Automate 2023 Product Preview
Automate 2023 takes place May 22nd - 25th in Detroit, Michigan. The Exhibit hall floor will be loaded with new products and services. Here is a preview of some things to look forward to at this years event.
Credit: Thomas Hartung, Johns Hopkins University
By Liad Hollender, Frontiers science writer
Despite AI’s impressive track record, its computational power pales in comparison with that of the human brain. Scientists unveil a revolutionary path to drive computing forward: organoid intelligence (OI), where lab-grown brain organoids serve as biological hardware. “This new field of biocomputing promises unprecedented advances in computing speed, processing power, data efficiency, and storage capabilities – all with lower energy needs,” say the authors in an article published in Frontiers in Science.
Artificial intelligence (AI) has long been inspired by the human brain. This approach proved highly successful: AI boasts impressive achievements – from diagnosing medical conditions to composing poetry. Still, the original model continues to outperform machines in many ways. This is why, for example, we can ‘prove our humanity’ with trivial image tests online. What if instead of trying to make AI more brain-like, we went straight to the source?
Scientists across multiple disciplines are working to create revolutionary biocomputers where three-dimensional cultures of brain cells, called brain organoids, serve as biological hardware. They describe their roadmap for realizing this vision in the journal Frontiers in Science.
“We call this new interdisciplinary field ‘organoid intelligence’ (OI),” said Prof Thomas Hartung of Johns Hopkins University. “A community of top scientists has gathered to develop this technology, which we believe will launch a new era of fast, powerful, and efficient biocomputing.”
Brain organoids are a type of lab-grown cell-culture. Even though brain organoids aren’t ‘mini brains’, they share key aspects of brain function and structure such as neurons and other brain cells that are essential for cognitive functions like learning and memory. Also, whereas most cell cultures are flat, organoids have a three-dimensional structure. This increases the culture’s cell density 1,000-fold, meaning that neurons can form many more connections.
But even if brain organoids are a good imitation of brains, why would they make good computers? After all, aren’t computers smarter and faster than brains?
“While silicon-based computers are certainly better with numbers, brains are better at learning,” Hartung explained. “For example, AlphaGo [the AI that beat the world’s number one Go player in 2017] was trained on data from 160,000 games. A person would have to play five hours a day for more than 175 years to experience these many games.”
Brains are not only superior learners, they are also more energy efficient. For instance, the amount of energy spent training AlphaGo is more than is needed to sustain an active adult for a decade.
“Brains also have an amazing capacity to store information, estimated at 2,500TB,” Hartung added. “We’re reaching the physical limits of silicon computers because we cannot pack more transistors into a tiny chip. But the brain is wired completely differently. It has about 100bn neurons linked through over  connection points. It’s an enormous power difference compared to our current technology.”
connection points. It’s an enormous power difference compared to our current technology.”
According to Hartung, current brain organoids need to be scaled-up for OI. “They are too small, each containing about 50,000 cells. For OI, we would need to increase this number to 10 million,” he explained.
In parallel, the authors are also developing technologies to communicate with the organoids: in other words, to send them information and read out what they’re ‘thinking’. The authors plan to adapt tools from various scientific disciplines, such as bioengineering and machine learning, as well as engineer new stimulation and recording devices.
“We developed a brain-computer interface device that is a kind of an EEG cap for organoids, which we presented in an article published last August. It is a flexible shell that is densely covered with tiny electrodes that can both pick up signals from the organoid, and transmit signals to it,” said Hartung.
The authors envision that eventually OI would integrate a wide range of stimulation and recording tools. These will orchestrate interactions across networks of interconnected organoids that implement more complex computations.
OI’s promise goes beyond computing and into medicine. Thanks to a groundbreaking technique developed by Noble Laureates John Gurdon and Shinya Yamanaka, brain organoids can be produced from adult tissues. This means that scientists can develop personalized brain organoids from skin samples of patients suffering from neural disorders, such as Alzheimer’s disease. They can then run multiple tests to investigate how genetic factors, medicines, and toxins influence these conditions.
“With OI, we could study the cognitive aspects of neurological conditions as well,” Hartung said. “For example, we could compare memory formation in organoids derived from healthy people and from Alzheimer’s patients, and try to repair relative deficits. We could also use OI to test whether certain substances, such as pesticides, cause memory or learning problems.”
Creating human brain organoids that can learn, remember, and interact with their environment raises complex ethical questions. For example, could they develop consciousness, even in a rudimentary form? Could they experience pain or suffering? And what rights would people have concerning brain organoids made from their cells?
The authors are acutely aware of these issues. “A key part of our vision is to develop OI in an ethical and socially responsible manner,” Hartung said. “For this reason, we have partnered with ethicists from the very beginning to establish an ‘embedded ethics’ approach. All ethical issues will be continuously assessed by teams made up of scientists, ethicists, and the public, as the research evolves.”
Even though OI is still in its infancy, a recently-published study by one of the article’s co-authors – Dr Brett Kagan, Chief Scientific Officer at Cortical Labs – provides proof of concept. His team showed that a normal, flat brain cell culture can learn to play the video game Pong.
