Philosophers and legal scholars have explored significant aspects of the moral and legal status of robots, with some advocating for giving robots rights. As robots assume more roles in the world, a new analysis reviewed research on robot rights, concluding that granting rights to robots is a bad idea. Instead, the article looks to Confucianism to offer an alternative.
Robots need accessories to work efficiently. But what’s the easiest way to connect the accessories to factory networks? The easiest way is to use HMS Networks’ ready-made Anybus products, as RSP found out.
Imagine you're enjoying a picnic by a riverbank on a windy day. A gust of wind accidentally catches your paper napkin and lands on the water's surface, quickly drifting away from you. You grab a nearby stick and carefully agitate the water to retrieve it, creating a series of small waves. These waves eventually push the napkin back toward the shore, so you grab it. In this scenario, the water acts as a medium for transmitting forces, enabling you to manipulate the position of the napkin without direct contact.
When we think of getting on the road in our cars, our first thoughts may not be that fellow drivers are particularly safe or careful—but human drivers are more reliable than one may expect. For each fatal car crash in the United States, motor vehicles log a whopping hundred million miles on the road.
Machine safety and security are two critical components of any industrial operation. Our latest video explores this question and provides insights into how security measures can enhance machine safety. Nivedita Ojha, VP of Product at FORT, breaks down the key considerations when it comes to securing your machines and keeping your workers safe, explaining why there is no safety without security.
Following the no-code/low-code trend, there are various software solutions on the market that enable graphical and therefore simplified and faster programming. The advantage is that no special programming skills are required.
I’ve spent the last eight years working with AI, learning the ins and outs of building and applying AI solutions in business. After making countless mistakes, I created my own method for building and applying the technology.
That was fine and dandy until the fall of 2022, when ChatGPT was released and gave a sudden rise in the usefulness and adoption of generative AI. For my consulting business TodAI, that meant a lot of new projects involving generative AI and a lot of learning. After several projects, I’ve identified places where generative models are clearly distinct from other AI when applying them in a business. Some are small, and others are very significant.
How do these new generative AI models change the game for applied AI?
Terminology
It’s easier to discuss the changes if we distinguish between generative AI and predictive AI.
Generative AI refers to large pre-trained models that output texts, images or sounds from user-provided prompts. The output is (potentially) unique and mimics human-generated content. It’s based on the prompt and the data used to train a large pre-trained model. Text-generating models such as OpenAI's GPT or Googles Bard are also known as large language models (LLMs).
Predictive AI comprises models that output one or more labels (prediction or classification) or numbers (regression or time series). It includes:
● Image building blocks: image classification, object detection and image segmentation
● Tabular building blocks: prediction, regression and forecast
● Text building blocks: text classification, named entity recognition and Intent analysis
An alternative and more accurate name for predictive AI in an academic sense is discriminative AI. However, I use “predictive” as it might resonate better with most people.
Generative AI can also predict
Generative AI (such as GPT) also can be used to solve predictive problems. ChatGPT can learn to classify texts through a few examples (few-shot learning) or no examples at all (zero-shot learning). The functionality might be the same, but there’s a technical difference. Generative AI doesn’t need you to train an algorithm that produces a model that can then classify. Instead, the generative model gets the examples as a part of the prompt.
The upside of using the generative models for predictive tasks is that implementation can be done immediately. However, there are downsides, such as:
● no way to calculate the expected performance through (for example) accuracy measures
● the generative model might provide an output that isn’t a part of the list of provided labels
● each prompt for output might affect future output
● generative models tend to "forget" the initial examples as they have a limit for how many prompts they can remember
Knowing how well an AI solution works is more complicated and takes more time
A good rule of thumb is that if you can’t achieve an OK accuracy of your model within 24 hours of work, you either have the wrong data or the wrong scope.
For example, a model predicting housing prices that predicts with 50% accuracy after 24 hours of modelling work will never see more than 60% or 65% accuracy, no matter what clever algorithm or fine-tuning you apply. If 60% isn’t good enough for your business case, you need to acquire more, other or better data, or change your business scope.
