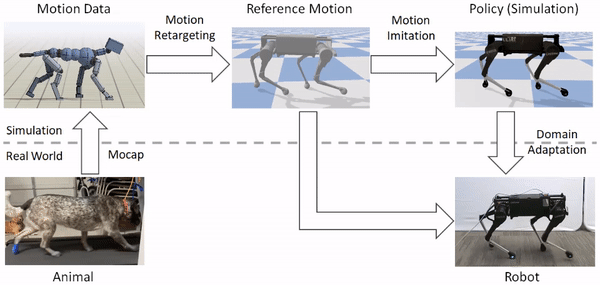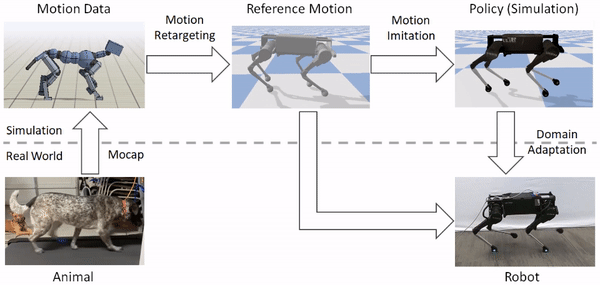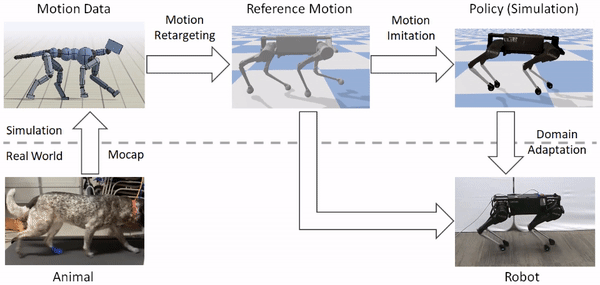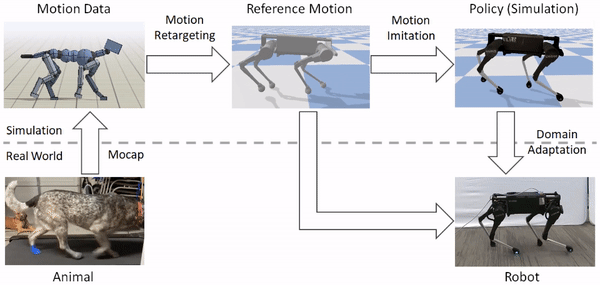
ActiNav synchronously handles vision processing, collision-free motion planning and autonomous real-time robot control, eliminating the complexity and risk usually associated with bin picking applications.
While machine learning offers many benefits to the company, try to move your employees around to other human-based areas of the business. Here are some ways that you can begin using machine learning in a warehouse environment.
The Aertos drones are able to fly stably indoors without external navigational aids such as GPS, VOP, LORAN, magnetic bearings, optical flow, or similar external navigational aids.
HRI2020 has already kicked off with workshops and the Industry Talks Session on April 3, however the first release of videos has only just gone online with the welcome from General Chairs Tony Belpaeme, ID Lab, University of Ghent and James Young, University of Manitoba.
https://youtu.be/Fkg3YvA5n5o
There is also a welcome from the Program Chairs Hatice Gunes from University of Cambridge and Laurel Riek from University of San Diego, requesting that we all engage with the participants papers and videos.
https://youtu.be/_74udxMmGJw
The theme of this year’s conference is “Real World Human-Robot Interaction,” reflecting on recent trends in our community toward creating and deploying systems that can facilitate real-world, long-term interaction. This theme also reflects a new theme area we have introduced at HRI this year, “Reproducibility for Human Robot Interaction,” which is key to realizing this vision and helping further our scientific endeavors. This trend was also reflected across our other four theme areas, including “Human-Robot Interaction User Studies,” “Technical Advances in Human-Robot Interaction,” “Human-Robot Interaction Design,” and “Theory and Methods in Human-Robot Interaction.”
