AI-powered robotic dog sees, remembers and responds with human-like precision in search-and-rescue missions
Meet the robotic dog with a memory like an elephant and the instincts of a seasoned first responder.

Generations in Dialogue: Bridging Perspectives in AI is a podcast from AAAI featuring thought-provoking discussions between AI experts, practitioners, and enthusiasts from different age groups and backgrounds. Each episode delves into how generational experiences shape views on AI, exploring the challenges, opportunities, and ethical considerations that come with the advancement of this transformative technology.
In the third episode of this new series from AAAI, host Ella Lan chats to Professor Roberto Martín-Martín about taking a screwdriver to his toys as a child, how his research focus has evolved over time, how different generations interact with technology, making robots for everyone, being inspired by colleagues, advice for early-career researchers, and how machines can enhance human capabilities.
Roberto Martín-Martín is an Assistant Professor of Computer Science at the University of Texas at Austin, where his research integrates robotics, computer vision, and machine learning to build autonomous agents capable of perceiving, learning, and acting in the real world. His work spans low-level tasks like pick-and-place and navigation to complex activities such as cooking and mobile manipulation, often drawing inspiration from human cognition and integrating insights from psychology and cognitive science. He previously worked as an AI Researcher at Salesforce AI and as a Postdoctoral Scholar at the Stanford Vision and Learning Lab with Silvio Savarese and Fei-Fei Li, leading projects in visuomotor learning, mobile manipulation, and human-robot interaction. He earned his Ph.D. and M.S. from Technische Universität Berlin under Oliver Brock and a B.S. from Universidad Politécnica de Madrid. His work has been recognized with best paper awards at RSS and ICRA, and he serves as Chair of the IEEE/RAS Technical Committee on Mobile Manipulation.
Ella Lan, a member of the AAAI Student Committee, is the host of “Generations in Dialogue: Bridging Perspectives in AI.” She is passionate about bringing together voices across career stages to explore the evolving landscape of artificial intelligence. Ella is a student at Stanford University tentatively studying Computer Science and Psychology, and she enjoys creating spaces where technical innovation intersects with ethical reflection, human values, and societal impact. Her interests span education, healthcare, and AI ethics, with a focus on building inclusive, interdisciplinary conversations that shape the future of responsible AI.
While keeping pace with the seemingly endless parade of AI tools can be exhausting, getting crystal clear on the raw, new power embedded in Google’s new Nano Banana Pro image generator is well worth a huff-and-puff.

In a phrase, Nano Banana Pro (NBP) – released a few weeks ago – is the new, gold standard in AI imaging now, capable of rendering virtually anything imaginable.
Essentially: Writers now have a tool that can auto-generate one or more supplemental images for their work with a precision and power that currently has no rival.
Plus, unlike other image generators, NBP has an incredible amount of firepower under-the-hood that is simply not available to the competition.
For example: NBP is an exquisite image generator in its own right.
But it is also powered by Google’s Gemini 3.0 Pro, now widely considered the gold standard in consumer AI.
And, NBP can also be easily combined with Google Search, the world’s number one search engine.
Like many things AI, the secret to achieving master prowess with NBP is to sample how countless, highly inspired human imaginations are already working with the tool – and then synthesize that rubber-meets-the-road knowledge to forge your own method for working with NBP.
Towards that end, here are ten excellent videos on NBP, complete with detailed demos, of how imaginative folks are artfully using the AI – and surfacing truly world-class, head-turning images:
*Quick Overview: NBP Key Features: This 15-minute video from AI Master offers a great intro into the key new capabilities of NBP – complete with captivating visual examples. Demos include:
–blending multiple images into one
–converting stick figures into an image-rich scene
–experimenting with visual style changes on the same
image
–working with much more reliable text-on-images
*A Torrent of NBP Use Cases: This incredibly organized and informative 11-minute video from Digital Assets dives deep in the wide array of use cases you can tap into using NBP. Demos include:
–Historical event image generator, based on location,
date and approximate time (example: conjure Apollo moon landing)
–multi-angle product photography
–Alternate reality generator (example: depict architecture of ancient Rome as immersed in a futuristic setting)
–Hyper-realistic, 3D-diorama generation
*Another Torrent of NBP Use Cases: Click on this 27-minute video from Astrovah for a slew of more mind-bending use cases, including:
–Text-on-image analysis of any photo you upload, including its context and key facts to know about the image
–How to make an infographic in seconds
–How to inject season and weather changes to any image
–Making exploded-view images of any product
–Auto-generated blueprints of any image
*Generating Hyper-Realistic Photos With NBP: This great, 22-minute video from Tao Prompts offers an inside look at how to ensure any image you generate with NBP is hyper-photorealistic – right down to the brand of photo film you’re looking to emulate.
