Smart robots do all the work at Nissan’s ‘intelligent’ plant
Nissan's "intelligent factory" hardly has any human workers. The robots do the work, including welding and mounting. They do the paint jobs and inspect their own paint jobs.

When it comes to exploring complex and unknown environments such as forests, buildings or caves, drones are hard to beat. They are fast, agile and small, and they can carry sensors and payloads virtually everywhere. However, autonomous drones can hardly find their way through an unknown environment without a map. For the moment, expert human pilots are needed to release the full potential of drones.
“To master autonomous agile flight, you need to understand the environment in a split second to fly the drone along collision-free paths,” says Davide Scaramuzza, who leads the Robotics and Perception Group at the University of Zurich and the NCCR Robotics Rescue Robotics Grand Challenge. “This is very difficult both for humans and for machines. Expert human pilots can reach this level after years of perseverance and training. But machines still struggle.”
In a new study, Scaramuzza and his team have trained an autonomous quadrotor to fly through previously unseen environments such as forests, buildings, ruins and trains, keeping speeds of up to 40 km/h and without crashing into trees, walls or other obstacles. All this was achieved relying only on the quadrotor’s on-board cameras and computation.
The drone’s neural network learned to fly by watching a sort of “simulated expert” – an algorithm that flew a computer-generated drone through a simulated environment full of complex obstacles. At all times, the algorithm had complete information on the state of the quadrotor and readings from its sensors, and could rely on enough time and computational power to always find the best trajectory.
Such a “simulated expert” could not be used outside of simulation, but its data were used to teach the neural network how to predict the best trajectory based only on the data from the sensors. This is a considerable advantage over existing systems, which first use sensor data to create a map of the environment and then plan trajectories within the map – two steps that require time and make it impossible to fly at high-speeds.
After being trained in simulation, the system was tested in the real world, where it was able to fly in a variety of environments without collisions at speeds of up to 40 km/h. “While humans require years to train, the AI, leveraging high-performance simulators, can reach comparable navigation abilities much faster, basically overnight,” says Antonio Loquercio, a PhD student and co-author of the paper. “Interestingly these simulators do not need to be an exact replica of the real world. If using the right approach, even simplistic simulators are sufficient,” adds Elia Kaufmann, another PhD student and co-author.
The applications are not limited to quadrotors. The researchers explain that the same approach could be useful for improving the performance of autonomous cars, or could even open the door to a new way of training AI systems for operations in domains where collecting data is difficult or impossible, for example on other planets.
According to the researchers, the next steps will be to make the drone improve from experience, as well as to develop faster sensors that can provide more information about the environment in a smaller amount of time – thus allowing drones to fly safely even at speeds above 40 km/h.

An open-source version of the paper can be found here.
Prof. Dr. Davide Scaramuzza – Robotics and Perception Group
Department of Informatics
University of Zurich
Phone +41 44 635 24 09
E-mail: sdavide@ifi.uzh.ch
Antonio Loquercio – Robotics and Perception Group
Department of Informatics
University of Zurich
Phone +41 44 635 43 73
E-mail: loquercio@ifi.uzh.ch
Elia Kaufmann – Robotics and Perception Group
Institut für Informatik
Universität Zürich
Tel. +41 44 635 43 73
E-Mail: ekaufmann@ifi.uzh.ch
Media Relations University of Zurich
Phone +41 44 634 44 67
E-mail: mediarelations@kommunikation.uzh.ch

In this episode, Audrow Nash interviews Adrian Macneil, Co-founder and CEO of Foxglove. Foxglove makes Foxglove Studio, an open source visualization and debugging tool for robotics. Adrian speaks about the origin of Foxglove, Foxglove’s business model, web and robotics, and gives advice to those interested in getting more involved in robotics.
Episode links
Subscribe

By Daniel Quinn
Underwater vehicles haven’t changed much since the submarines of World War II. They’re rigid, fairly boxy and use propellers to move. And whether they are large manned vessels or small robots, most underwater vehicles have one cruising speed where they are most energy efficient.
