore work?
At a high level, Plan2Explore works by training a world model, exploring to maximize the information gain for the world model, and using the world model at test time to solve new tasks (see figure above). Thanks to effective exploration, the learned world model is general and captures information that can be used to solve multiple new tasks with no or few additional environment interactions. We discuss each part of the Plan2Explore algorithm individually below. We assume a basic understanding of reinforcement learning in this post and otherwise recommend these materials as an introduction.
Learning the world model
Plan2Explore learns a world model that predicts future outcomes given past observations $o_{1:t}$ and actions $a_{1:t}$ (see figure below). To handle high-dimensional image observations, we encode them into lower-dimensional features $h$ and use an RSSM model that predicts forward in a compact latent state-space $s$, from which the observations can be decoded. The latent state aggregates information from past observations that is helpful for future prediction, and is learned end-to-end using a variational objective.

A novelty metric for active model-building
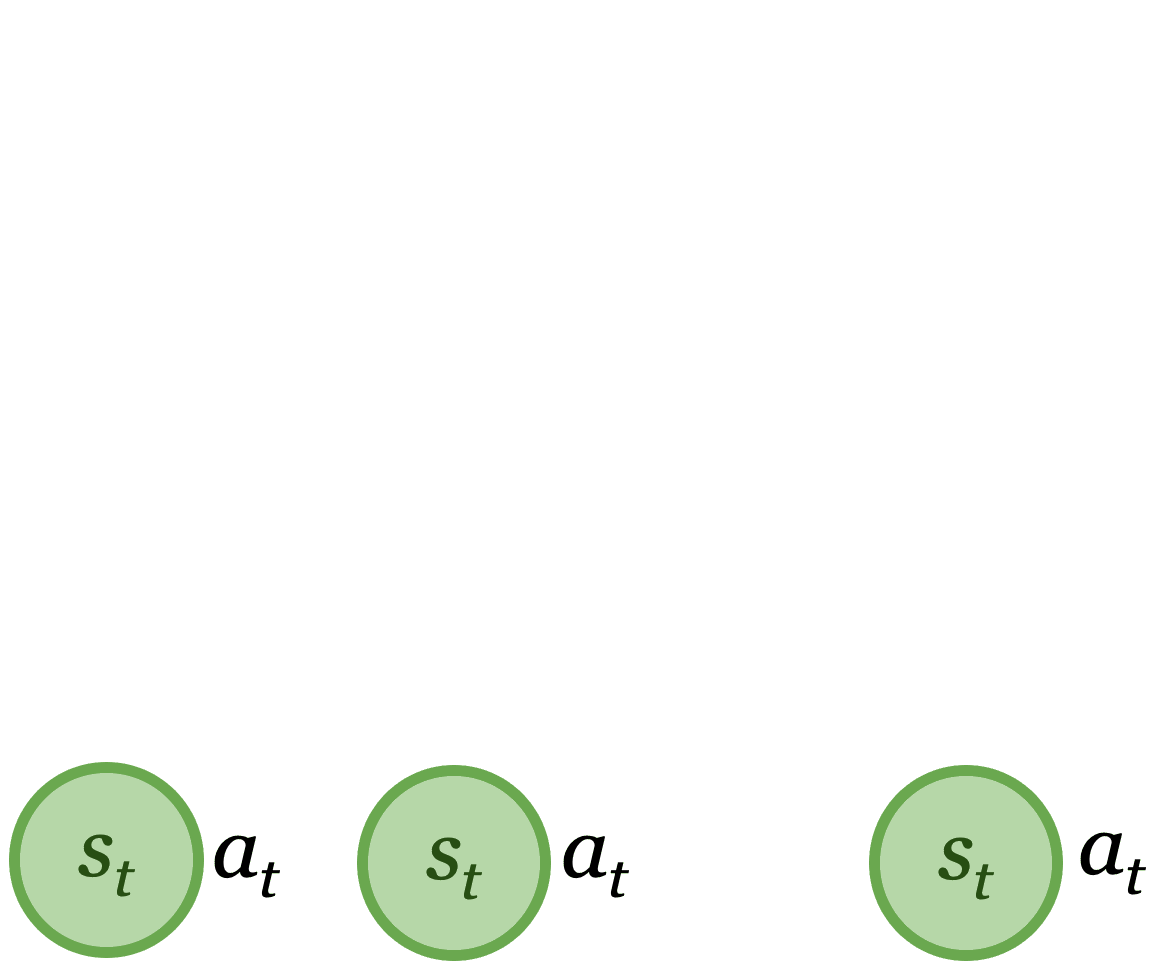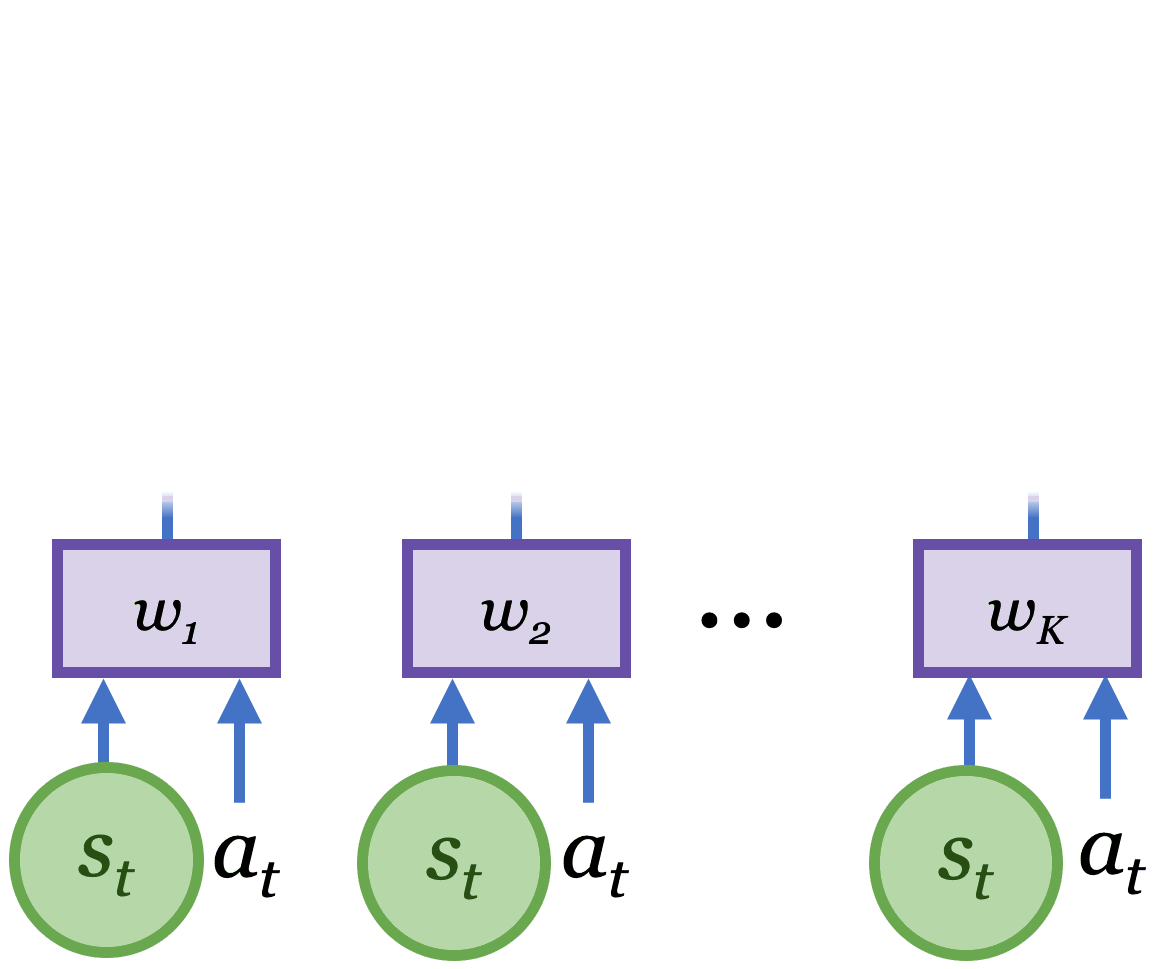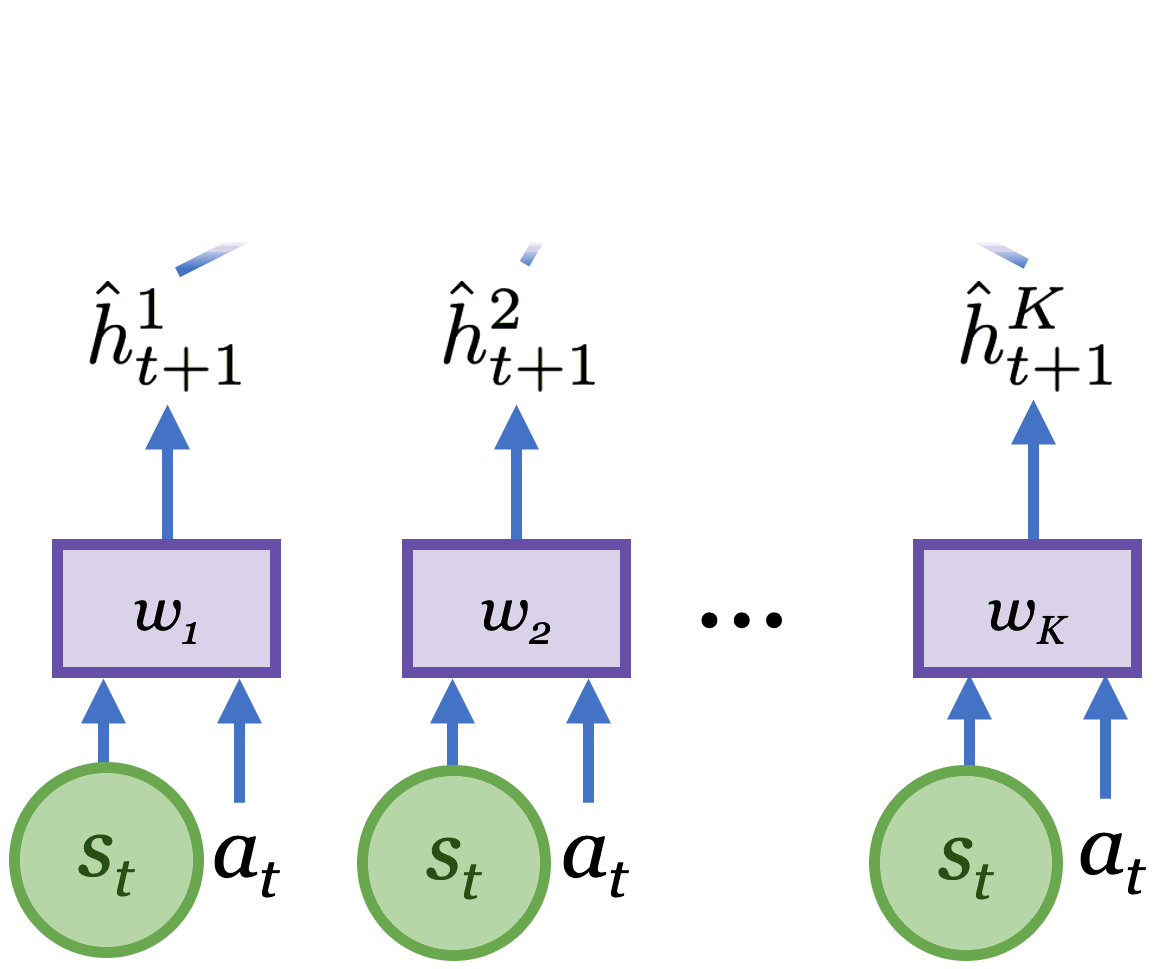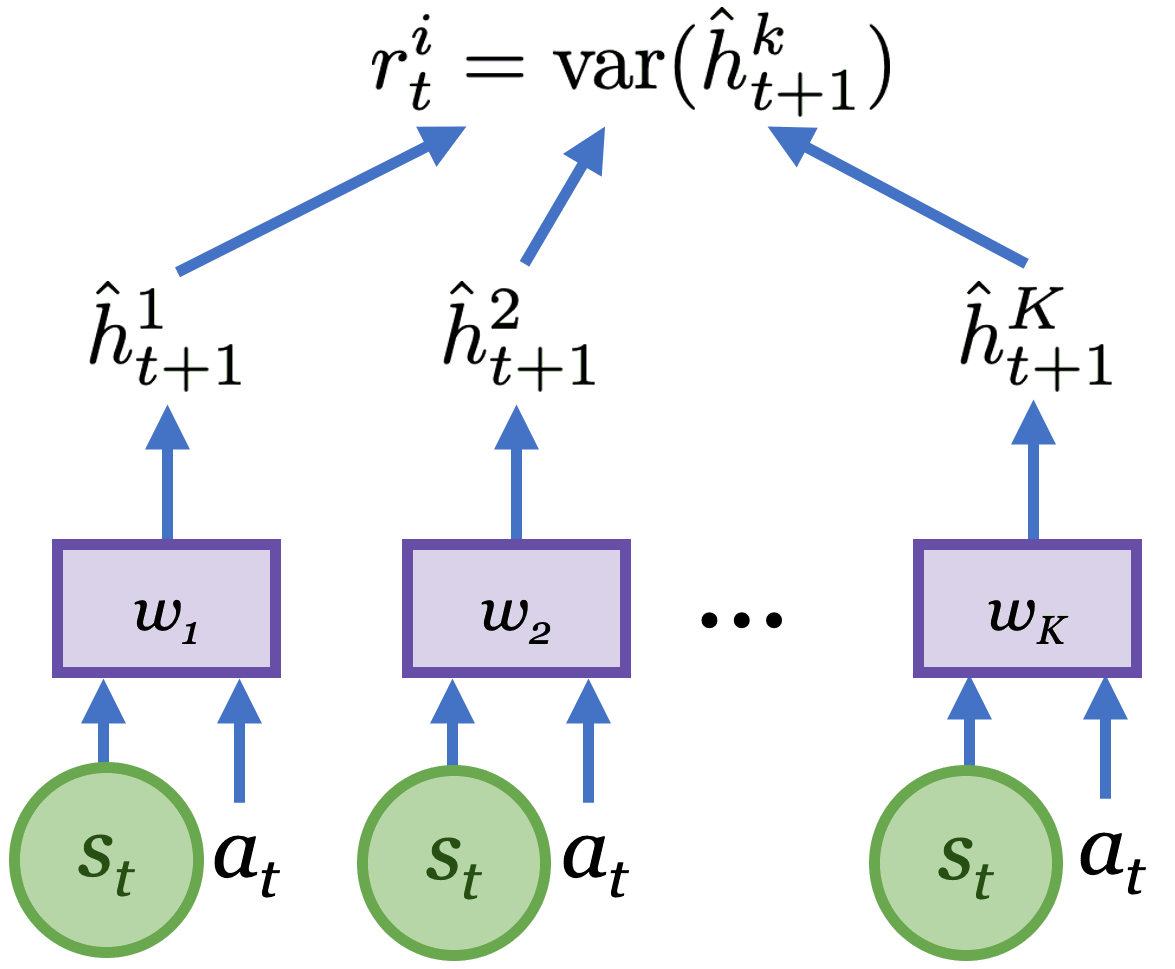
To learn an accurate and general world model we need an exploration strategy that collects new and informative data. To achieve this, Plan2Explore uses a novelty metric derived from the model itself. The novelty metric measures the expected information gained about the environment upon observing the new data. As the figure below shows, this is approximated by the disagreement of an ensemble of $K$ latent models. Intuitively, large latent disagreement reflects high model uncertainty, and obtaining the data point would reduce this uncertainty. By maximizing latent disagreement, Plan2Explore selects actions that lead to the largest information gain, therefore improving the model as quickly as possible.