The conference attracted 279 full paper submissions from around the world, including Asia, Australia, the Middle East, North America, South America, and Europe. Each submission was overseen by a dedicated theme chair and reviewed by an expert group of program committee members, who worked together with the program chairs to define and apply review criteria appropriate to each of the five contribution types. All papers were reviewed by a strict double-blind review process, followed by a rebuttal period, and shepherding if deemed appropriate by the program committee. Ultimately the committee selected 66 papers (23.6%) for presentation as full papers at the conference. As the conference is jointly sponsored by ACM and IEEE, papers are archived in the ACM Digital Library and the IEEE Xplore.
Along with the full papers, the conference program and proceedings include Late Breaking Reports, Videos, Demos, a Student Design Competition, and an alt.HRI section. Out of 183 total submissions, 161 (88%) Late Breaking Reports (LBRs) were accepted and will be presented as posters at the conference. A full peer-review and meta-review process ensured that authors of LBR submissions received detailed feedback on their work. Nine short videos were accepted for presentation during a dedicated video session. The program also includes 12 demos of robot systems that participants will have an opportunity to interact with during the conference. We continue to include an alt.HRI session in this year’s program, consisting of 8 papers (selected out of 43 submissions, 19%) that push the boundaries of thought and practice in the field. We are also continuing the Student Design Competition with 11 contenders, to encourage student participation in the conference and enrich the program with design inspiration and insights developed by student teams. The conference will include 6 full-day and 6 half-day workshops on a wide array of topics, in addition to the selective Pioneers Workshop for burgeoning HRI students.
Keynote speakers will reflect the interdisciplinary nature and vigour of our community. Ayanna Howard, the Linda J. and Mark C. Smith Professor and Chair of the School of Interactive Computing at the Georgia Institute of Technology, will talk about ‘Are We Trusting AI Too Much? Examining Human-Robot Interactions in the Real World’, Stephanie Dinkins, a transmedia artist who creates platforms for dialog about artificial intelligence (AI) as it intersects race, gender, aging, and our future histories, and Dr Lola Canamero, Reader in Adaptive Systems and Head of the Embodied Emotion, Cognition and (Inter-)Action Lab in the School of Computer Science at the University of Hertfordshire in the UK, will talk about ‘Embodied Affect for Real-World HRI’.
The Industry Talks Session was held on April 3 and we are particularly grateful to the sponsors who have remained with HRI2020 as we transition into virtual. Karl Fezer from ARM, Chris Roberts from Cambridge Consultants, Ker-Jiun Wang from EXGWear and Tony Belpaeme from IDLab at University of Ghent were able to join me for the first Industry Talks Session at HRI 2020 – a very insightful discussion!
The array of gripper choices in the automotive, pharmaceutical and electronics and industries for pick-and-place automation systems are numerous. The many gripper styles – all of which have their own size, method of operation, and level of human interaction – is daunting.
The array of gripper choices in the automotive, pharmaceutical and electronics and industries for pick-and-place automation systems are numerous. The many gripper styles – all of which have their own size, method of operation, and level of human interaction – is daunting.
The YouTube originals series “The Age of A.I.” was released in December 2019. If you haven’t already seen it now could be a good time to catch up – with much of the world in enforced or voluntary isolation many of us will be stuck at home with hours to fill. Sit back and marvel at the many incredible, and often heart-warming, applications of AI.
Episode 1 features researchers Mark Sagar, University of Auckland and Gil Weinberg, Georgia Tech. Mark works with will.i.am on a digital avatar and presents BabyX – a virtual animated baby that learns and reacts like a human baby. Gil makes music using AI and has teamed up other researchers at Georgia Tech to create smart prosthetics for amputees, combining ultrasound signals and machine learning.
The 15th Annual ACM/IEEE International Conference on Human Robot Interaction – HRI 2020 – was meant to take place in the city of Cambridge UK. Instead it will be launching online today. You can follow latest happenings on twitter and youtube. Check here for a list of all the papers.