Fish take a very different approach to moving through water: Their bodies and fins are very flexible, and this flexibility allows them to interact with water more efficiently than rigid machines. Researchers have been designing and building flexible fishlike robots for years, but they still trail far behind real fish in terms of efficiency.
I am an engineer and study fluid dynamics. My labmates and I wondered if something in particular about the flexibility of fish tails allows fish to be so fast and efficient in the water. So, we created a model and built a robot to study the effect of stiffness on swimming efficiency. We found fish swim so efficiently over a wide range of speeds because they can change how rigid or flexible their tails are in real time.
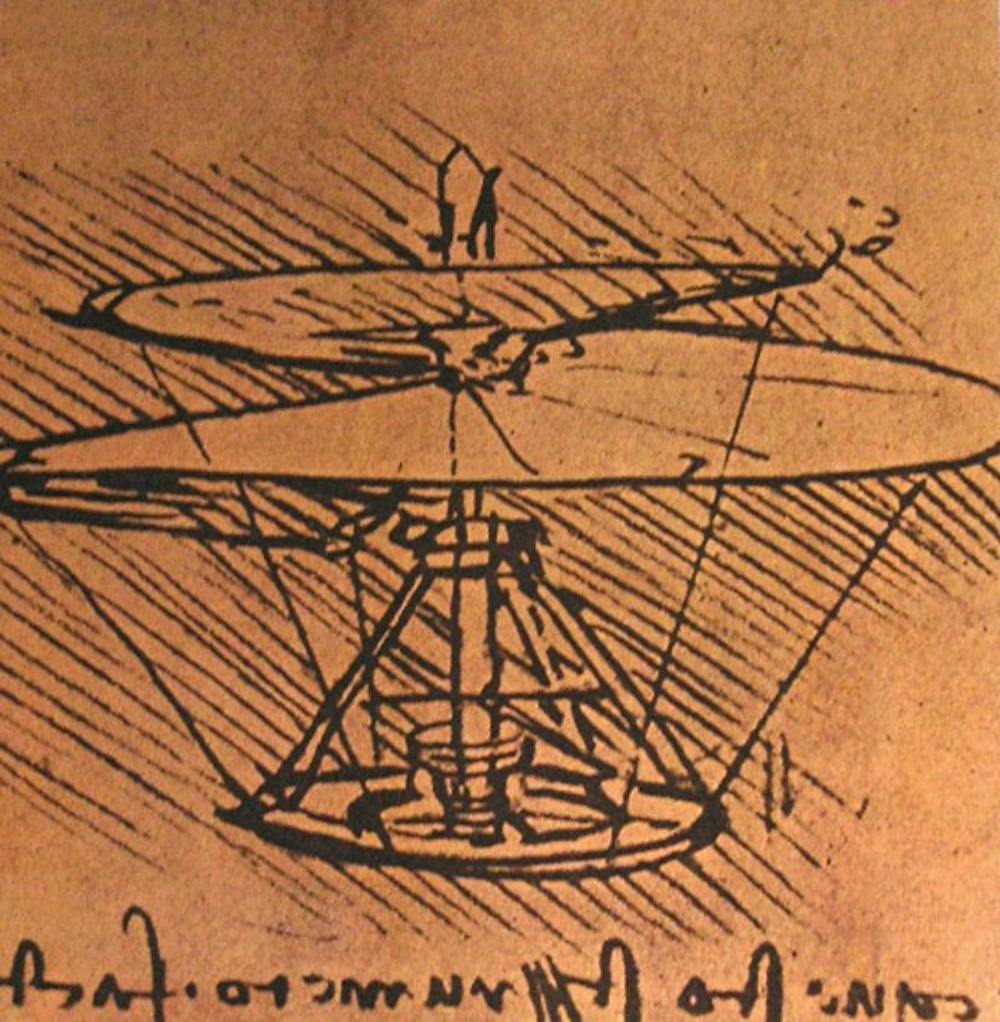
Fluid dynamics applies to both liquids and gasses. Humans have been using rotating rigid objects to move vehicles for hundreds of years – Leonardo Da Vinci incorporated the concept into his helicopter designs, and the first propeller–driven boats were built in the 1830s. Propellers are easy to make, and they work just fine at their designed cruise speed.
