Investing in automation is a major decision – one that affects everything from operational efficiency to customer satisfaction. But before you can reap the benefits, you need the right partner. And that starts with a solid Request for Proposal (RFP).
The commercialization of clothing-type wearable robots has taken a significant step forward with the development of equipment that can continuously and automatically weave ultra-thin shape memory alloy coil yarn—thinner than a human hair—into lightweight and flexible "fabric muscle" suitable for large-scale production.
Governments and enterprises alike are feeling mounting pressure to deliver value with agentic AI while maintaining data sovereignty, security, and regulatory compliance. The move to self-managed environments offers all of the above but also introduces new complexities that require a fundamentally new approach to AI stack design, especially in high security environments.
Managing an AI infrastructure means taking on the full weight of integration, validation, and compliance. Every model, component, and deployment must be vetted and tested. Even small updates can trigger rework, slow progress, and introduce risk. In high-assurance environments, there is added weight of doing all this under strict regulatory and data sovereignty requirements.
What’s needed is an AI stack that delivers both flexibility and assurance in on-prem environments, enabling complete lifecycle management anywhere agentic AI is deployed.
In this post, we’ll look at what it takes to deliver the agentic workforce of the future in even the most secure and highly regulated environments, the risks of getting it wrong, and how DataRobot and NVIDIA have come together to solve it.
With the recently announced Agent Workforce Platform and NVIDIA AI Factory for Government reference design, organizations can now deploy agentic AI anywhere, from commercial clouds to air-gapped and sovereign installations, with secure access to NVIDIA Nemotron reasoning models and complete lifecycle control.
Fit-for-purpose agentic AI in secure environments
No two environments are the same when it comes to building an agentic AI stack. In air-gapped, sovereign, or mission-critical environments, every component, from hardware to model, must be designed and validated for interoperability, compliance, and observability.
Without that foundation, projects stall as teams spend months testing, integrating, and revalidating tools. Budgets expand while timelines slip, and the stack grows more complex with each new addition. Teams often end up choosing between the tools they had time to vet, rather than what best fits the mission.
The result is a system that not only misaligns with business needs, where simply maintaining and updating components can cause operations to slow to a crawl.
Starting with validated components and a composable design addresses these challenges by ensuring that every layer—from accelerated infrastructure to development environments to agentic AI in production—operates securely and reliably as one system.
A validated solution from DataRobot and NVIDIA
DataRobot and NVIDIA have shown what is possible by delivering a fully validated, full-stack solution for agentic AI. Earlier this year, we introduced the DataRobot Agent Workforce Platform, a first-of-its-kind solution that enables organizations to build, operate, and govern their own agentic workforce.
Co-developed with NVIDIA, this solution can be deployed on-prem and even air-gapped environments, and is fully validated for the NVIDIA Enterprise AI Factory for Government reference architecture. This collaboration gives organizations a proven foundation for developing, deploying, and governing their agentic AI workforce across any environment with confidence and control.
This means flexibility and choice at every layer of the stack, and every component that goes into agentic AI solutions. IT teams can start with their unique infrastructure and choose the components that best fit their needs. Developers can bring the latest tools and models to where their data sits, and rapidly test, develop, and deploy where it can provide the most impact while ensuring security and regulatory rigor.