The theme of this year’s conference is “Real World Human-Robot Interaction,” reflecting on recent trends in the HRI community toward creating and deploying systems that can facilitate real-world, long-term interaction between robots and users.
Check back here, and the official HRI website, for new links and videos.
Whether it’s a dog chasing after a ball, or a monkey swinging through the trees, animals can effortlessly perform an incredibly rich repertoire of agile locomotion skills. But designing controllers that enable legged robots to replicate these agile behaviors can be a very challenging task. The superior agility seen in animals, as compared to robots, might lead one to wonder: can we create more agile robotic controllers with less effort by directly imitating animals?
In this work, we present a framework for learning robotic locomotion skills by imitating animals. Given a reference motion clip recorded from an animal (e.g. a dog), our framework uses reinforcement learning to train a control policy that enables a robot to imitate the motion in the real world. Then, by simply providing the system with different reference motions, we are able to train a quadruped robot to perform a diverse set of agile behaviors, ranging from fast walking gaits to dynamic hops and turns. The policies are trained primarily in simulation, and then transferred to the real world using a latent space adaptation technique, which is able to efficiently adapt a policy using only a few minutes of data from the real robot.
Framework
Our framework consists of three main components: motion retargeting, motion imitation, and domain adaptation. 1) First, given a reference motion, the motion retargeting stage maps the motion from the original animal’s morphology to the robot’s morphology. 2) Next, the motion imitation stage uses the retargeted reference motion to train a policy for imitating the motion in simulation. 3) Finally, the domain adaptation stage transfers the policy from simulation to a real robot via a sample efficient domain adaptation process. We apply this framework to learn a variety of agile locomotion skills for a Laikago quadruped robot.
The framework consists of three stages: motion retargeting, motion imitation, and domain adaptation. It receives as input motion data recorded from an animal, and outputs a control policy that enables a robot to reproduce the motion in the real world.
Motion Retargeting
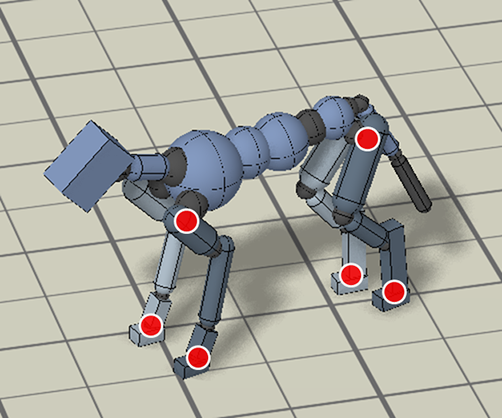
An animal’s body is generally quite different from a robot’s body. So before the robot can imitate the animal’s motion, we must first map the motion to the robot’s body. The goal of the retargeting process is to construct a reference motion for the robot that captures the important characteristics of the animal’s motion. To do this, we first identify a set of source keypoints on the animal’s body, such as the hips and the feet. Then, corresponding target keypoints are specified on the robot’s body.