“Their team is already testing this with brain organoids,” Hartung added. “And I would say that replicating this experiment with organoids already fulfills the basic definition of OI. From here on, it’s just a matter of building the community, the tools, and the technologies to realize OI’s full potential,” he concluded.

Image: Prof Thomas Hartung
To learn more about this exciting new field, we interviewed the senior author of the article, Prof Thomas Hartung. He is the director of the Center for Alternatives to Animal Testing in Europe (CAAT-Europe), and a professor at Johns Hopkins University’s Bloomberg School of Public Health.
How do you define organoid intelligence?
Reproducing cognitive functions – such as learning and sensory processing – in a lab-grown human-brain model.
How did this idea emerge?
I’m a pharmacologist and toxicologist, so I’m interested in developing medicines and identifying substances that are dangerous to our health, specifically those that affect brain development and function. This requires testing – ideally in conditions that mimic a living brain. For that reason, producing cultures of human brain cells has been a longstanding aim in the field.
This goal was finally realized in 2006 thanks to a groundbreaking technique developed by John B. Gurdon and Shinya Yamanaka, who received a Nobel prize for this achievement in 2012. This method allowed us to generate brain cells from fully developed tissues, such as the skin. Soon after, we began mass producing three-dimensional cultures of brain cells called brain organoids.
People asked if the organoids were thinking, if they were conscious even. I said: “no, they are too tiny. And more importantly, they don’t have any input nor output, so what would they be thinking about?” But later I began wondering: what if we changed this? What if we gave the organoids information about their environment and the means to interact with it? That was the birth of organoid intelligence.
How would you know what an organoid is ‘thinking’ about?
We’re building tools that will enable us to communicate with the organoids – send input and receive output. For example, we developed a recording/stimulation device that looks like a mini EEG-cap that surrounds the organoid. We’ve also been working on feeding biological inputs to brain organoids, for instance, by connecting them to retinal organoids, which respond to light. Our partner and co-author Alysson Muotri at the University of San Diego is already testing this approach by producing systems that combine several organoids.
My dream is to form a channel of communication between an artificial intelligence program and an OI system that would allow the two to explore each other’s capabilities. I imagine that form will follow function – that the organoid will change and develop towards creating meaningful inputs. This is a bit of philosophy, but my expectation is that we’ll see a lot of surprises.
What uses do you envision for organoid intelligence?
In my opinion, there are three main areas. The first is fundamental neuroscience – to understand how the brain generates cognitive functions, such as learning and memory. Even though current brain organoids are still far from being what one might call intelligent, they could still have the machinery to support basic cognitive operations.
The second area is toxicology and pharmacology. Since we can now produce brain organoids from skin samples, we can study individual disease characteristics of patients. We already have brain-organoid lines from Alzheimer’s patients, for example. And even though these organoids were made from skin cells, we still see hallmarks of the disease in them.
Next, we would like to test if there are also differences in their memory function, and if so, if we could repair it. We can also test whether substances, such as pesticides, worsen cognitive deficits, or cause them in brain organoids produced from healthy subjects. This is a very exciting line of research, which I believe is nearly within reach.
The third area is computing. As we laid out in our article, considering the brain’s size, its computational power is simply unmatched. Just for comparison, a supercomputer finally surpassed the computational power of a single human brain in 2022. But it cost $600m and occupies 680 square meters [about twice the area of a tennis court].
We’re also reaching the limits of computing. Moore’s Law, which states that the number of transistors in a microchip doubles every two years, has held for 60 years. But soon we won’t be able to physically fit more transistors into a chip. A single neuron, on the other hand, can connect to up to 10,000 other neurons – this is a very different way of processing and storing information. Through OI, we hope that we’ll be able to leverage the brain’s computational principles to build computers differently.
How do you intend to tackle ethical issues that might arise from organoid intelligence?
There are many questions that we face now, ranging from the rights of people over organoids developed from their cells, to understanding whether OI is conscious. I find this aspect of the work fascinating, and I believe it’s a fantastic opportunity to investigate the physical manifestation of concepts like sentience and consciousness.
We teamed up with Jeffrey Kahn of the Bloomberg School of Public Health at Johns Hopkins University at the very beginning, asking him to lead the discussion around the ethics of neural systems. We have come up with two main strategies. One is called embedded ethics: we want ethicists to closely observe the work, take part in the planning, and raise points early on. The second part focuses on the public – we intend to share our work broadly and clearly as it advances. We want to know how people feel about this technology and define our research plan accordingly.
How far are we from the first organoid intelligence?
Even though OI is still in its infancy, past work shows that it’s possible. A study by one of our partners and co-authors – Brett Kagan of the Cortical Labs – is a recent example. His team showed that a standard brain cell culture can learn to play the video game Pong. They are already experimenting with brain organoids, and I would say that replicating this with organoids already fulfills what we call OI.
Still, we are a long way from realizing OI’s full potential. When it becomes a real tool, it will look very different from these first baby steps we are taking now. The important thing is that it’s a starting point. I see this like sequencing the first genes of the human genome project: the enabling technology is in our hands, and we’re bound to learn a lot on the way.
