MIT researchers have developed a generative artificial intelligence-driven approach for planning long-term visual tasks, like robot navigation, that is about twice as effective as some existing techniques. Their method uses a specialized vision-language model to perceive the scenario in an image and simulate actions needed to reach a goal. Then a second model translates those simulations into a standard programming language for planning problems, and refines the solution.
Powered by our proprietary geomagnetic engine and our hardware suite, ION combines high-precision positioning with accurate tracking of assets and people. That’s what allows people, assets, and autonomous systems to interact with space reliably, without heavy reliance on traditional infrastructure.
What started out as a response to labor shortages in poultry processing plants during the COVID-19 pandemic has turned into a robotics system that can learn by imitating human movements to handle chickens. Using an advanced imitation learning algorithm and camera perceptions, researchers with the Arkansas Agricultural Experiment Station have developed ChicGrasp, a dual-jaw robotic gripper with pinchers that can grasp a chicken carcass by the legs, lift and hang it on a shackle conveyor to be moved on for further processing.
A new type of robotic hand developed at The University of Texas at Austin demonstrates such sensitive touch that it can grasp objects as fragile as a potato chip or a raspberry without crushing them. The technology, called Fragile Object Grasping with Tactile Sensing (FORTE), combines advanced tactile sensing with soft robotics. The breakthrough could improve robot performance when a light touch is needed, such as in health care and manufacturing.
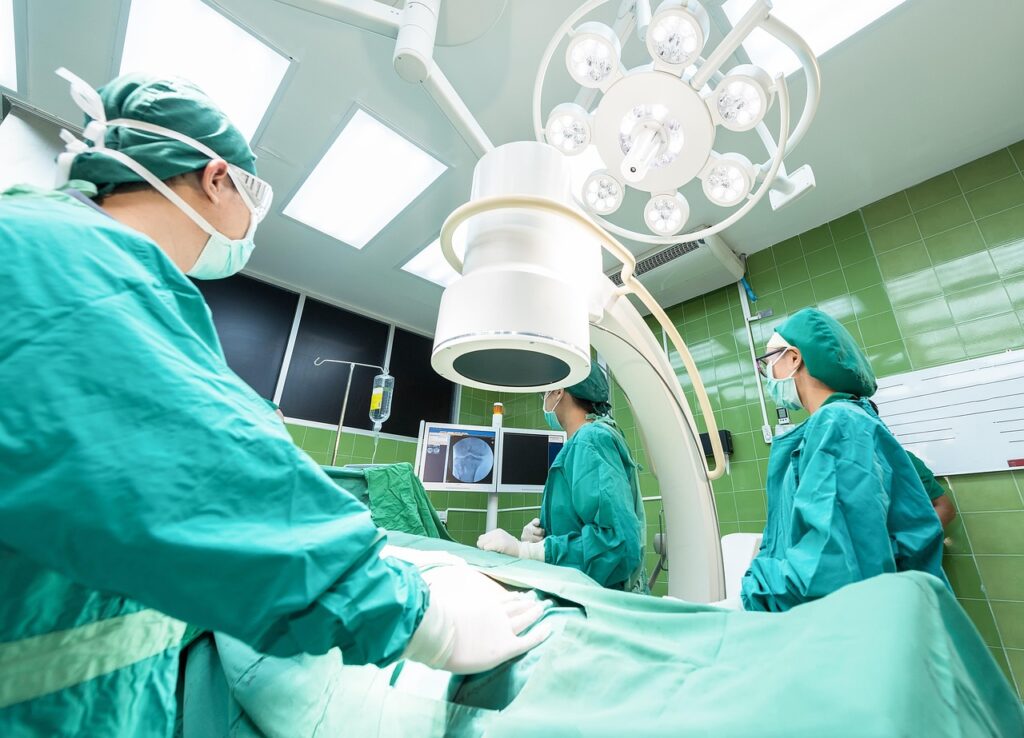
Modern surgery has gone from long incisions to tiny cuts guided by robots and AI. In the process, however, surgeons have lost something vital: the chance to feel inside the body directly. Without palpation, it becomes harder to detect tissue abnormalities during an operation.
A group of surgeons and engineers across Europe is now trying to bring back this vital aspect of surgery.
Working within an EU-funded research collaboration called PALPABLE, they are developing a soft robotic “fingertip” that can sense how firm or soft tissue is during minimally invasive and robotic surgery. The research runs until the end of 2026, with a first prototype expected to be tested by surgeons around March 2026.