Planning for future novelty
To effectively maximize novelty, we need to know which parts of the environment are still unexplored. Most prior work on self-supervised exploration used model-free methods that reinforce past behavior that resulted in novel experience. This makes these methods slow to explore: since they can only repeat exploration behavior that was successful in the past, they are unlikely to stumble onto something novel. In contrast, Plan2Explore plans for expected novelty by measuring model uncertainty of imagined future outcomes. By seeking trajectories that have the highest uncertainty, Plan2Explore explores exactly the parts of the environments that were previously unknown.
To choose actions $a$ that optimize the exploration objective, Plan2Explore leverages the learned world model as shown in the figure below. The actions are selected to maximize the expected novelty of the entire future sequence $s_{t:T}$, using imaginary rollouts of the world model to estimate the novelty. To solve this optimization problem, we use the Dreamer agent, which learns a policy $\pi_\phi$ using a value function and analytic gradients through the model. The policy is learned completely inside the imagination of the world model. During exploration, this imagination training ensures that our exploration policy is always up-to-date with the current world model and collects data that are still novel.

Curiosity-driven exploration behavior
We evaluate Plan2Explore on 20 continuous control tasks from the DeepMind Control Suite. The agent only has access to image observations and no proprioceptive information. Instead of random exploration, which fails to take the agent far from the initial position, Plan2Explore leads to diverse movement strategies like jumping, running, and flipping. Later, we will see that these are effective practice episodes that enable the agent to quickly learn to solve various continuous control tasks.






Solving tasks with the world model
Once an accurate and general world model is learned, we test Plan2Explore on previously unseen tasks. Given a task specified with a reward function, we use the model to optimize a policy for that task. Similar to our exploration procedure, we optimize a new value function and a new policy head for the downstream task. This optimization uses only predictions imagined by the model, enabling Plan2Explore to solve new downstream tasks in a zero-shot manner without any additional interaction with the world.