It has only been in the past couple of decades that advances in soft robotics have made actively controlled flexible components a reality. Now, marine roboticists are turning to flexible fish and their amazing swimming abilities for inspiration.
When engineers like me talk about flexibility in a swimming robot, we are usually referring to how stiff the tail of the fish is. The tail is the entire rear half of a fish’s body that moves back and forth when it swims.
Consider tuna, which can swim up to 50 mph and are extremely energy efficient over a wide range of speeds.
The tricky part about copying the biomechanics of fish is that biologists don’t know how flexible they are in the real world. If you want to know how flexible a rubber band is, you simply pull on it. If you pull on a fish’s tail, the stiffness depends on how much the fish is tensing its various muscles.
The best that researchers can do to estimate flexibility is film a swimming fish and measure how its body shape changes.
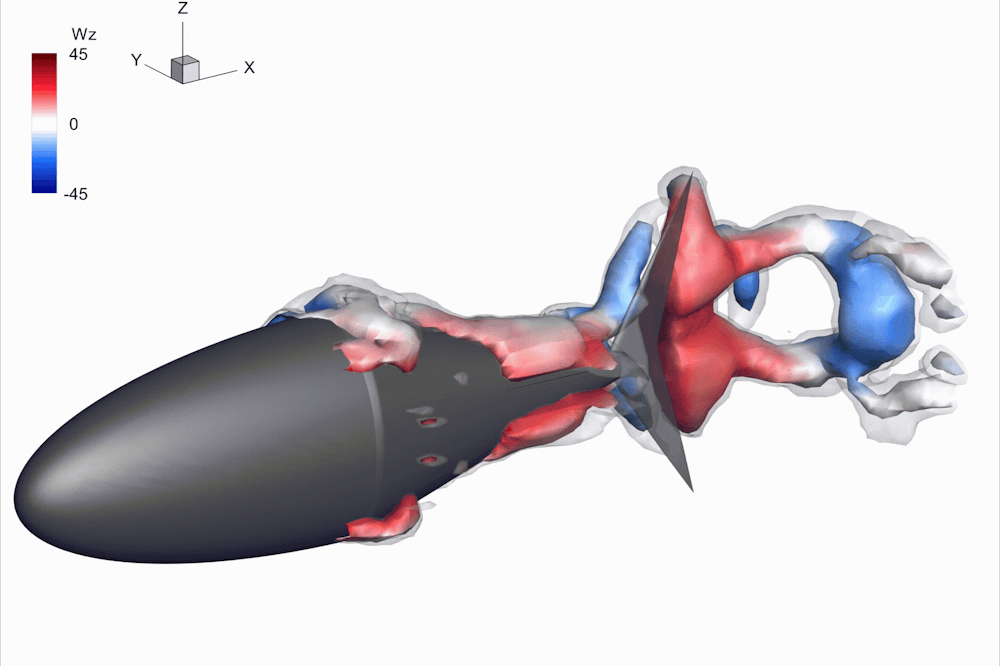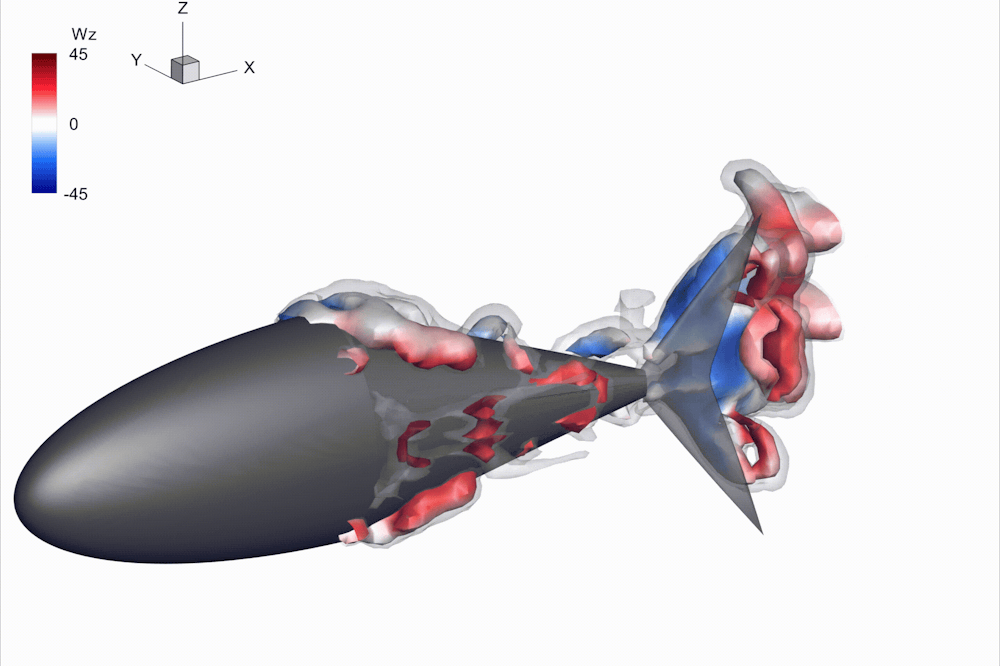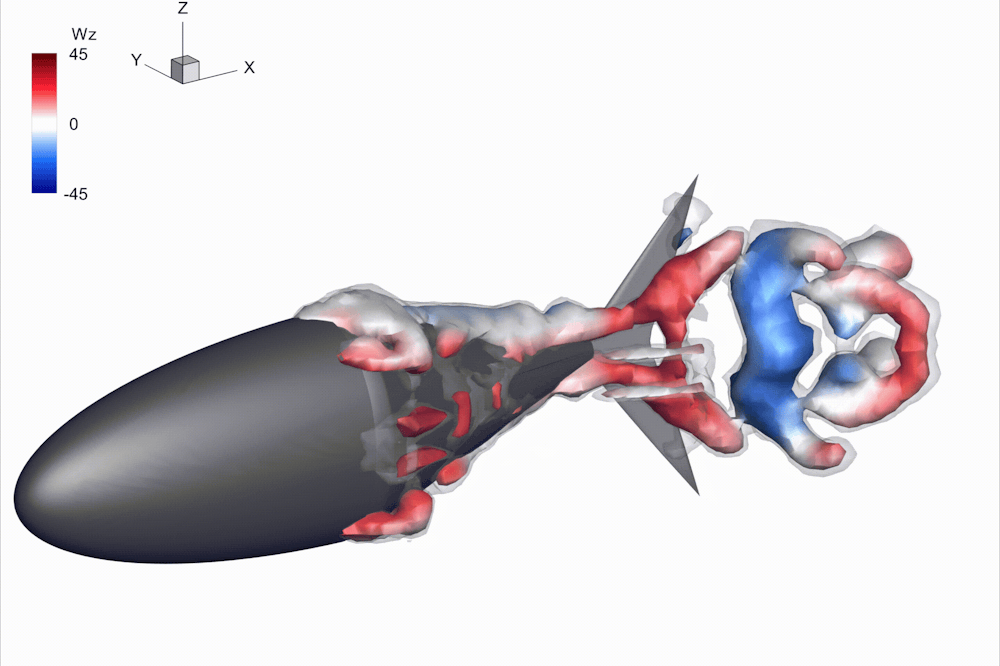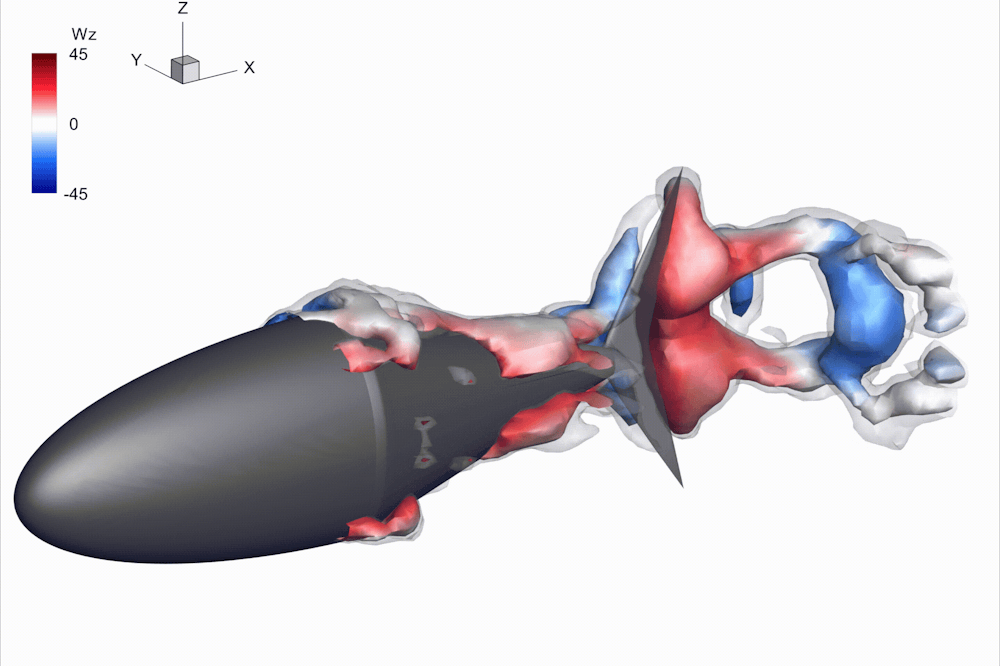
Researchers have built dozens of robots in an attempt to mimic the flexibility and swimming patterns of tuna and other fish, but none have matched the performance of the real things.
In my lab at the University of Virginia, my colleagues and I ran into the same questions as others: How flexible should our robot be? And if there’s no one best flexibility, how should our robot change its stiffness as it swims?