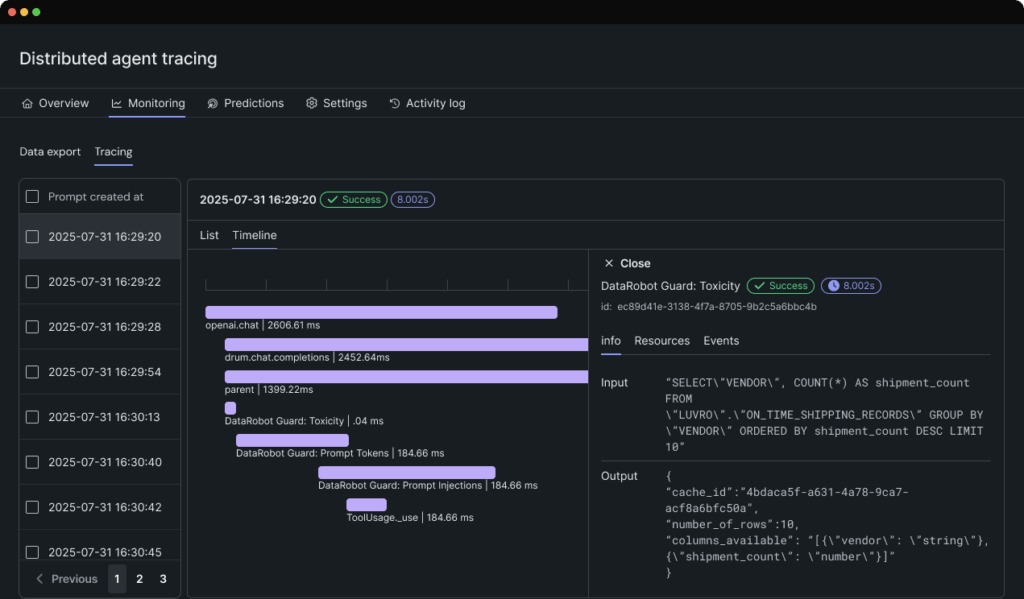
With the DataRobot Workbench and Registry, users gain access to NVIDIA NIM microservices with over 80 NIM, prebuilt templates, and assistive development tools that accelerate prototyping and optimization. Tracing tables and a visual tracing interface make it easy to compare at the component level and then fine tune performance of full workflows before agents move to production.
With easy access to NVIDIA Nemotron reasoning models, organizations can deliver a flexible and intelligent agentic workforce wherever it’s needed. NVIDIA Nemotron models merge the full-stack engineering expertise of NVIDIA with truly open-source accessibility, to empower organizations to build, integrate, and evolve agentic AI in ways that drive rapid innovation and impact across diverse missions and industries.
When agents are ready, organizations can deploy and monitor them with just a few clicks —integrating with existing CI/CD pipelines, applying real-time moderation guardrails, and validating compliance before going live.
The NVIDIA AI Factory for Government provides a trusted foundation for DataRobot with a full stack, end-to-end reference design that brings the power of AI to highly regulated organizations. Together, the Agent Workforce Platform and NVIDIA AI Factory deliver the most comprehensive solution for building, operating, and governing intelligent agentic AI on-premises, at the edge, and in the most secure environments.
Real-world agentic AI at the edge: Radio Intelligence Agent (RIA)
Deepwave, DataRobot, and NVIDIA have brought this validated solution to life with the Radio Intelligence Agent (RIA). This joint solution enables transformation of radio frequency (RF) signals into complex analysis — simply by asking a question.
Deepwave’s AIR-T sensors capture and process radio-frequency (RF) signals locally, removing the need to transmit sensitive data off-site. NVIDIA’s accelerated computing infrastructure and NIM microservices provide the secure inference layer, while NVIDIA Nemotron reasoning models interpret complex patterns and generate mission-ready insights.
DataRobot’s Agent Workforce Platform orchestrates and manages the lifecycle of these agents, ensuring each model and microservice is deployed, monitored, and audited with full control. The result is a sovereign-ready RF Intelligence Agent that delivers continuous, proactive awareness and rapid decision support at the edge.
This same design can be adapted across use cases such as predictive maintenance, financial stress testing, cyber defense, and smart-grid operations. Here are just a few applications for high-security agentic systems:
Industrial & energy (edge / on-Prem)
Federal & secure environments
Financial services
Pipeline fault detection and predictive maintenance
Signal intelligence processing for secure comms monitoring
Cutting-edge trading research
Oil rig operations monitoring and safety compliance
Classified data analysis in air-gapped environments
Credit risk scoring with controlled data residency
Critical infra smart grid anomaly detection and reliability assurance
Secure battlefield logistics and supply chain optimization
Anti-money laundering (AML) with sovereign data handling
Remote mining site equipment health monitoring
Cyber defense and intrusion detection in restricted networks
Stress testing and scenario modeling under compliance controls
Agentic AI built for the mission
Success in operationalizing agentic AI in high-security environments means going beyond balancing innovation with control. It means efficiently delivering the right solution for the job, where it’s needed, and keeping it running to the highest performance standards. It means scaling from one agentic solution to an agentic workforce with complete visibility and trust.
When every component, from infrastructure to orchestration, works together, organizations gain the flexibility and assurance needed to deliver value from agentic AI, whether in a single air-gapped edge solution or an entire self-managed agentic AI workforce.