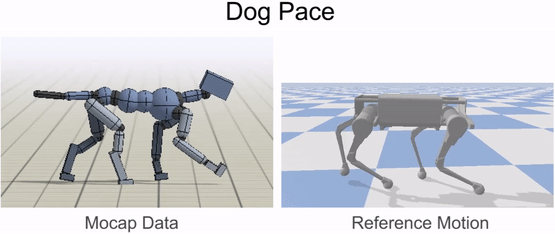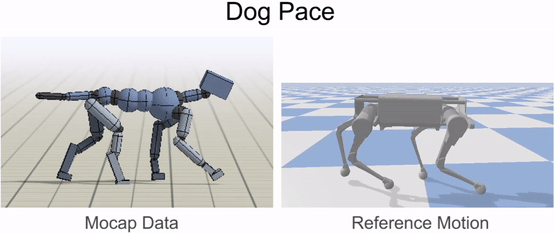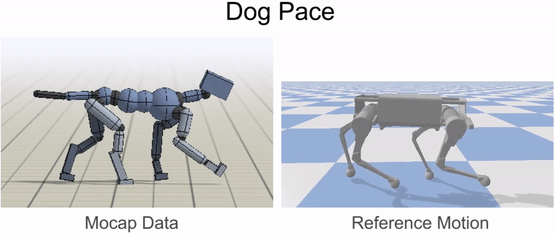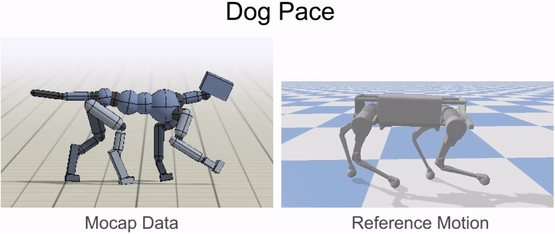
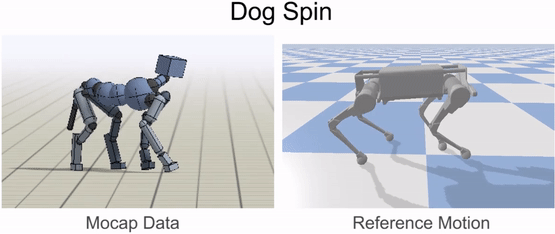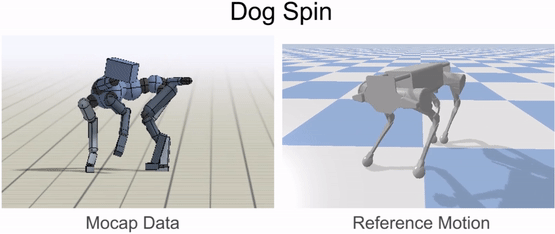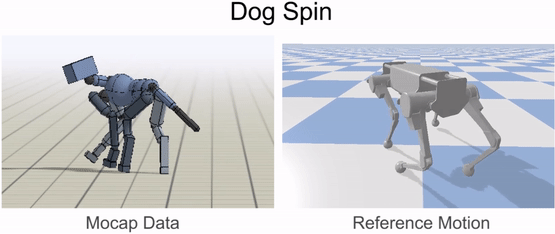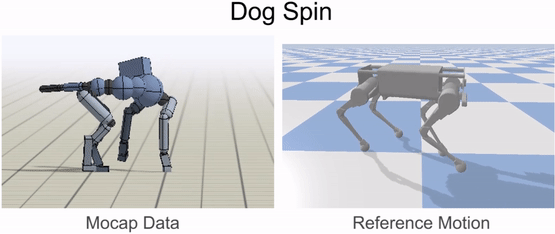
Inverse-kinematics (IK) is used to retarget mocap clips recorded from a real dog (left) to the robot (right). Corresponding pairs of keypoints (red) are specified on the dog and robot’s bodies, and then IK is used to compute a pose for the robot that tracks the keypoints.
Next, inverse-kinematics is used to construct a reference motion for the robot that tracks the corresponding keypoints from the animal at every timestep.
Inverse-kinematics is used to retarget mocap clips recorded from a dog to the robot.
Motion Imitation
After retargeting the reference motion to the robot, the next step is to train a control policy to imitate the retargeted motion. But reinforcement learning algorithms can take a long time to learn an effective policy, and directly training on a real robot can be fairly dangerous (both for the robot and its human companions). So, we instead opt to perform most of the training in the comforts of simulation, and then transfer the learned policy to the real world using more sample efficient adaptation techniques. All simulations are performed using PyBullet.