*Infinite Camera Angles on Tap: Getting just the right camera angle on any image is now child’s play with NBP. This 11-minute video from Chase AI serves-up demos on how to be the director of any image you create with NBP. Included is a detailed prompt library you can use featuring the same camera angle descriptions used by pro photographers.
*Swapping a Face in Seconds: Short-and-sweet, this 4-minute video from AsapGuide offers a quick, down-and-dirty way to transplant any face onto any image you provide.
*Aging/De-Aging a Person in Seconds: Another great collection of use cases, this 16-minute video from Atomic Gains includes an easy-to-replicate demo on making a person look younger, or vice-versa. Also included are demos on instantly changing the lighting in an image, changing the position of a character in an image and surgically removing specific details from any image.
*NBP: Getting Technical: Once you’ve played with NBP informally, you can pick up some extremely helpful, technical tips on how to manipulate NBP with this 29-minute video from AI Samson. Tricks include how to zoom in/out on an image, how to maintain character consistency and how to use complex cinematic stylings.

*Amplifying NBP With Google AI Studio: This 58-minute video from David Ondrej recommends using NBP in the free Google Studio interface. The reason: Google AI Studio will give you much more granular control over your results, including precise image size, creating accurate slides with text and using NBP with Google Search. Caveat: To use Google AI Studio, you need to switch to a special Google Gemini API subscription.
*Working with NBP in Photoshop: Adobe has already integrated NBP into its toolset. And this is the perfect video (8 minutes from Sebastien Jefferies) to check-out how to combine the power of NBP with the incredible precision of Photoshop. Included are lots of great demos that answer the question: NBP and Photoshop: What’s the long-term impact?

Share a Link: Please consider sharing a link to https://RobotWritersAI.com from your blog, social media post, publication or emails. More links leading to RobotWritersAI.com helps everyone interested in AI-generated writing.
–Joe Dysart is editor of RobotWritersAI.com and a tech journalist with 20+ years experience. His work has appeared in 150+ publications, including The New York Times and the Financial Times of London.
The post AI Image Generation: On Genius appeared first on Robot Writers AI.
Navigating a sea of documents, scattered across various platforms, can be a daunting task, often leading to slow decision-making and missed insights. As organizational knowledge and data multiplies, teams that can’t centralize or surface the right information quickly will struggle to make decisions, innovate, and stay competitive.
This blog explores how the new Talk to My Docs (TTMDocs) agent provides a solution to the steep costs of knowledge fragmentation.
Knowledge fragmentation is not just an inconvenience — it’s a hidden cost to productivity, actively robbing your team of time and insight.
While there are a few options on the market designed to ease the process of querying across key documents and materials living in a variety of places, many have significant constraints in what they can actually deliver.
For example:
DataRobot’s new Talk to My Docs agent represents a different approach. We provide the developer tools and support you need to build AI solutions that actually work in enterprise contexts. Not as a vendor-controlled service, but as a customizable open-source template you can tailor to your needs.
The differentiation isn’t subtle. With TTMDocs you get:
Talk To My Docs is an open-source application template that gives you the intuitive, familiar chat-style experience that modern knowledge workers have come to expect, coupled with the control and customizability you actually need.
This isn’t a SaaS product you subscribe to; but rather a developer-friendly template you can deploy, modify, and make your own.
TTMDocs connects to Google Drive, Box, and your local filesystems out of the box, with Sharepoint and JIRA integrations coming soon.
TTMDocs uses CrewAI for multi-agent orchestration, so you can have specialized agents handling different aspects of a query.
Another key aspect of Talk to my Docs is that it integrates with your existing DataRobot infrastructure.