With NVIDIA AI Factory for Government providing the trusted foundation and DataRobot’s Agent Workforce Platform delivering orchestration and control, enterprises and agencies can deploy agentic AI anywhere with confidence, scaling securely, efficiently, and with complete visibility.
To learn more how DataRobot can help advance your AI ambitions, visit us at datarobot.com/government.
This blog will explore how the joint solution from DataRobot and Deepwave — powered by NVIDIA — delivers a secure, high-performance AI stack, purpose-built for air-gapped, on-premises and high-security deployments. This solution ensures agencies can achieve genuine data sovereignty and operational excellence.
The need for autonomous intelligence
AI is evolving rapidly, transforming from simple tools into autonomous agents that can reason, plan, and act. This shift is critical for high-stakes, mission-critical applications such as signals intelligence (SIGINT), where vast RF data streams demand real-time analysis.
Deploying these advanced agents for public and government programs requires a new level of security, speed, and accuracy that traditional RF analysis solutions cannot provide.
Program leaders often find themselves choosing between underperforming, complex solutions that generate technical debt or a single-vendor lock-in. The pressure to deliver next-generation RF intelligence does not subside, leaving operations leaders under pressure to deploy with few options.
The challenge of radio intelligence
Signals intelligence, the real-time collection and analysis of radio frequency (RF) signals, spans both communications (COMINT) and emissions from electronic systems (ELINT). In practice, this often means extracting the content of RF signals — audio, video, or data streams — a process that presents significant challenges for federal agencies.
Modern RF signals are highly dynamic and require equally nimble analysis capabilities to keep up.
Operations often take place at the edge in contested environments, where manual analysis is too slow and not scalable.
High data rates and signal complexity make RF data extraordinarily difficult to use, and dynamically changing signals require an analysis platform that can adapt in real-time.
The mission-critical need is for an automated and highly reconfigurable solution that can quickly extract actionable intelligence from these vast amounts of data, ensuring timely, potentially life-saving decision-making and reasoning.
Introducing the Radio Intelligence Agent
To meet this critical need, the Radio Intelligence Agent (RIA) was engineered as an autonomous, proactive intelligence system that transforms raw RF signals into a constantly evolving, context-driven resource. The solution is designed to serve as a smart team member, providing new insights and recommendations that are far beyond search engine capabilities.
What truly sets the RIA apart from current technology is its integrated reasoning capability. Powered by NVIDIA Nemotron reasoning models, the system is capable of synthesizing patterns, flagging anomalies, and recommending actionable responses, effectively bridging the gap between mere information retrieval and operational intelligence.
Developed jointly by DataRobot and Deepwave, and powered by NVIDIA, this AI solution transforms raw RF signals into conversational intelligence, with its entire lifecycle orchestrated by the trusted, integrated control plane of the DataRobot Agent Workforce Platform.
Federal use cases and deployment
The Radio Intelligence Agent is engineered specifically for the stringent demands of federal operations, with every component built for security, compliance, and deployment flexibility.
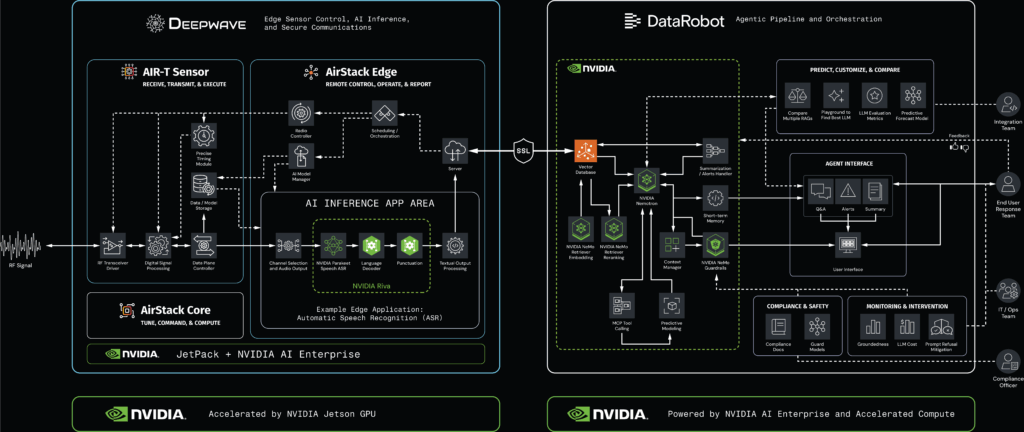
The power of the RIA solution lies in performing a significant amount of processing at the edge within Deepwave’s AirStack Edge ecosystem. This architecture ensures high-performance processing while maintaining essential security and regulatory compliance.