By combining optical sensing, soft robotics and AI, the team is designing a probe that mimics the way a fingertip presses and feels during surgery. It would gently probe organs and create a visual map of tissue stiffness, displayed on a screen to guide surgeons as they operate.
Losing the surgeon’s touch
For many surgeons, the loss of direct touch has been one of the quiet trade-offs of modern surgery.
Sooner or later, I believe the vast majority of surgeries will be robotic.
“We started 30 years ago with open surgery and using our fingers,” said Professor Alberto Arezzo from the University of Turin, Italy. He specialises in minimally invasive and robotic surgery and mostly treats patients with colorectal cancer.
“Then we moved into the era of keyhole surgery, which reduced tactile feedback because we began to use long instruments,” he said.
From the 1990s, keyhole surgery became increasingly common, allowing surgeons to operate through small incisions with the help of a camera. Patients benefited from less trauma, shorter hospital stays and faster recovery.
But this came at the expense of physical touch. That matters because tumours often feel different from healthy tissue – stiffer, less pliable or irregular – important differences that experienced hands can detect.
Finding tumour margins
When operating on cancer, surgeons walk a fine line: remove too much tissue and function may suffer; remove too little and cancer may remain, and then spread again, requiring more surgery.
“We don’t want to do that. We want it done in one shot,” said Dr Gadi Marom at Hadassah Medical Centre in Jerusalem, one of the clinicians involved in the research, who specialises in minimally invasive and robotic surgery on patients with stomach and oesophagus diseases.
This is where sensing technology could help. By translating physical contact into visual information, such as a colour-coded map showing softer and firmer areas, surgeons could regain a functional equivalent of touch.
“With a new instrument, we want to be able to determine the margins around a tumour,” said Marom.
Using light to feel
To do that, engineers on the team are turning to light.
The probe they are developing contains fibre-optic cables embedded in a soft, flexible tip. When pressed against tissue, the tip deforms and the light travelling through the fibres changes.
“A silicone dome presses against soft tissue, allowing us to map both the direction and the magnitude of the applied force,” explained Dr Georgios Violakis at Hellenic Mediterranean University in Heraklion, Crete.
Those tiny shifts in light intensity and wavelength are then translated into information about tissue stiffness.
In the lab, the team has already built and calibrated early versions of the soft membrane and light-based sensors, with partners contributing across the system.
Queen Mary University of London (UK) is helping design and refine the membranes, the Fraunhofer Institute (Germany) is developing the functional films, while Bendabl (Greece), Tech Hive Labs (Greece) and the University of Essex (UK) are advancing the software needed to visualise stiffness and tactile maps.
The prototype will be validated in lab tests before it is used on patients.
The bottom line is that we will be able to give better care to our patients.
The fibre‑optic cables are each about the width of a human hair. Similar sensing technology has long been used to detect small movements in large structures such as aircraft, skyscrapers and nuclear reactors. Here it is being applied on a much smaller scale to detect subtle differences in human tissue.
“For touching organs inside an anaesthetised patient, the device needs to be both highly accurate and high resolution,” said Professor Panagiotis Polygerinos, a soft robotics researcher at Hellenic Mediterranean University.
“Something like this might have been possible sooner, but the technology would have been far more expensive and less precise, making it impractical for clinical use.”
Bringing touch to robots
As surgery grows increasingly robotic, the loss of tactile feedback is becoming more pressing – and restoring a sense of touch even more vital.
“When I operate with a robot I have the advantage of 3D vision,” said Marom. “And I don’t have to stand for the entire surgery.” That matters in long procedures, such as removing a patient’s oesophagus, which can take up to eight hours.
Robotic surgery also raises new possibilities. Marom hopes it may eventually allow surgeons, in carefully selected cases, to remove small tumours from the oesophagus without removing the entire organ.
But there is a downside.
“In robotic surgery, tactile feedback is largely absent,” said Arezzo. “That’s why this work is so important.”
Both surgeons believe robotics will continue to expand in operating theatres, but only if surgeons are given better sensory information.
“Sooner or later, I believe the vast majority of surgeries will be robotic,” said Arezzo.
For Marom, working closely with engineers has been essential. “I am exposed to soft robotics and many new technologies,” he said. “I see how new instruments can be developed.”
“The bottom line is that we will be able to give better care to our patients,” he added.
Research in this article was funded by the EU’s Horizon Programme. The views of the interviewees don’t necessarily reflect those of the European Commission. If you liked this article, please consider sharing it on social media.
As global manufacturing continues to upgrade, capacity expansion and automation are advancing in parallel. Yet as production takt time accelerates, a critical question emerges: Can factory logistics reliably sustain higher operational intensity?