We looked for the answer in an old NASA paper about vibrating airplane wings. The report explains how when a plane’s wings vibrate, the vibrations change the amount of lift the wings produce. Since fish fins and airplane wings have similar shapes, the same math works well to model how much thrust fish tails produce as they flap back and forth.
Using the old wing theory, postdoctoral researcher Qiang Zhong and I created a mathematical model of a swimming fish and added a spring and pulley to the tail to represent the effects of a tensing muscle. We discovered a surprisingly simple hypothesis hiding in the equations. To maximize efficiency, muscle tension needs to increase as the square of swimming speed. So, if swimming speed doubles, stiffness needs to increase by a factor of four. To swim three times faster while maintaining high efficiency, a fish or fish-like robot needs to pull on its tendon about nine times harder.
To confirm our theory, we simply added an artificial tendon to one of our tunalike robots and then programmed the robot to vary its tail stiffness based on speed. We then put our new robot into our test tank and ran it through various “missions” – like a 200-meter sprint where it had to dodge simulated obstacles. With the ability to vary its tail’s flexibility, the robot used about half as much energy on average across a wide range of speeds compared to robots with a single stiffness.

While it is great to build one excellent robot, the thing my colleagues and I are most excited about is that our model is adaptable. We can tweak it based on body size, swimming style or even fluid type. It can be applied to animals and machines whether they are big or small, swimmers or flyers.
For example, our model suggests that dolphins have a lot to gain from the ability to vary their tails’ stiffness, whereas goldfish don’t get much benefit due to their body size, body shape and swimming style.
The model also has applications for robotic design too. Higher energy efficiency when swimming or flying – which also means quieter robots – would enable radically new missions for vehicles and robots that currently have only one efficient cruising speed. In the short term, this could help biologists study river beds and coral reefs more easily, enable researchers to track wind and ocean currents at unprecedented scales or allow search and rescue teams to operate farther and longer.
In the long term, I hope our research could inspire new designs for submarines and airplanes. Humans have only been working on swimming and flying machines for a couple centuries, while animals have been perfecting their skills for millions of years. There’s no doubt there is still a lot to learn from them.
![]()
Daniel Quinn receives funding from The National Science Foundation and The Office of Naval Research.
This article appeared in The Conversation.
{kind=link}