The Radio Intelligence Agent solution moves operations teams from simple data collection and analysis to proactive, context-aware intelligence, enabling event prevention instead of event management. This is a step change in public safety capabilities.
Event response optimization: The solution goes beyond simple alerts by acting as a digital advisor during unfolding situations. It analyzes incoming data in real-time, identifies relevant entities and locations, and recommends next-best actions to reduce response time and improve outcomes.
Operational awareness: The solution enhances visibility across multiple data streams, including audio and video feeds, as well as sensor inputs, to create a unified view of activity in real-time. This broad monitoring capability reduces cognitive burden and helps teams focus on strategic decision-making rather than manual data analysis.
Other applications: RIA’s core capabilities are applicable for scenarios requiring fast, secure, and accurate analysis of massive data streams – including public safety, first responders, and other functions.
This solution is also portable, supporting local development and testing, with the ability to transition seamlessly into private cloud or FedRAMP-authorized DataRobot-hosted environments for secure production in federal missions.
A deeper dive into the Radio Intelligence Agent
Imagine receiving complex RF signals analysis that are trusted, high-fidelity, and actionable in seconds, simply by asking a question.
DataRobot, Deepwave, and NVIDIA teamed up to make this a reality.
First, Deepwave’s AIR-T edge sensors receive and digitize the RF signals using AirStack software, powered by embedded NVIDIA GPUs.
Then, the newest AirStack component, AirStack Edge, introduces a secure API with FIPS-grade encryption, enabling the deployment of signal processing applications and NVIDIA Riva Speech and Translation AI models directly on AIR-T devices.
This end-to-end process runs securely and in real-time, delivering extracted data content into the agent-based workflows orchestrated by DataRobot.
The solution’s agentic capability is rooted in a sophisticated, two-part system that leverages NVIDIA Llama-3_1-Nemotron-Ultra-253B-v1 to interpret context and generate sophisticated responses.
Query Interpreter: This component is responsible for understanding the user’s initial intent, translating the natural language question into a defined information need.
Information Retriever: This agent executes the necessary searches, retrieves relevant transcript chunks, and synthesizes the final, cohesive answer by connecting diverse data points and applying reasoning to the retrieved text.
This functionality is delivered through the NVIDIA Streaming Data to RAG solution, which enables real-time ingestion and processing of live RF data streams using GPU-accelerated pipelines.
By leveraging NVIDIA’s optimized vector search and context synthesis, the system allows for fast, secure, and context-driven retrieval and reasoning over radio-transcribed data while ensuring both operational speed and regulatory compliance.
The agent first consults a vector database, which stores semantic embeddings of transcribed audio and sensor metadata, to find the most relevant information before generating a coherent response. The sensor metadata is customizable and contains critical information about signals, including frequency, location, and reception time of the data.
The solution is equipped with several specialized tools that enable this advanced workflow:
RF orchestration: The solution can utilize Deepwave’s AirStack Edge orchestration layer to actively recollect new RF intelligence by running new models, recording signals, or broadcasting signals.
Search tools: It performs sub-second semantic searches across massive volumes of transcript data.
Time parsing tools: Converts human-friendly temporal expressions (e.g., “3 weeks ago”) into precise, searchable timestamps, leveraging the sub-10 nanosecond accuracy published in the metadata.
Audit trail: The system maintains a complete audit trail of all queries, tool usage, and data sources, ensuring full traceability and accountability.
NVIDIA Streaming Data to RAG Blueprint example enables the workflow to move from simple data lookup to autonomous, proactive intelligence. The GPU-accelerated software-defined radio (SDR) pipeline continuously captures, transcribes, and indexes RF signals in real-time, unlocking continuous situational awareness.
DataRobot Agent Workforce Platform: The integrated control plane
The DataRobot Agent Workforce Platform, co-developed with NVIDIA, serves as the agentic pipeline and orchestration layer, the control plane that orchestrates the entire lifecycle. This ensures agencies maintain full visibility and control over every layer of the stack and enforce compliance automatically.
Key functions of the platform include:
End-to-end control: Automates the entire AI lifecycle, from development and deployment to monitoring and governance, allowing agencies to field new capabilities faster and more reliably.
