Warehouses may be the first industry to adopt humanoid robot workers
With the news that Amazon is testing a humanoid robot – Agility Robotics’ Digit – in its warehouses, we explore what the future looks like for bipedal robots in logistics.

Source: OpenAI’s DALL·E 2 with prompt “a hyperrealistic picture of a robot reading the news on a laptop at a coffee shop”
Welcome to the 6th edition of Robo-Insight, a robotics news update! In this post, we are excited to share a range of new advancements in the field and highlight robots’ progress in areas like medical assistance, prosthetics, robot flexibility, joint movement, work performance, AI design, and household cleanliness.
In the medical world, researchers from Germany have developed a robotic system designed to help nurses relieve the physical strain associated with patient care. Nurses often face high physical demands when attending to bedridden patients, especially during tasks like repositioning them. Their work explores how robotic technology can assist in such tasks by remotely anchoring patients in a lateral position. The results indicate that the system improved the working posture of nurses by an average of 11.93% and was rated as user-friendly. The research highlights the potential for robotics to support caregivers in healthcare settings, improving both nurse working conditions and patient care.
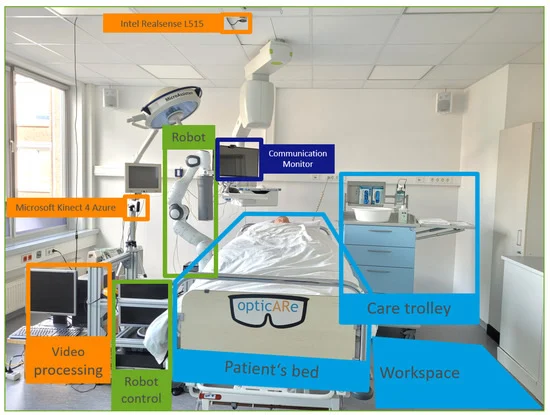
Arrangement of patient room used in the study. Source.
Keeping our focus healthcare-related, recently researchers from numerous European institutions have achieved a significant breakthrough in robot prosthetic technology, as they successfully implanted a neuromusculoskeletal prosthesis, a bionic hand connected directly to the user’s nervous and skeletal systems, in a person with a below-elbow amputation. This achievement involved surgical procedures to place titanium implants in the radius and ulna bones and transfer severed nerves to free muscle grafts. These neural interfaces provided a direct connection between the prosthesis and the user’s body, allowing for improved prosthetic function and increased quality of life. Their work demonstrates the potential for highly integrated prosthetic devices to enhance the lives of amputees through reliable neural control and comfortable, everyday use.