Following the 24-hour rule means that AI solutions that will never work are spotted early and scraped or redefined. The 24-hour rule has saved me from countless embarrassing failures, and it works as accuracy is an excellent indicator (not equal to, though) for the business value you can expect.
But that rule is no longer helpful in generative AI as there are no accuracy measurements during development. For example, if your business case is generating sales emails for a group of sales reps, you can’t measure the "accuracy" of the output. The business outcomes you’re trying to achieve might be faster communication with clients (through writing speed) or more sales (through better emails). These outcomes are hard to measure during development. Writing speed in particular is challenging to measure, as the output has to be checked and edited by a sales rep, and testing that speed requires involving the sales rep.
Generative AI requires closer domain expert collaboration
The result of this challenge is that domain experts must be involved closely in the development process to help adjust the output and measure the effect on the business outcome you’re trying to achieve. The days when you could rely on data scientist training and fine-tuning alone until a satisfying solution is ready are over.
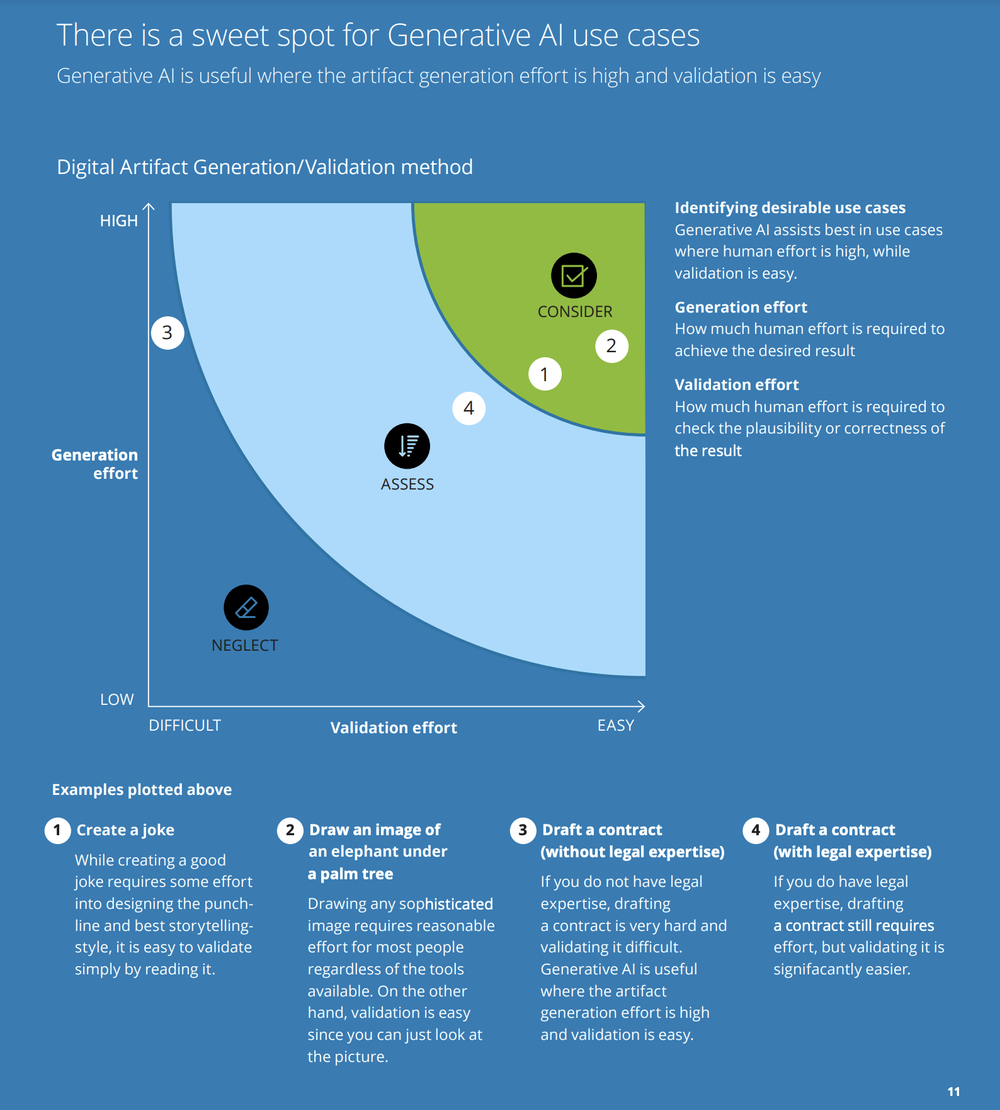
Picking use cases should be based on ease of testing
Delloite’s helpful guide about generative AI suggests that use cases for generative AI should be based on the effort it takes to validate output and the effort it would take a human to generate the same content.