The policy $\pi(\mathbf{a} | \mathbf{s}, \mathbf{g})$, takes as input a state $\mathbf{s}$, which represents the configuration of the robot’s body, and a goal $\mathbf{g}$, which specifies target poses from the reference motion that the robot is to imitate. It then outputs an action $\mathbf{a}$, which specifies target angles for PD controllers at each of the robot’s joints. To train the policy to imitate a reference motion, we use a reward function that encourages the robot to minimize the difference between the pose of the reference motion $\hat{\mathbf{q}}_t$ and the pose of the simulated character $\mathbf{q}_t$ at every timestep $t$,
By simply using different reference motions in the reward function, we can train a simulated robot to imitate a variety of different skills.
Reinforcement learning is used to train a simulated robot to imitate the retargeted reference motions.
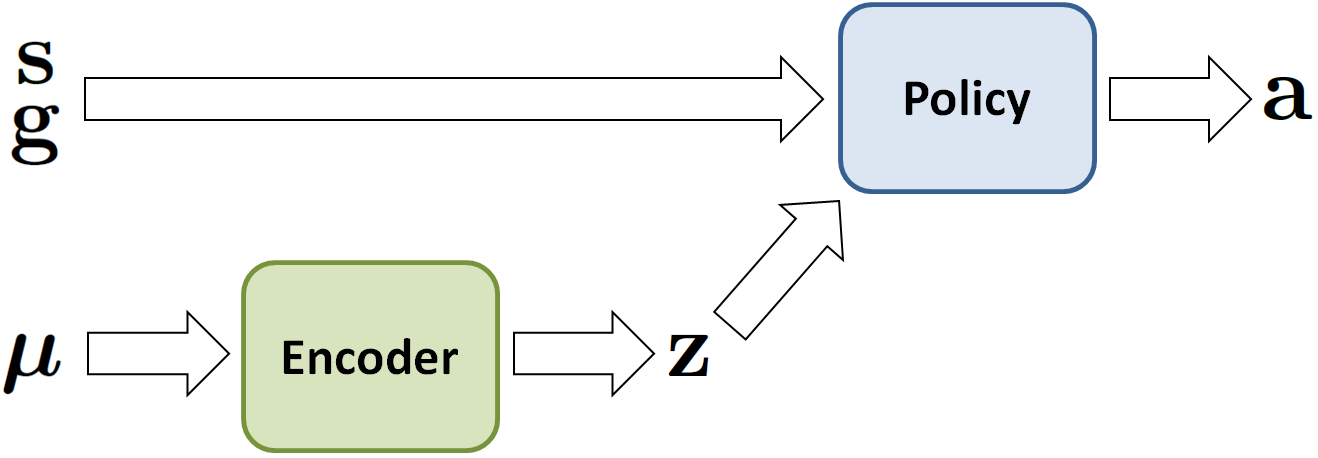
Domain Adaptation
Since simulators generally provide only a coarse approximation of the real world, policies trained in simulation often perform fairly poorly when deployed on a real robot. Therefore, to transfer a policy trained in simulation to the real world, we use a sample efficient domain adaptation techniques that can adapt the policy to the real world using only a small number of trials on the real robot. To do this, we first apply domain randomization during training in simulation, which randomly varies the dynamics parameters, such as mass and friction. The dynamics parameters are then also collected into a vector $\mu$ and encoded into a latent presentation $\mathbf{z}$ by an encoder $E(\mathbf{z} | \mu)$. The latent encoding is passed as an additional input to the policy $\pi(\mathbf{a} | \mathbf{s}, \mathbf{g}, \mathbf{z})$.
The dynamics parameters of the simulation are varied during training, and also encoded into a latent representation that is provided as an additional input to the policy.
When transferring the policy to a real robot, we remove the encoder and directly search for a $\mathbf{z}$ that maximizes the robot’s rewards in the real world. This is done using advantage weighted regression, a simple off-policy reinforcement learning algorithm. In our experiments, this technique is often able to adapt a policy to the real world with less than 50 trials, which corresponds to roughly 8 minutes of real-world data.