The following plot shows the performance of Plan2Explore on tasks from DM Control Suite. Before 1 million environment steps, the agent doesn’t know the task and simply explores. The agent solves the task as soon as it is provided at 1 million steps, and keeps improving fast in a few-shot regime after that.
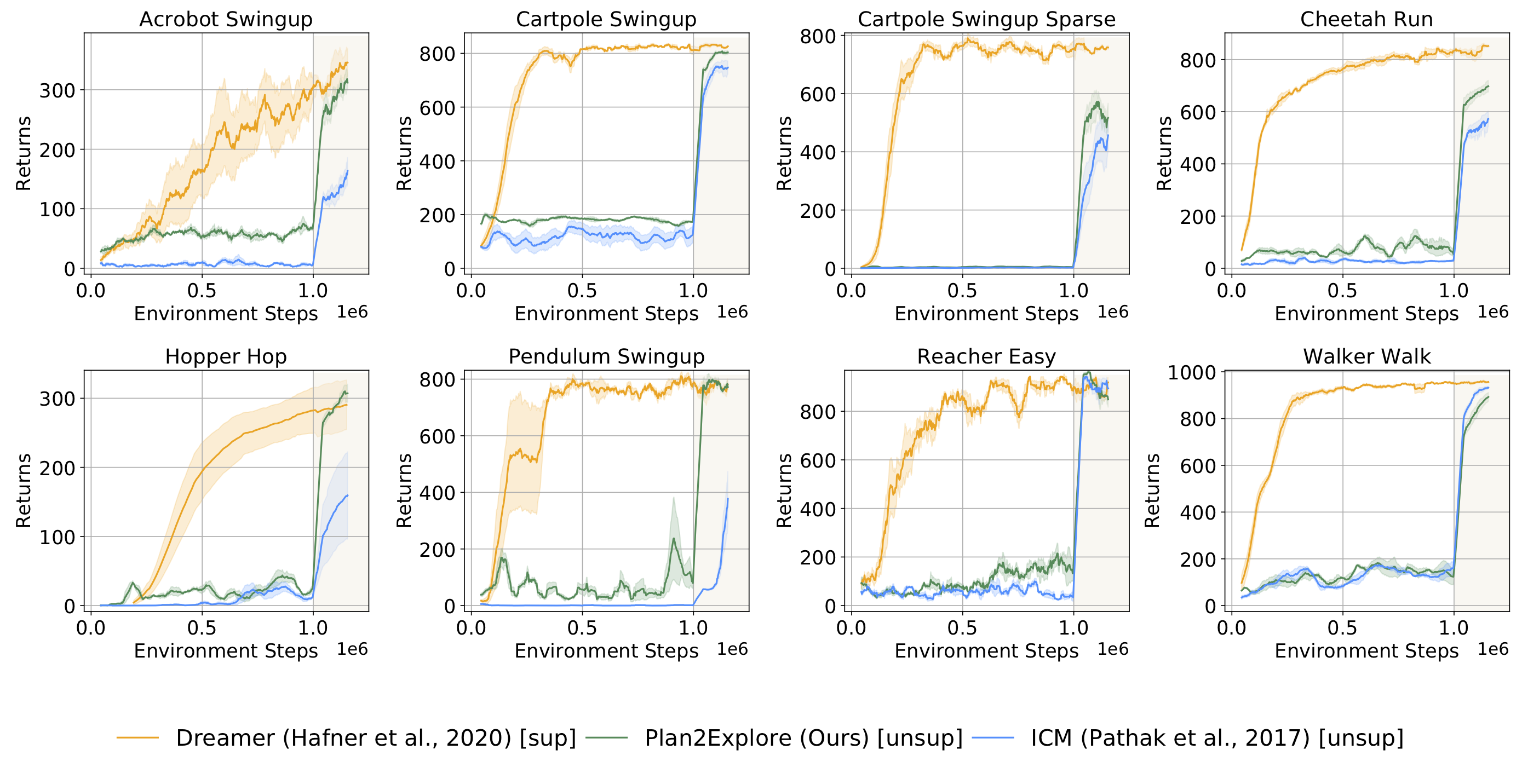
Plan2Explore (—) is able to solve most of the tasks we benchmarked. Since prior work on self-supervised reinforcement learning used model-free agents that are not able to adapt in a zero-shot manner (ICM, —), or did not use image observations, we compare by adapting this prior work to our model-based plan2explore setup. Our latent disagreement objective outperforms other previously proposed objectives. More interestingly, the final performance of Plan2Explore is comparable to the state-of-the-art oracle agent that requires task rewards throughout training (—). In our paper, we further report performance of Plan2Explore in the zero-shot setting where the agent needs to solve the task before any task-oriented practice.
Future directions
Plan2Explore demonstrates that effective behavior can be learned through self-supervised exploration only. This opens multiple avenues for future research:
-
First, to apply self-supervised RL to a variety of settings, future work will investigate different ways of specifying the task and deriving behavior from the world model. For example, the task could be specified with a demonstration, description of the desired goal state, or communicated to the agent in natural language.
-
Second, while Plan2Explore is completely self-supervised, in many cases a weak supervision signal is available, such as in hard exploration games, human-in-the-loop learning, or real life. In such a semi-supervised setting, it is interesting to investigate how weak supervision can be used to steer exploration towards the relevant parts of the environment.
-
Finally, Plan2Explore has the potential to improve the data efficiency of real-world robotic systems, where exploration is costly and time-consuming, and the final task is often unknown in advance.
By designing a scalable way of planning to explore in unstructured environments with visual observations, Plan2Explore provides an important step toward self-supervised intelligent machines.
We would like to thank Georgios Georgakis for the useful feedback.
This post is based on the following paper:
- Planning to Explore via Self-Supervised World Models
Ramanan Sekar*, Oleh Rybkin*, Kostas Daniilidis, Pieter Abbeel, Danijar Hafner, Deepak Pathak
Thirty-seventh International Conference Machine Learning (ICML), 2020.
arXiv, Project Website
This article was initially published on the BAIR blog, and appears here with the authors’ permission.