From swallowing pills to injecting insulin, patients frequently administer their own medication. But they don’t always get it right. Improper adherence to doctors’ orders is commonplace, accounting for thousands of deaths and billions of dollars in medical costs annually. MIT researchers have developed a system to reduce those numbers for some types of medications.
The new technology pairs wireless sensing with artificial intelligence to determine when a patient is using an insulin pen or inhaler, and flags potential errors in the patient’s administration method. “Some past work reports that up to 70% of patients do not take their insulin as prescribed, and many patients do not use inhalers properly,” says Dina Katabi, the Andrew and Erna Viteri Professor at MIT, whose research group has developed the new solution. The researchers say the system, which can be installed in a home, could alert patients and caregivers to medication errors and potentially reduce unnecessary hospital visits.
The research appears today in the journal Nature Medicine. The study’s lead authors are Mingmin Zhao, a PhD student in MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL), and Kreshnik Hoti, a former visiting scientist at MIT and current faculty member at the University of Prishtina in Kosovo. Other co-authors include Hao Wang, a former CSAIL postdoc and current faculty member at Rutgers University, and Aniruddh Raghu, a CSAIL PhD student.
Some common drugs entail intricate delivery mechanisms. “For example, insulin pens require priming to make sure there are no air bubbles inside. And after injection, you have to hold for 10 seconds,” says Zhao. “All those little steps are necessary to properly deliver the drug to its active site.” Each step also presents opportunity for errors, especially when there’s no pharmacist present to offer corrective tips. Patients might not even realize when they make a mistake — so Zhao’s team designed an automated system that can.
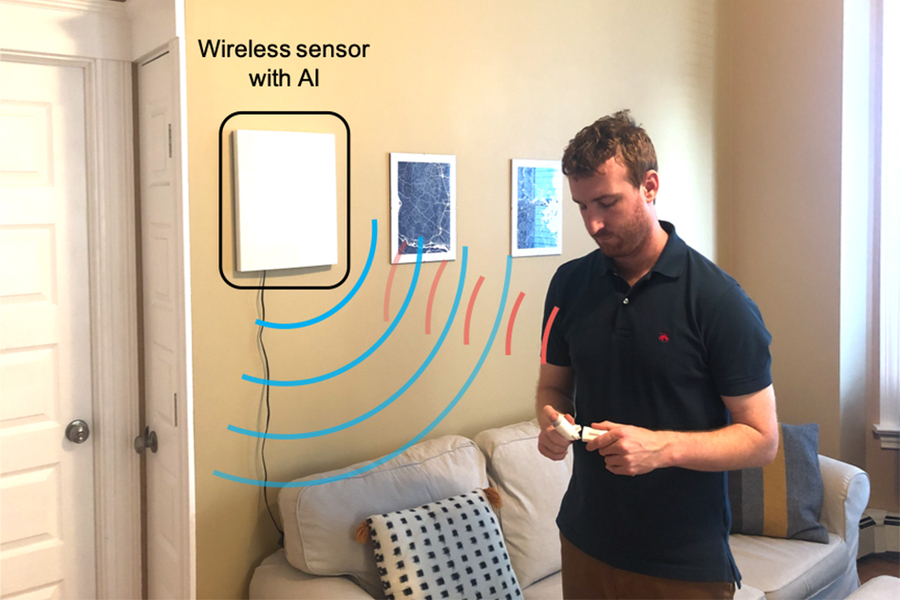
Their system can be broken down into three broad steps. First, a sensor tracks a patient’s movements within a 10-meter radius, using radio waves that reflect off their body. Next, artificial intelligence scours the reflected signals for signs of a patient self-administering an inhaler or insulin pen. Finally, the system alerts the patient or their health care provider when it detects an error in the patient’s self-administration.

The researchers adapted their sensing method from a wireless technology they’d previously used to monitor people’s sleeping positions. It starts with a wall-mounted device that emits very low-power radio waves. When someone moves, they modulate the signal and reflect it back to the device’s sensor. Each unique movement yields a corresponding pattern of modulated radio waves that the device can decode. “One nice thing about this system is that it doesn’t require the patient to wear any sensors,” says Zhao. “It can even work through occlusions, similar to how you can access your Wi-Fi when you’re in a different room from your router.”
The new sensor sits in the background at home, like a Wi-Fi router, and uses artificial intelligence to interpret the modulated radio waves. The team developed a neural network to key in on patterns indicating the use of an inhaler or insulin pen. They trained the network to learn those patterns by performing example movements, some relevant (e.g. using an inhaler) and some not (e.g. eating). Through repetition and reinforcement, the network successfully detected 96 percent of insulin pen administrations and 99 percent of inhaler uses.
Once it mastered the art of detection, the network also proved useful for correction. Every proper medicine administration follows a similar sequence — picking up the insulin pen, priming it, injecting, etc. So, the system can flag anomalies in any particular step. For example, the network can recognize if a patient holds down their insulin pen for five seconds instead of the prescribed 10 seconds. The system can then relay that information to the patient or directly to their doctor, so they can fix their technique.
“By breaking it down into these steps, we can not only see how frequently the patient is using their device, but also assess their administration technique to see how well they’re doing,” says Zhao.
The researchers say a key feature of their radio wave-based system is its noninvasiveness. “An alternative way to solve this problem is by installing cameras,” says Zhao. “But using a wireless signal is much less intrusive. It doesn’t show peoples’ appearance.”
He adds that their framework could be adapted to medications beyond inhalers and insulin pens — all it would take is retraining the neural network to recognize the appropriate sequence of movements. Zhao says that “with this type of sensing technology at home, we could detect issues early on, so the person can see a doctor before the problem is exacerbated.”