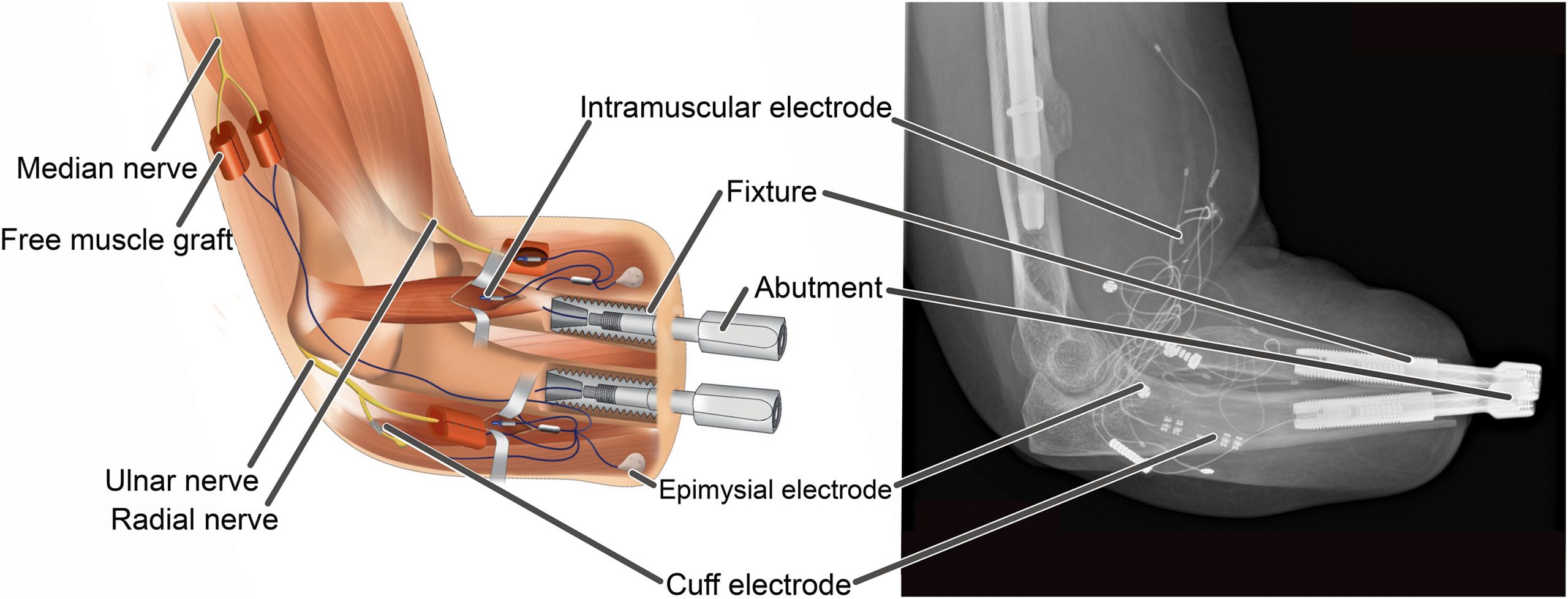
Schematic and X-ray of a fully integrated human-machine interface in a patient. Source.
Turning our focus to soft robotics, researchers from the Center for Research and Advanced Studies of the National Polytechnic Institut of Mexico and the Universidad Autónoma de Coahuila have proposed an approach to use reinforcement learning (RL) for motor control of a pneumatic-driven soft robot modeled after continuum media with varying density. This method involves a continuous-time Actor-Critic scheme designed for tracking tasks in a 3D soft robot subject to Lipschitz disturbances. Their study introduces a reward-based temporal difference mechanism and a discontinuous adaptive approach for neural weights in the Critic component of the system. The overall aim is to enable RL to control the complex, uncertain, and deformable nature of soft robots while ensuring stability in real-time control, a crucial requirement for physical systems. This research focuses on the application of RL in managing the unique challenges posed by soft robots.
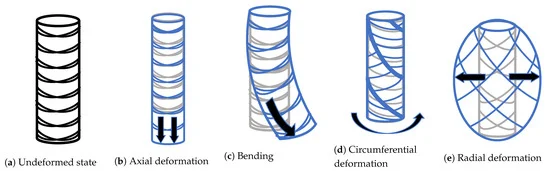
Distinct distortions of a cylindrical-shaped flexible robot. Source.
Moving onto human-robot interactions, researchers from the University of Texas at Austin’s Human-Centered Robotics Laboratory have introduced a teen-sized humanoid robot named DRACO 3, designed in collaboration with Apptronik. This robot, tailored for practical use in human environments, features proximal actuation and employs rolling contact mechanisms on its lower body, allowing for extensive vertical poses. A whole-body controller (WBC) has been developed to manage DRACO 3’s complex transmissions. This research offers insights into the development and control of humanoids with rolling contact joints, focusing on practicality and performance.
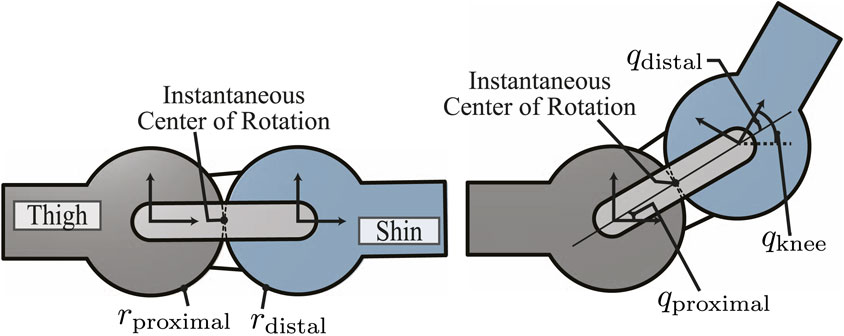
Diagram illustrating the rolling contact joint at the knee. Initial configuration (left) and post-angular displacement (right). Source.