RMIT University engineers in Australia have built a remote-controlled minibot that hoovers up oil spills using an innovative filtering system inspired by sea urchins. Oil spills are still a serious problem around the world. They can badly damage oceans and coasts, kill or injure sea animals and birds, and cost billions of dollars to clean up and repair the damage.
Peak season pushes the limits of your building, but when done right, robots work quickly and continuously, smoothing out material flow. This results in better operations and increases warehouse output. This is the real value of robotic automation.
Most of those people use the free version of ChatGPT, while about 50 million users access the AI via a paid subscription, according to writer Aisha Malik.
Adds Malik: “The new weekly active user figure marks a jump of 100 million users from the 800 million that OpenAI reported in October 2025.”
Observes lead writer Kali Hays: “The company had grown concerned in recent months about the government potentially using its AI tools — like Claude — in what it described as mass surveillance and fully autonomous weapons.”
Claude and similar Anthropic tools are currently the number one choice among many computer coders.
Observes writer Liz Skalka: “Give the site your zip code and it would produce a daily or twice-weekly newsletter customized for your town, for a minimum readership of one subscriber.
“The newsletters rely heavily on aggregation, automated event calendars and posts from Nextdoor (a hyperlocal social media network).”
Problem is, none of those experts granted Grammarly permission to use their thinking for such a purpose – which has more than a few people ticked.
Observes writer Miles Klee: “Instead of producing what looks like a generic critique from a nameless LLM, it lists a number of real academics and authors available to weigh in on your text. To be clear: Those people have nothing to do with this process.”
Unlike many AI writing tools, this one focuses entirely on press release writing and follows standard press release form and function developed by journalists.
Observes writer Richard Speed: “The megacorp is considering a new Microsoft 365 subscription tier, informally dubbed E7, that would bundle Copilot and agent management tools.”
The reasoning: “As AI agents function as digital workers, they need identities, email accounts, Teams access, and policy controls – capabilities currently tied to user subscriptions,” Speed adds.
Observes writer Laurent Giret: “Microsoft described the feature as a To-Do list that does itself, done by an AI agent using its own computer and web browser in the background.”
Potential uses include creation of draft email replies each morning, general AI writing, online shopping, event planning, and more.
Observes writer Mariella Moon: “At the moment, it’s reportedly only showing up on desktop browsers when select users visit Meta AI on the Web.”
Users prompting the assistant for shopping tips get back a virtual carousel of product images and pricing — as well as a link to where they can buy the product.
The AI is also able to customize suggestions based on gender and location if you share that personal data with Meta.
Share a Link: Please consider sharing a link to https://RobotWritersAI.com from your blog, social media post, publication or emails. More links leading to RobotWritersAI.com helps everyone interested in AI-generated writing.
–Joe Dysart is editor of RobotWritersAI.com and a tech journalist with 20+ years experience. His work has appeared in 150+ publications, including The New York Times and the Financial Times of London.
Engineers at Oxford University have developed a rapid, ultra-low-cost method for manufacturing soft robots using common lab equipment. The method has been published in Advanced Science. The new technique enables researchers to fabricate soft robotic actuators—the flexible components that power movement—in under 10 minutes at a material cost of less than $0.10 (US Dollars) per unit.
Companies are pushing semi-automated and Fully automated solutions to address Ergonomics among many other challenges like Efficiency, SKU proliferation, Labor Challenges etc.
Claire chatted to Maria Guix from the University of Barcelona about combining electronics and biology to create biohybrid robots with emergent properties.
Maria Guix is a chemist and nanotechnology researcher in the University of Barcelona’s ChemInFlow lab, developing miniaturised living robots and integrating flexible sensors into microfluidic platforms to better understand biohybrid robotic platforms. Her PhD research at the Autonomous University of Barcelona focussed on nanomaterials for biosensing. She has held postdoctoral positions at IFW Dresden, Purdue University, and the Institute for Bioengineering of Catalonia, advancing biocompatible micromotors, magnetic microrobot automation, and functional living robots.
This analysis was produced by an AI financial research system. All data is sourced exclusively from publicly available filings, earnings transcripts, government data, and free financial aggregators — no proprietary data, paid research, or institutional tools are used. Every figure cited can be independently verified by the reader using the sources listed at the end...
At least 57 nations have live antipersonnel land mines in their territories. In 2024 alone, 1,945 people were killed by mines and 4,325 were injured, 90% of whom were civilians. Nearly half of those were children. Demining operations removed 105,640 mines in the same year.