Design Architecture: Purpose-built with the NVIDIA Enterprise AI Factory architecture, ensuring the entire stack is validated and production-ready from day one.
Data sovereignty: DataRobot’s solution is purpose-built for high-security environments, deploying directly into the agency’s air-gapped or on-premises infrastructure. All processing occurs within the security perimeter, ensuring complete data sovereignty and guaranteeing the agency retains sole control and ownership of its data and operations.
Crucially, this provides operational autonomy (or sovereignty) over the entire AI stack, as it requires no external providers for the operational hardware or models. This ensures the full AI capability remains within the agency’s controlled domain, free from external dependencies or third-party access.
DataRobot integrates with highly skilled, specialized partners like Deepwave, who provide the critical AI edge processing to convert raw RF signal content into RF intelligence and securely share it with DataRobot’s data pipelines. The Deepwave platform extends this solution’s capabilities by enabling the next steps in RF intelligence gathering through the orchestration and automation of RF AI edge tasks.
Edge AI processing: The agent uses Deepwave’s high-performance edge computing and AI models to intercept and process RF signals.
Reduced infrastructure: Instead of backhauling raw RF data, the solution runs AI models at the edge to extract only the critical information. This reduces network backhaul needs by a factor of 10 million — from 4 Gbps down to just 150 bps per channel — dramatically improving mobility and simplifying the required edge infrastructure.
Security: Deepwave’s AirStack Edge leverages the latest FIPS mode encryption to report this data to the DataRobot Agent Workforce Platform securely.
Orchestration: Deepwave’s AirStack Edge software orchestrates and automates networks of RF AI edge devices. This enables low-latency responses to RF scenarios, such as detecting and jamming unwanted signals.
NVIDIA: Foundational trust and performance
NVIDIA provides the high-performance and secure foundation necessary for federal missions.
Security: AI agents are built with production-ready NVIDIA NIM™ microservices. These NIM are built from a trusted, STIG-ready base layer and support FIPS mode encryption, making them the essential, pre-validated building blocks for achieving a FedRAMP deployment quickly and securely.
DataRobot provides an NVIDIA NIM gallery, which enables rapid consumption of accelerated AI models across multiple modalities and domains, including LLM, VLM, CV, embedding, and more, and direct integration into agentic AI solutions that can be deployed anywhere.
Reasoning: The agent’s core intelligence is powered by NVIDIA Nemotron models. These AI models with open weights, datasets, and recipes, combined with leading efficiency and accuracy, provide the high-level reasoning and planning capabilities for the agent, enabling it to excel at complex reasoning and instruction-following. It goes beyond simple lookups to connect complex data points, delivering true intelligence, not just data retrieval.
Speech & Translation: NVIDIA Riva Speech and Translation, enables real-time speech recognition, translation, and synthesis directly at the edge. By deploying Riva alongside AIR-T and AirStack Edge, audio content extracted from RF signals can be transcribed and translated on-device with low latency. This capability allows SIGINT agents to turn intercepted voice traffic into actionable, multilingual data streams that seamlessly flow into DataRobot’s agentic AI workflows.
A collaborative approach to mission-critical AI
The combined strengths of DataRobot, NVIDIA, and Deepwave create a comprehensive, secure, production-ready solution:
DataRobot: End-to-end AI lifecycle orchestration and control.
NVIDIA: Aaccelerated GPU infrastructure, optimized software frameworks, validated designs, secure and performant foundation models and microservices.
Deepwave: RF sensors with embedded GPU edge processing, secure datalinks, and streamlined orchestration software.
Together, these capabilities power the Radio Intelligence Agent solution, demonstrating how agentic AI, built on the DataRobot Agent Workforce Platform, can bring real-time intelligence to the edge. The result is a trusted, production-ready path to data sovereignty and autonomous, proactive intelligence for the federal mission.
For more information on using RIA to turn RF data into real time insights, visit deepwave.ai/ria.
To learn more about how we can help advance your agency’s AI ambitions, connect with DataRobot federal experts.
For centuries, visions of the future have been dominated by dystopian warnings—cautionary tales of power gone wrong. Five Pillars of Tomorrow offers an alternative: a governance model where transparency, collective wisdom, and advanced AI safeguard human dignity.
For centuries, visions of the future have been dominated by dystopian warnings—cautionary tales of power gone wrong. Five Pillars of Tomorrow offers an alternative: a governance model where transparency, collective wisdom, and advanced AI safeguard human dignity.