Shifting our focus to psychology, recently researchers from Technische Universität Berlin have investigated the phenomenon of social loafing in human-robot teams. Social loafing refers to reduced individual effort in a team setting compared to working alone. The study involved participants inspecting circuit boards for defects, with one group working alone and the other with a robot partner. Despite a reliable robot that marked defects on boards, participants working with the robot identified fewer defects compared to those working alone, suggesting a potential occurrence of social loafing in human-robot teams. This research sheds light on the challenges associated with human-robot collaboration and its impact on individual effort and performance.
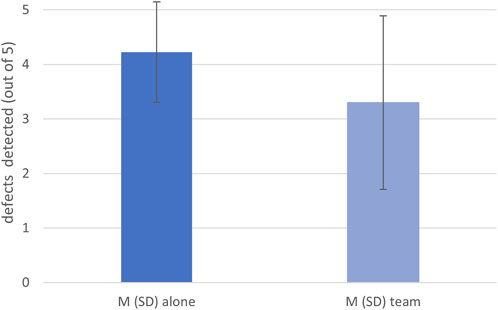
Results of solo work vs. robot work. Source.
Changing our focus to robot design, researchers from Northwestern University have developed an AI system that designs robots from scratch, enabling it to create a walking robot in seconds, a task that took nature billions of years to evolve. This AI system runs on a lightweight personal computer, without relying on energy-hungry supercomputers or large datasets, offering the potential to design robots with unique forms rapidly. The system works by iterating on a design, assessing its flaws, and refining the structure in a matter of seconds. It paves the way for a new era of AI-designed tools capable of acting directly on the world for various applications.

3D printer designing robot. Source.
Finally, in the field of home robotics, researchers from Stanford, Princeton, Columbia University, and Google, have developed TidyBot, a one-armed robot designed to clean spaces according to personal preferences. TidyBot uses a large language model trained on internet data to identify various objects and understand where to put them, making it highly customizable to different preferences. In real-world tests, the robot can correctly put away approximately 85% of objects, significantly improving household organization. While TidyBot still has room for improvement, researchers believe it holds great promise for making robots more versatile and useful in homes and other environments.