Comparison of policies before and after adaptation on the real robot. Before adaptation, the robot is prone to falling. But after adaptation, the policies are able to more consistently execute the desired skills.
Results
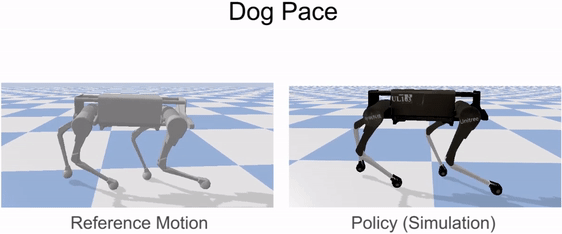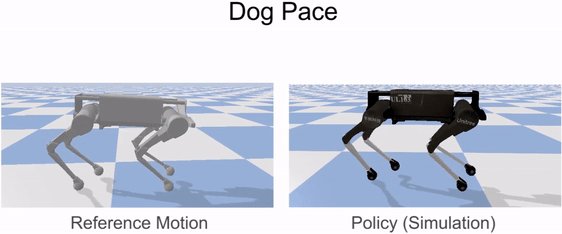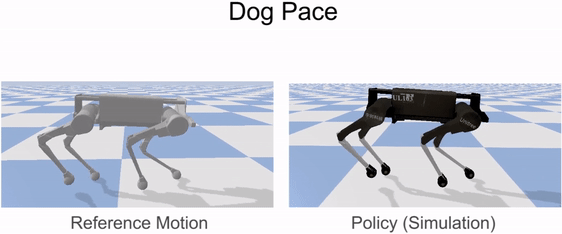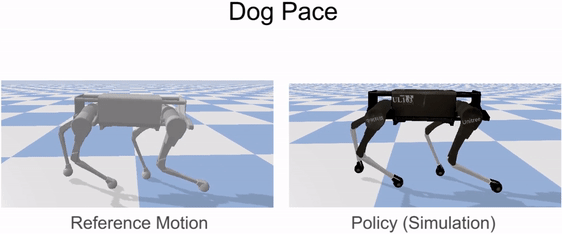
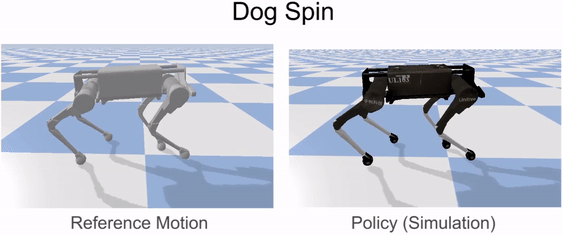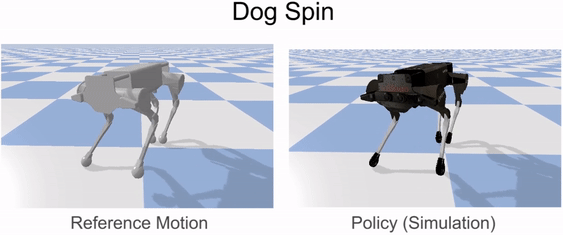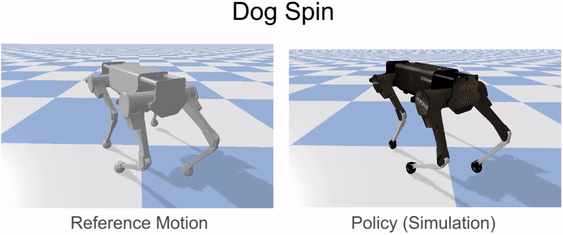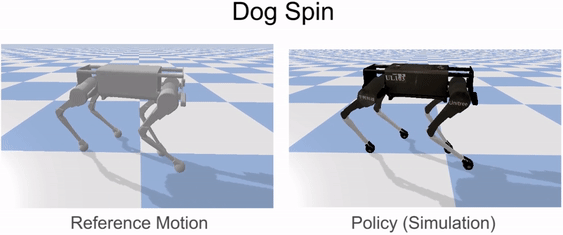
Our framework is able to train a robot to imitate various locomotion skills from a dog, including different walking gaits, such as pacing and trotting, as well as a fast spinning motion. By simply playing the forwards walking motions backwards, we are also able to train the robot to walk backwards.