Researchers at Tsinghua University developed the Optical Feature Extraction Engine (OFE2), an optical engine that processes data at 12.5 GHz using light rather than electricity. Its integrated diffraction and data preparation modules enable unprecedented speed and efficiency for AI tasks. Demonstrations in imaging and trading showed improved accuracy, lower latency, and reduced power demand. This innovation pushes optical computing toward real-world, high-performance AI.
There’s a common misconception that AGVs are outdated while AMRs are cutting-edge. In
reality, both have evolved considerably in recent years, and modern mobile robots increasingly blur the lines between the two.
A talented teenager from the UK has built a four-fingered robotic hand from standard Lego parts that performs almost as well as research-grade robotic hands. The anthropomorphic device can grasp, move and hold objects with remarkable versatility and human-like adaptability.
Robotics has moved from “point fixes” on isolated stations to the connective tissue of the entire supply chain. In practical terms, that means robots are continuously progressing from just weld or pick.
For the past several years, the world has been mesmerized by the creative and intellectual power of artificial intelligence (AI). We have watched it generate art, write code, and discover new medicines. Now, as of October 2025, we are handing […]
For workers whose jobs involve hours of lifting and repetitive motion, even small innovations can make a big difference in preventing future musculoskeletal disorders.
The 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 2025) took place from October 19 to 25, 2025 in Hangzhou, China. The programme included plenary and keynote talks, workshops, tutorials, forums, competitions, and a debate. There was also an exhibition where companies and institutions were able to showcase their latest hardware and software.
We cast an eye over the social media platforms to see what participants got up to during the week.
This week, we are participating in the IEEE/RSJ International Conference on Intelligent Robots and Systems #IROS2025 in Hangzhou #China
(IRI researchers right-left): @juliaborrassol.bsky.social, David Blanco-Mulero and Anais Garrell
At #IROS2025 General Chair Professor Hesheng Wang and Program Chair Professor Yi Guo share what makes this year’s conference unique, from the inspiring location to the latest research shaping the future of intelligent robotics. youtu.be/_JzGoH7wilU
From Hangzhou, #IROS2025 unites the brightest minds in #Robotics, #AI & intelligent systems to explore the Human–Robotics Frontier. Watch IROS TV for highlights, interviews, and a behind-the-scenes look at the labs shaping our robotic future. youtu.be/SojyPncpH1g
#IROS2025 Only 16 years old, Jared K. Lepora stood out as the youngest presenter at this year’s IROS, impressively showcasing the dexterous robotic hand he designed in the Educational and Emotional Robots session this afternoon. pic.twitter.com/toOavpfk26
Write With ChatGPT – Without Ever Leaving the Gmail Compose Box
ChatGPT’s maker just rolled-out an incredibly new and powerful feature for email, which enables you to use the AI to write and edit an email directly inside the Gmail compose box.
Already available for Mac users, the new feature – part of the new ChatGPT-powered browser ‘Atlas’ – is promised for Windows users in a few weeks.
A boon for people who spend considerable time cranking out emails each day, the new capability eliminates the need to jump back-and-forth between ChatGPT and Gmail when composing an email with the AI.
Instead, users can simply click open a Gmail compose box to start an email, then click on a tiny ChatGPT logo that appears in the upper left-hand corner to create an email using ChatGPT.
Essentially: No more opening a Gmail compose box on one tab, then logging into ChatGPT and opening a second tab to access ChatGPT — and then cutting-and-pasting text back-and-forth from one tab to the other to come up with an email you want to send
Instead, everything is done for you inline in a single, Gmail compose box.
Even better: You can also use the new feature to highlight text you’ve already created in a Gmail compose box — then edit that text with ChatGPT and then send when you’re satisfied with the results.
Plus, ChatGPT’s Atlas ups-the-ante even further by enabling you to use the same write-in-the-app capability in Google Docs.
And it works the same way: Simply click on a tiny ChatGPT logo that appears when you hover in the top left-hand corner of a Google Doc, enter in a prompt you want the AI to use to write text for you, click enter and ChatGPT writes exactly what you’re looking for – without you ever being forced to go outside the Google Doc for help.
In a phrase: Once word of this stellar new convenience spreads across the Web, it seems certain that there will be a stampede of people embracing the idea of using ChatGPT without ever needing to leave Gmail or Google Docs.