Tidybot in training. Source.
The ongoing development in a multitude of sectors highlights the flexibility and steadily advancing character of robotics technology, uncovering fresh possibilities for its incorporation into a wide range of industries. The progressive expansion in the realm of robotics mirrors unwavering commitment and offers a glimpse into the potential consequences of these advancements for the times ahead.
Sources:
By Andre He, Vivek Myers
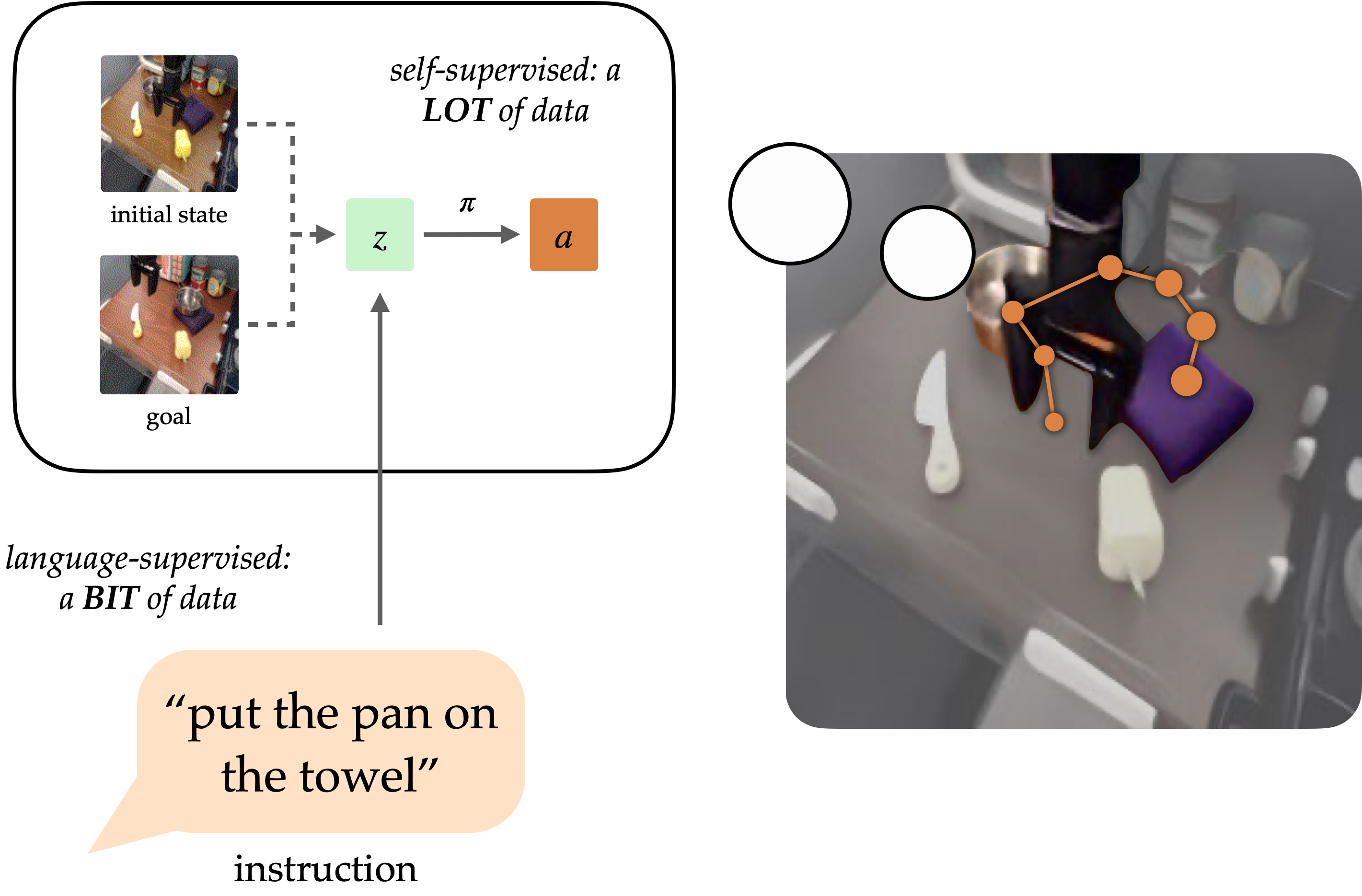
A longstanding goal of the field of robot learning has been to create generalist agents that can perform tasks for humans. Natural language has the potential to be an easy-to-use interface for humans to specify arbitrary tasks, but it is difficult to train robots to follow language instructions. Approaches like language-conditioned behavioral cloning (LCBC) train policies to directly imitate expert actions conditioned on language, but require humans to annotate all training trajectories and generalize poorly across scenes and behaviors. Meanwhile, recent goal-conditioned approaches perform much better at general manipulation tasks, but do not enable easy task specification for human operators. How can we reconcile the ease of specifying tasks through LCBC-like approaches with the performance improvements of goal-conditioned learning?
Conceptually, an instruction-following robot requires two capabilities. It needs to ground the language instruction in the physical environment, and then be able to carry out a sequence of actions to complete the intended task. These capabilities do not need to be learned end-to-end from human-annotated trajectories alone, but can instead be learned separately from the appropriate data sources. Vision-language data from non-robot sources can help learn language grounding with generalization to diverse instructions and visual scenes. Meanwhile, unlabeled robot trajectories can be used to train a robot to reach specific goal states, even when they are not associated with language instructions.