The graph shows that the less effort it takes for a human to validate the output, the better the use case. Delloite works from a production point of view, but the same dynamic goes for testing the solution during development. If testing how a generative model's output affects the desired business outcome is too challenging, the use case might not be suitable.
So here's a new version of the 24-hour rule:
If you can’t test how your generative AI output affects the business outcome, stop the project or redefine the scope.
Generative AI benefits experts more than the novice users
Predictive AI use cases have often been about creating decision support systems where models trained on historical data could predict what the experts already know. For example, an AI solution that predicts what account an invoice should be recorded on can be trained on historical work from professional accountants and used to help small business owners do their accounting.
In generative AI, the models’ output is hard to access for novice users who won’t necessarily know if the AI is offering confident but wrong output. An example could be a solution that drafts a contract. Novice users with little to no legal experience won’t know if a clause is illegal or bears hidden risks. An experienced legal expert, on the other hand, will be able to weed out the confident-but-wrong output and pick up on helpful output, like a rare but relevant clause in a specific case.
This is a massive game-changer for AI. Not only does it mean that use cases for AI go towards another target audience (experts), it also suggests that value creation will be a more significant part of AI business cases than saving costs.
Implementing the decision model
A crucial part of productively applying predictive AI has been to make a decision model for mapping output, confidence and actions. For example, you could take a classic churn model that predicts how likely a customer is to cancel their agreement (churn) with a company. Mapping out the actions to take given a prediction (churn or not churn) is a crucial first step in building the solution.
In fact, no code or data acquisition should be done if the decision model can’t be made. The most common cause of AI solutions not going into production is that the business can’t agree on what actions to take given a prediction and an output.
Suppose the churn model predicts a customer has a 60% likelihood of churning in the next three months. How do you handle that? Do you provide a discount? Call the client? Simply accept it and use it as a forecast? As most businesses get stuck in strategic, legal or other discussions, AI solutions never surpass a prototype. Too bad if you invested a lot of time and money in development just to get stuck.
But it’s not as easy to make a decision model for a solution based on generative AI. First, the model output doesn’t go into simple labels, such as churn or no churn. Instead, it’s just a piece of text or an image. At the same time, there's no confidence score. The result is that you can only build a decision model with one output and one action.
On the bright side, the decision model or process flow will get simpler, although it also creates challenges. As you don’t know the quality of the output, and the output essentially can be anything, it’s tough to create fully automated systems. A confidence threshold is often set for predictive AI, and anything above that threshold triggers an automated action. For example, the above-mentioned accounting model could automatically act as a bookkeeper if confidence was above 98%.
One fix for confidence is when generative AI uses data from the source material for inspiration. That could be a database of contract templates or support articles. In this case, you can get a confidence score on the model's certainty that the source material was a good match for the prompted request.
More business, less code
Developing AI solutions based on generative AI requires less code than predictive AI solutions. Generative AI solutions don’t need training, complicated prediction pipelines, or retraining flows. The output is often presented as-is to the user and not post-processed as much as in predictive AI solutions. This requires less code, and the development time is shorter. That, in combination with the above-mentioned challenges to applying generative AI in business contexts, results in more business work and less code. It results in a shift towards a need for business roles such as UX, solution designers or product managers, and a reduced need for developers and data scientists. Both are still important, but in terms of hourly expenditure, the business side goes up and the technical side down.
Conclusion
In my experience, the implementation of generative AI is faster and more impactful than predictive AI, but it also requires more business understanding and courage from the business implementing it.
The added requirements for business understanding will be especially interesting to observe in future AI cases, as they’ve historically been under-prioritised by most teams delivering AI solutions.