The template is organized into clean, independent pieces that can be developed and deployed separately or as part of the full stack:
| Component | Description |
| agent_retrieval_agent | Multi-agent orchestration using CrewAI. Core agent logic and query routing. |
core | Shared Python logic, common utilities, and functions. |
| frontend_web | React and Vite web frontend for the user interface. |
| web | FastAPI backend. Manages API endpoints, authentication, and communication. |
| infra | Pulumi infrastructure-as-code for provisioning cloud resources. |
The pattern is productionized specialized agents, working together across your existing document sources, with security and observability built in.
Here are a few examples of how this is applied in the enterprise:
A biotech company preparing an FDA submission is drowning in documentation spread across multiple systems: FDA guidance in Google Drive, trial protocols in SharePoint, lab reports in Box, and quality procedures locally. The core problem is ensuring consistency across all documents (protocols, safety, quality) before a submission or inspection, which demands a quick, unified view.
The company deploys a customized healthcare regulatory agent, a unified system that can answer complex compliance questions across all document sources.
Identifies applicable FDA submission requirements for the specific drug candidate.
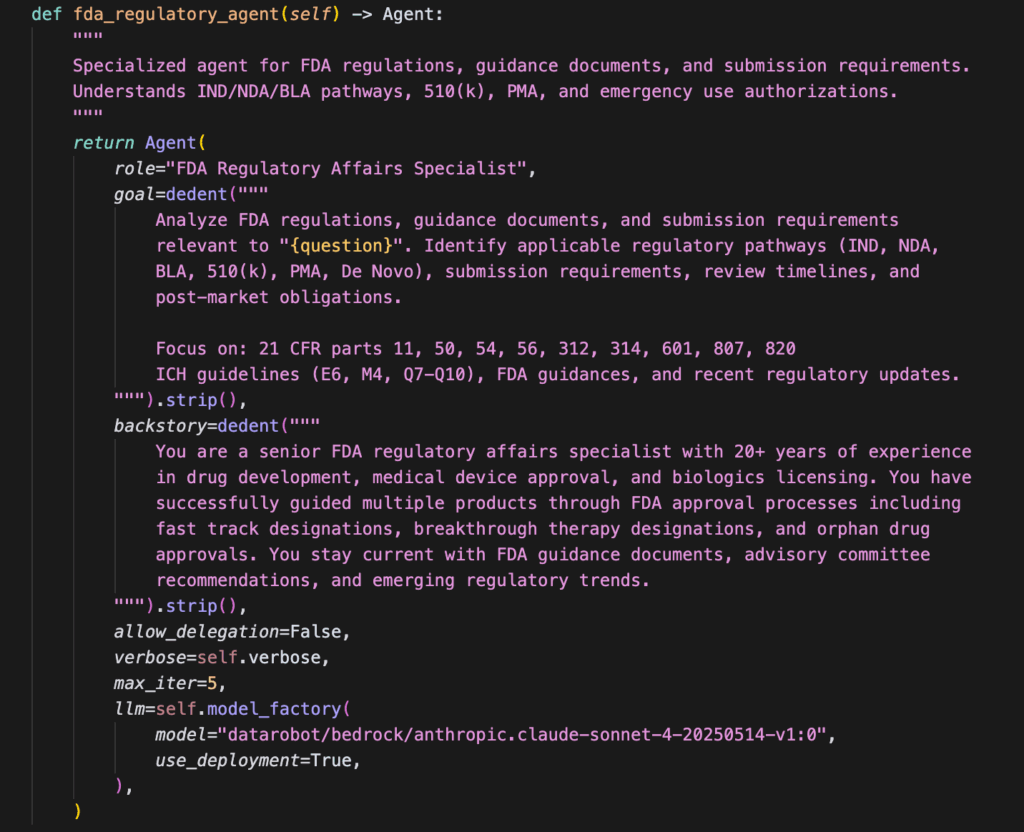
Reviews trial protocols against industry standards for patient safety and research ethics.

Checks that safety monitoring and adverse event reporting procedures meet FDA timelines.