Conditioning on visual goals (i.e. goal images) provides complementary benefits for policy learning. As a form of task specification, goals are desirable for scaling because they can be freely generated hindsight relabeling (any state reached along a trajectory can be a goal). This allows policies to be trained via goal-conditioned behavioral cloning (GCBC) on large amounts of unannotated and unstructured trajectory data, including data collected autonomously by the robot itself. Goals are also easier to ground since, as images, they can be directly compared pixel-by-pixel with other states.
However, goals are less intuitive for human users than natural language. In most cases, it is easier for a user to describe the task they want performed than it is to provide a goal image, which would likely require performing the task anyways to generate the image. By exposing a language interface for goal-conditioned policies, we can combine the strengths of both goal- and language- task specification to enable generalist robots that can be easily commanded. Our method, discussed below, exposes such an interface to generalize to diverse instructions and scenes using vision-language data, and improve its physical skills by digesting large unstructured robot datasets.
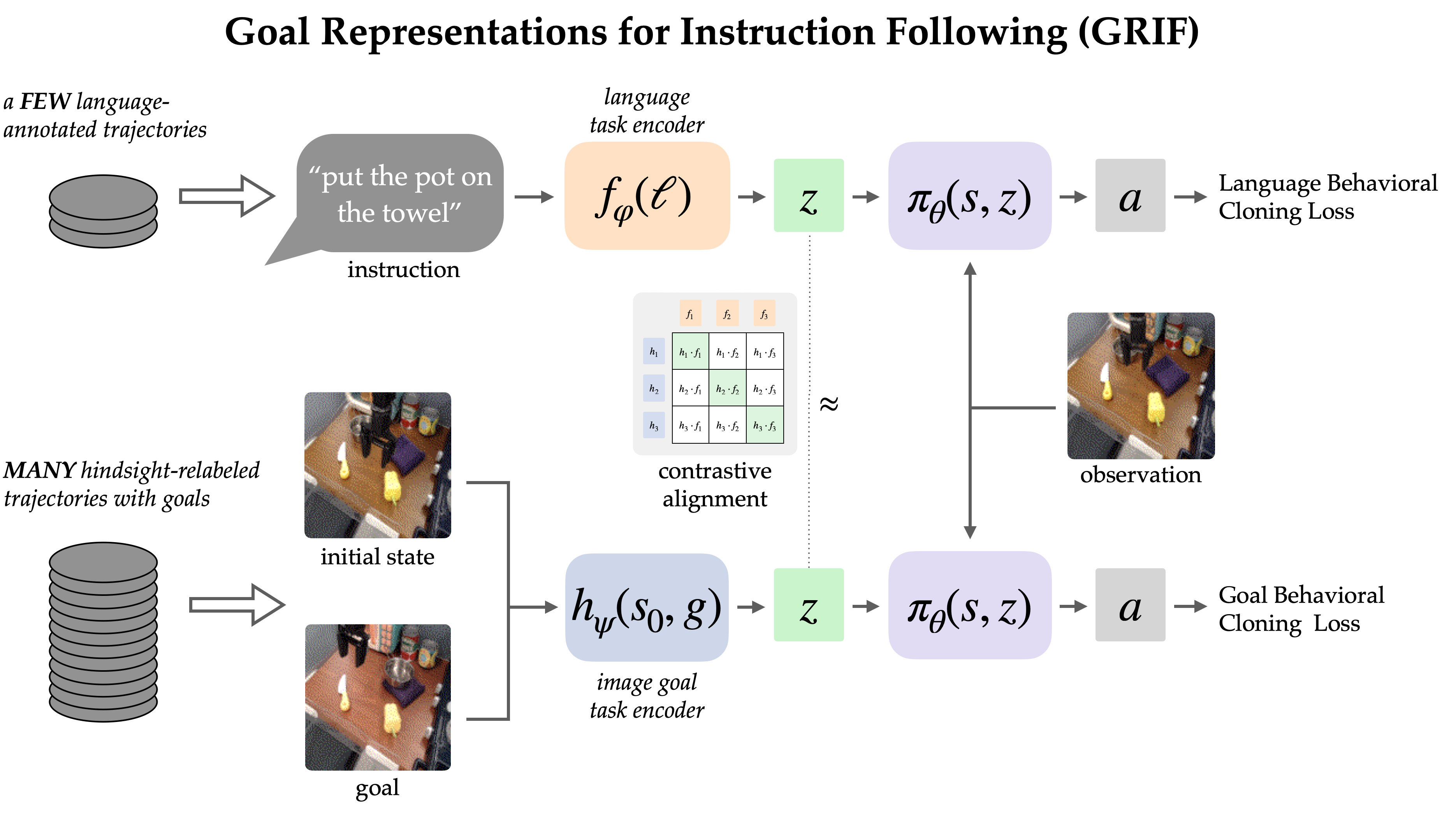
The GRIF model consists of a language encoder, a goal encoder, and a policy network. The encoders respectively map language instructions and goal images into a shared task representation space, which conditions the policy network when predicting actions. The model can effectively be conditioned on either language instructions or goal images to predict actions, but we are primarily using goal-conditioned training as a way to improve the language-conditioned use case.