This post is a combination of the original articles published on the Frontiers in Robotics and AI blog. You can read the originals here and here.

Claire chatted to Helmut Hauser from the University of Bristol all about soft robotics, sensing, and smart robot bodies.
Helmut Hauser is an Associate Professor in Robotics at the University of Bristol and the Bristol Robotics Laboratory. He is also the Director of the EPSRC Centre of Doctoral Training for Robotics and Autonomous Systems. Helmut’s research is focused on morphological computation and soft robotics. In particular, he is interested in understanding the underlying principles of how biological systems exploit their complex physical bodies to facilitate sensing, controlling and learning, and how these principles can be employed to design better bodies to build better robots.
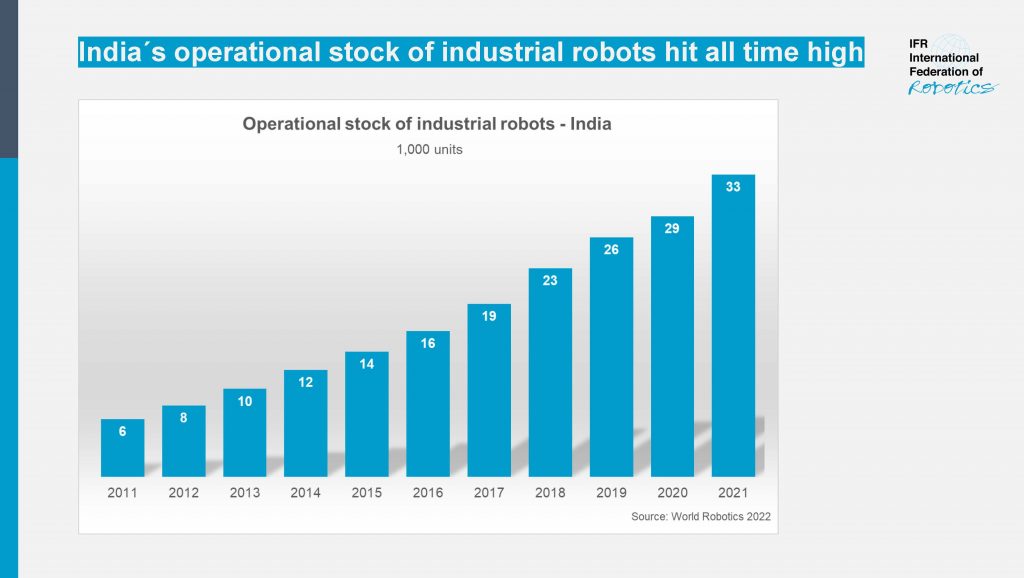
India´s operational stock of industrial robots hit all time high.
Sales of industrial robots in India reached a new record of 4,945 units installed. This is an increase of 54 percent compared to the previous year (2020: 3,215 units). In terms of annual installations, India now ranks in tenth position worldwide. These are findings of the report World Robotics, presented by the International Federation of Robotics (IFR).
“India is one of the world’s fastest-growing industrial economies,” says Marina Bill, President of the International Federation of Robotics. “Within five years, the operational stock of industrial robots has more than doubled, to reach 33,220 units in 2021. This corresponds to an average annual growth rate of 16% since 2016.”
Today, India is the world’s fifth largest economy measured by manufacturing output. According to World Bank data, India´s manufacturing value added in 2021 was USD 443.9 billion, a 21.6% increase from 2020.
The automotive industry remains the largest customer for the robotics industry in India with a share of 31% in 2021. Installations more than doubled to 1,547 units (+108%). The general industry in India is led by the metal industry with 308 units (-9%), the rubber and plastics industry with 246 units (+27%) and the electrical/electronics industry with 215 units (+98%).
The long-term potential of robotics in India becomes clearer when compared to China: India´s robot density in the automotive industry, which is the number of industrial robots per 10,000 employees, reached 148 robots in 2021. China´s robot density hit 131 units in 2010 and skyrocketed to 772 units in 2021.
The Indian government supports growth in the industrial sector as one of the vital figures that affect the Gross Domestic Product (GDP). Today, the country´s GDP of about USD 3 trillion ranks in fifth place, head-to-head with the UK and France – behind Germany, Japan, China and the USA – the International Monetary Fund reports.
“As a result of the recent supply chain disruption, companies are rethinking their nearshoring strategies in Southeast Asia,” says Marina Bill. “India has traditionally been a popular destination for nearshoring in the manufacturing segment. The Indian government wants the country to be considered for new diversification options such as friendshoring, which is partnering with countries that share similar values and interests.”
The manufacturing sector is also expected to benefit from the government’s initiatives to boost its competitiveness and attractiveness for investors. The Production Linked Incentive (PLI) scheme, for example, currently set to run until 2025, subsidizes companies that create production capacity in India in robot customer industries like automotive, metal, pharmaceuticals, and food processing.
New manufacturing capacities in India are an important step to provide adequate education and employment opportunities for its people: According to projections of the United Nations, India now has a population of 1,4 billion, surpassing China for the first time. This means that India has a large and young workforce that can drive economic growth and innovation. India is expected to have the largest working-age population in the world by 2027.