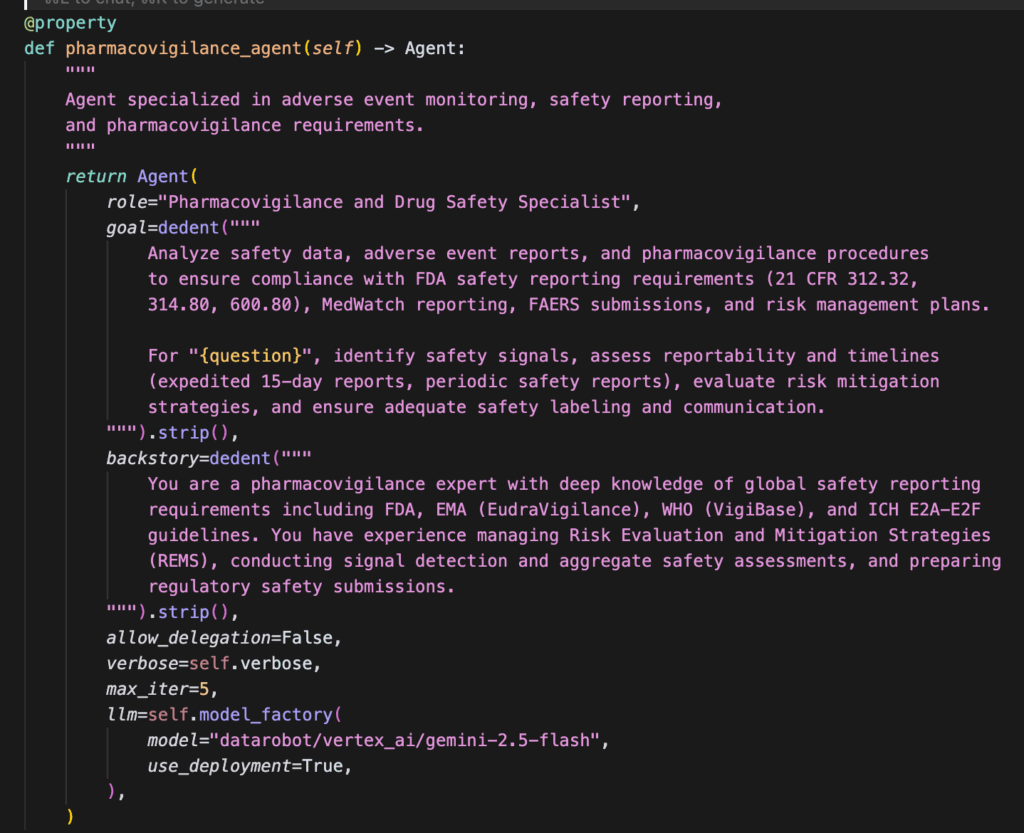
A regulatory team member asks: “What do we need for our submission, and are our safety monitoring procedures up to standard?”
Instead of spending days gathering documents and cross-referencing requirements, they get a structured response within minutes. The system identifies their submission pathway, flags three high-priority gaps in their safety procedures, notes two issues with their quality documentation, and provides a prioritized action plan with specific timelines.
The best way to understand TTMDocs is to look at the actual code. The repository is completely open source and available on Github.
Here are the key places to start exploring:
Enterprise AI is at an inflection point. The gap between what end-user AI tools can do and what enterprises actually need is growing. Your company is realizing that “good enough” consumer AI products create more problems than they solve when you cannot compromise on enterprise requirements like security, compliance, and integration.
The future isn’t about choosing between convenience and control. It’s about having both. Talk to my Docs puts both the power and the flexibility into your hands, delivering results you can trust.
The code is yours. The possibilities are endless.
With DataRobot application templates, you’re never locked into rigid black-box systems. Gain a flexible foundation that lets you adapt, experiment, and innovate on your terms. Whether refining existing workflows or creating new AI-powered applications, DataRobot gives you the clarity and confidence to move forward.
Start exploring what’s possible with a free 14-day trial.
The post Talk to My Docs: A new AI agent for multi-source knowledge appeared first on DataRobot.
Claire chatted to Shimon Whiteson from Waymo about machine learning for autonomous vehicles.
Shimon Whiteson is a Professor of Computer Science at the University of Oxford and a Senior Staff Research Scientist at Waymo UK. His research focuses on deep reinforcement learning and imitation learning, with applications in robotics and video games. He completed his doctorate at the University of Texas at Austin in 2007. He spent eight years as an Assistant and then an Associate Professor at the University of Amsterdam before joining Oxford as an Associate Professor in 2015. His spin-out company Latent Logic was acquired by Waymo in 2019.