Our approach, Goal Representations for Instruction Following (GRIF), jointly trains a language- and a goal- conditioned policy with aligned task representations. Our key insight is that these representations, aligned across language and goal modalities, enable us to effectively combine the benefits of goal-conditioned learning with a language-conditioned policy. The learned policies are then able to generalize across language and scenes after training on mostly unlabeled demonstration data.
We trained GRIF on a version of the Bridge-v2 dataset containing 7k labeled demonstration trajectories and 47k unlabeled ones within a kitchen manipulation setting. Since all the trajectories in this dataset had to be manually annotated by humans, being able to directly use the 47k trajectories without annotation significantly improves efficiency.
To learn from both types of data, GRIF is trained jointly with language-conditioned behavioral cloning (LCBC) and goal-conditioned behavioral cloning (GCBC). The labeled dataset contains both language and goal task specifications, so we use it to supervise both the language- and goal-conditioned predictions (i.e. LCBC and GCBC). The unlabeled dataset contains only goals and is used for GCBC. The difference between LCBC and GCBC is just a matter of selecting the task representation from the corresponding encoder, which is passed into a shared policy network to predict actions.
By sharing the policy network, we can expect some improvement from using the unlabeled dataset for goal-conditioned training. However,GRIF enables much stronger transfer between the two modalities by recognizing that some language instructions and goal images specify the same behavior. In particular, we exploit this structure by requiring that language- and goal- representations be similar for the same semantic task. Assuming this structure holds, unlabeled data can also benefit the language-conditioned policy since the goal representation approximates that of the missing instruction.
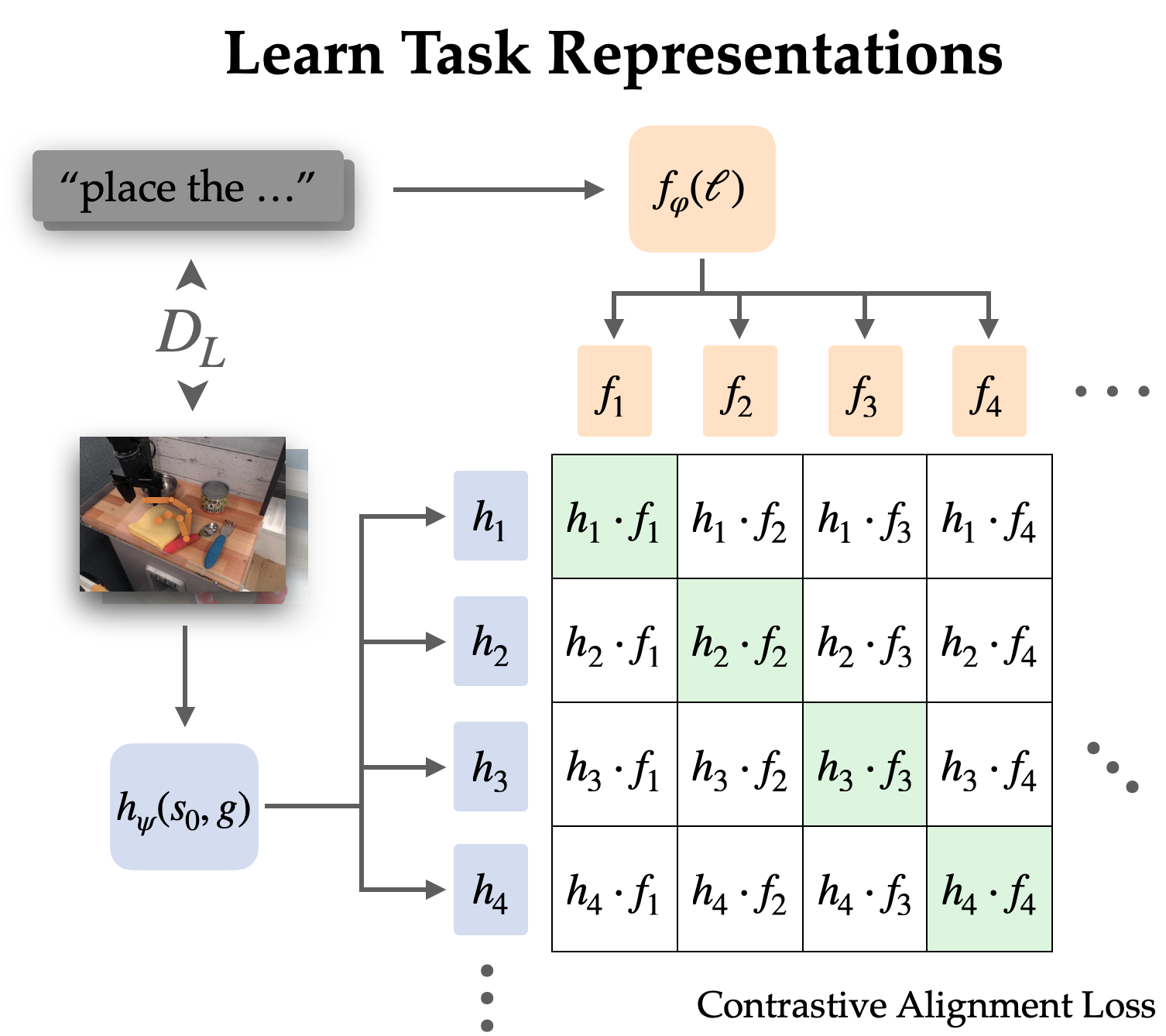
We explicitly align representations between goal-conditioned and language-conditioned tasks on the labeled dataset through contrastive learning.