That should especially be the case given that the new feature is currently available on the Mac to all tier levels of ChatGPT, including the ChatGPT free level – with availability to Windows users promised soon.
Here’s how the new auto-writing feature works, step by step:
To Create New Text in Gmail Using ChatGPT In-App:
Open a new compose box in Gmail
Hover over the blinking cursor in the upper left-hand corner in the compose box until a tiny ChatGPT logo appears
Click on the tiny ChatGPT logo
A tiny prompt box appears
Enter in a writing prompt – the same kind of writing prompt you’d ordinarily use to trigger ChatGPT to write an email for you
A drop-down window appears, showcasing the text that ChatGPT just wrote for you
Click Insert to accept the text that ChatGPT wrote from you into your Gmail
Click ‘Send’ to send your email
To Edit Text You’ve Already Written in a Gmail Compose Box:
Highlight the text you’ve already created in the Gmail compose box
A tiny ChatGPT logo appears in the upper left-hand corner of the Gmail compose box
Click on the tiny ChatGPT logo
A prompt box appears
Type your instructions for editing the email in the prompt window
Click Enter
ChatGPT’s edit of your email appears in a drop-down box
Read over the text ChatGPT has edited for you
Click Update to add the edited text to your Gmail
Click Send to send your Gmail.
To Create/Edit Text in Google Docs:
Follow the same prompts above to create or edit in Google Docs
For an extremely excellent, extremely clear video demo of the steps above, click to this video by The Tech Girl and advance to timestamp 4:58 in the video to see what the step-by-step looks like on a PC screen.
Groundbreaking in its own right, the new write-in-the-app capability is one of a flurry of features that come with the new ChatGPT-powered browser Atlas, released a few days ago.
With the release of Atlas, ChatGPT’s maker OpenAI is hoping to capitalize on the 800 million visits made each week to the ChatGPT Web site.
Those visitors represent a motivated, ChatGPT-inspired audience. And OpenAI is hoping that by making its own AI-powered browser available to those people, they’ll abandon Google Chrome and start using Atlas to surf the Web.
Like Perplexity Comet – another new, AI-powered browser looking to carve into the Google Chrome market – Atlas is designed to work like an everyday browser that’s supercharged with AI at its core.
–Turbo-charge many browser actions with ChatGPT –Offer a left sidebar featuring a history of all your chats with ChatGPT –Enable you to search your search history using ChatGPT –Get to know you better by remembering what you’ve done with Atlas in the past –Offer suggested links for you, based on your previous searches with Atlas –Work as an AI agent for you and complete multi-step tasks, such as finding news for you on the Web and summarizing each news item for you that includes a hotlink to the original news source –Engage in Deep Research –Pivot into using a traditional search engine view while searching –Enable you to open say 20 Web sites, then analyze and summarize those Web sites with ChatGPT –Integrate with apps like Canva, Spotify and more –Auto-summarize a YouTube video for you without the need to generate a transcript of that video
Share a Link: Please consider sharing a link to https://RobotWritersAI.com from your blog, social media post, publication or emails. More links leading to RobotWritersAI.com helps everyone interested in AI-generated writing.
–Joe Dysart is editor of RobotWritersAI.com and a tech journalist with 20+ years experience. His work has appeared in 150+ publications, including The New York Times and the Financial Times of London.
International Robot Safety Conference (IRSC) – 3-5 November 2025 – Houston, USA – https://www.automate.org/events/international-robot-safety-conference RobotWorld 2025 – 5-8 November 2025 – Goyang (KINTEX), South Korea – http://eng.robotworld.or.kr/ Get Together for Robotics 2025 – 5-6 November 2025 – Nuremberg/Erlangen, Germany – https://www.profibus.com/get-together-for-robotics/ ICRAI 2025 (11th International Conference on Robotics & Artificial Intelligence) – 19-21 December 2025 […]


 This week, we are participating in the IEEE/RSJ International Conference on Intelligent Robots and Systems #IROS2025 in Hangzhou #China
This week, we are participating in the IEEE/RSJ International Conference on Intelligent Robots and Systems #IROS2025 in Hangzhou #China  (IRI researchers right-left): @juliaborrassol.bsky.social, David Blanco-Mulero and Anais Garrell
(IRI researchers right-left): @juliaborrassol.bsky.social, David Blanco-Mulero and Anais Garrell 