Laikago imitating various skills from a dog.
In addition to imitating motions from real dogs, we can also imitate artist-animated keyframe motion, including a dynamic hop-turn:
Hop Turn Skills learned by imitating artist-animated keyframe motions.
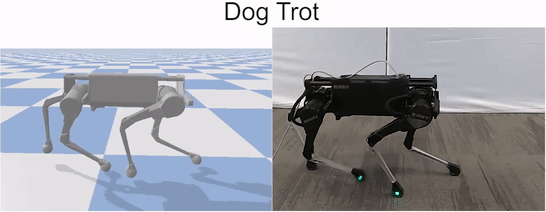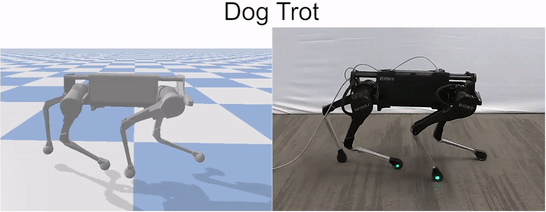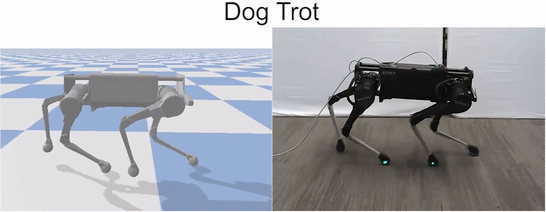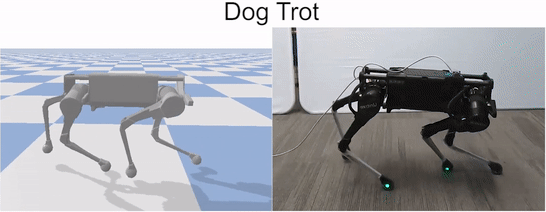
We also compared the learned policies with the manually-designed controllers provided by the manufacturer. Our policies are able to learn faster gaits.
Comparison of learned trotting gait with the built-in gait provided by the manufacturer.
Overall, our system has been able to reproduce a fairly diverse corpus of behaviors with a quadruped robot. However, due to hardware and algorithmic limitations, we have not been able to imitate more dynamic motions such as running and jumping. The learned policies are also not as robust as the best manually-designed controllers. Exploring techniques for further improving the agility and robustness of these learned policies could be a valuable step towards more complex real-world applications. Extending this framework to learn skills from videos would also be an exciting direction, which can substantially increase the volume of data from which robots can learn from.
We would like to thank Erwin Coumans, Tingnan Zhang, Tsang-Wei Lee, Jie Tan, Sergey Levine, Byron David, Thinh Nguyen, Gus Kouretas, Krista Reymann, and Bonny Ho for all their support and contribution to this work. This project was done in collaboration with Google Brain. This article was initially published on the BAIR blog, and appears here with the authors’ permission.
FIRST teams around the world to compete virtually in its design competition, Robots to the Rescue, in which teams will be challenged to design a robot that can solve a current real-world problem.
Deep learning opens up new fields of application for industrial image processing, which previously could only be solved with great effort or not at all. The new, fundamentally different approach to classical image processing causes new challenges for users.
The basic MRI foundations are presented for tensor representation, as well as the basic components to apply a deep learning method that handles the task-specific problems(class imbalance, limited data). Moreover, we present some features of the open source medical image segmentation library. Finally, we discuss our preliminary experimental results and provide sources to find medical imaging data.
Although some of the work in factories is automated, human input is still crucial and remains at the heart of many operations, including value-added and repetitive ones, but which require a high level of precision.