Since language often describes relative change, we choose to align representations of state-goal pairs with the language instruction (as opposed to just goal with language). Empirically, this also makes the representations easier to learn since they can omit most information in the images and focus on the change from state to goal.
We learn this alignment structure through an infoNCE objective on instructions and images from the labeled dataset. We train dual image and text encoders by doing contrastive learning on matching pairs of language and goal representations. The objective encourages high similarity between representations of the same task and low similarity for others, where the negative examples are sampled from other trajectories.
When using naive negative sampling (uniform from the rest of the dataset), the learned representations often ignored the actual task and simply aligned instructions and goals that referred to the same scenes. To use the policy in the real world, it is not very useful to associate language with a scene; rather we need it to disambiguate between different tasks in the same scene. Thus, we use a hard negative sampling strategy, where up to half the negatives are sampled from different trajectories in the same scene.
Naturally, this contrastive learning setup teases at pre-trained vision-language models like CLIP. They demonstrate effective zero-shot and few-shot generalization capability for vision-language tasks, and offer a way to incorporate knowledge from internet-scale pre-training. However, most vision-language models are designed for aligning a single static image with its caption without the ability to understand changes in the environment, and they perform poorly when having to pay attention to a single object in cluttered scenes.
To address these issues, we devise a mechanism to accommodate and fine-tune CLIP for aligning task representations. We modify the CLIP architecture so that it can operate on a pair of images combined with early fusion (stacked channel-wise). This turns out to be a capable initialization for encoding pairs of state and goal images, and one which is particularly good at preserving the pre-training benefits from CLIP.
For our main result, we evaluate the GRIF policy in the real world on 15 tasks across 3 scenes. The instructions are chosen to be a mix of ones that are well-represented in the training data and novel ones that require some degree of compositional generalization. One of the scenes also features an unseen combination of objects.
We compare GRIF against plain LCBC and stronger baselines inspired by prior work like LangLfP and BC-Z. LLfP corresponds to jointly training with LCBC and GCBC. BC-Z is an adaptation of the namesake method to our setting, where we train on LCBC, GCBC, and a simple alignment term. It optimizes the cosine distance loss between the task representations and does not use image-language pre-training.
The policies were susceptible to two main failure modes. They can fail to understand the language instruction, which results in them attempting another task or performing no useful actions at all. When language grounding is not robust, policies might even start an unintended task after having done the right task, since the original instruction is out of context.
Examples of grounding failures

“put the mushroom in the metal pot”

“put the spoon on the towel”

“put the yellow bell pepper on the cloth”

“put the yellow bell pepper on the cloth”
The other failure mode is failing to manipulate objects. This can be due to missing a grasp, moving imprecisely, or releasing objects at the incorrect time. We note that these are not inherent shortcomings of the robot setup, as a GCBC policy trained on the entire dataset can consistently succeed in manipulation. Rather, this failure mode generally indicates an ineffectiveness in leveraging goal-conditioned data.
Examples of manipulation failures

“move the bell pepper to the left of the table”

“put the bell pepper in the pan”

“move the towel next to the microwave”
Comparing the baselines, they each suffered from these two failure modes to different extents. LCBC relies solely on the small labeled trajectory dataset, and its poor manipulation capability prevents it from completing any tasks. LLfP jointly trains the policy on labeled and unlabeled data and shows significantly improved manipulation capability from LCBC. It achieves reasonable success rates for common instructions, but fails to ground more complex instructions. BC-Z’s alignment strategy also improves manipulation capability, likely because alignment improves the transfer between modalities. However, without external vision-language data sources, it still struggles to generalize to new instructions.
GRIF shows the best generalization while also having strong manipulation capabilities. It is able to ground the language instructions and carry out the task even when many distinct tasks are possible in the scene. We show some rollouts and the corresponding instructions below.
Policy Rollouts from GRIF

“move the pan to the front”

“put the bell pepper in the pan”

“put the knife on the purple cloth”

“put the spoon on the towel”
GRIF enables a robot to utilize large amounts of unlabeled trajectory data to learn goal-conditioned policies, while providing a “language interface” to these policies via aligned language-goal task representations. In contrast to prior language-image alignment methods, our representations align changes in state to language, which we show leads to significant improvements over standard CLIP-style image-language alignment objectives. Our experiments demonstrate that our approach can effectively leverage unlabeled robotic trajectories, with large improvements in performance over baselines and methods that only use the language-annotated data
Our method has a number of limitations that could be addressed in future work. GRIF is not well-suited for tasks where instructions say more about how to do the task than what to do (e.g., “pour the water slowly”)—such qualitative instructions might require other types of alignment losses that consider the intermediate steps of task execution. GRIF also assumes that all language grounding comes from the portion of our dataset that is fully annotated or a pre-trained VLM. An exciting direction for future work would be to extend our alignment loss to utilize human video data to learn rich semantics from Internet-scale data. Such an approach could then use this data to improve grounding on language outside the robot dataset and enable broadly generalizable robot policies that can follow user instructions.
This post is based on the following paper:
 Claire chatted to Lorenzo Jamone from Queen Mary University of London all about robotic hands, dexterity, and the sense of touch.
Claire chatted to Lorenzo Jamone from Queen Mary University of London all about robotic hands, dexterity, and the sense of touch.
Lorenzo Jamone is a Senior Lecturer in Robotics at Queen Mary University of London, where he is the founder and director of the CRISP group: Cognitive Robotics and Intelligent Systems for the People. He received a PhD degree in humanoid technologies at the Italian Institute of Technology. He was previously an Associate Researcher at Waseda University in Japan, and at the Instituto Superior Técnico in Portugal. His current research interests include cognitive robotics, robotic manipulation, force and tactile sensing, robot learning.