Nature, the master engineer, is coming to our rescue again. Inspired by scorpions, scientists have created new pressure sensors that are both highly sensitive and able to work across a wide variety of pressures.
Astronomers using AI have captured a once-in-a-lifetime cosmic event: a massive star’s violent death triggered by its black hole companion. The explosion, known as SN 2023zkd, not only produced a brilliant supernova but also shocked scientists by glowing twice, after years of strange pre-death brightening. Observed by telescopes worldwide, the event provided the strongest evidence yet that black holes can ignite stellar explosions.
A research team has created a quantum logic gate that uses fewer qubits by encoding them with the powerful GKP error-correction code. By entangling quantum vibrations inside a single atom, they achieved a milestone that could transform how quantum computers scale.
A collaborative team of researchers from the University of California, Berkeley, the Georgia Institute of Technology, and Ajou University in South Korea has revealed that the unique fan-like propellers of Rhagovelia water striders—which allow them to glide across fast-moving streams—open and close passively, like a paintbrush, ten times faster than the blink of an eye.
A new type of drone, inspired by the aerial precision of birds of prey, could one day navigate through dense city skyscrapers to deliver our packages or inspect hard-to-reach offshore wind farms, thanks to pioneering research from the University of Surrey.
Biological systems have inspired the development of next-generation soft robotic systems with diverse motions and functions. Such versatility in soft robots—in terms of rapid and efficient crawling—can be achieved via asymmetric bending through bilayer-type actuators that combine responsive liquid crystal elastomers (LCEs) with flexible substrates. This, in turn, requires temperature-responsive LCEs with accurate temperature regulation via elaborate Joule heating configurations.
Order picking is widely reported to account for 50% to 55% of total warehouse operational costs. Identifying the right picking strategy can have a significant impact on the bottom line.
In this interview series, we’re meeting some of the AAAI/SIGAI Doctoral Consortium participants to find out more about their research. In this latest interview, Haimin Hu tells us about his research on the algorithmic foundations of human-centered autonomy and his plans for future projects, and gives some advice for PhD students looking to take the next step in their career.
Could you give us an overview of the research you carried out during your PhD?
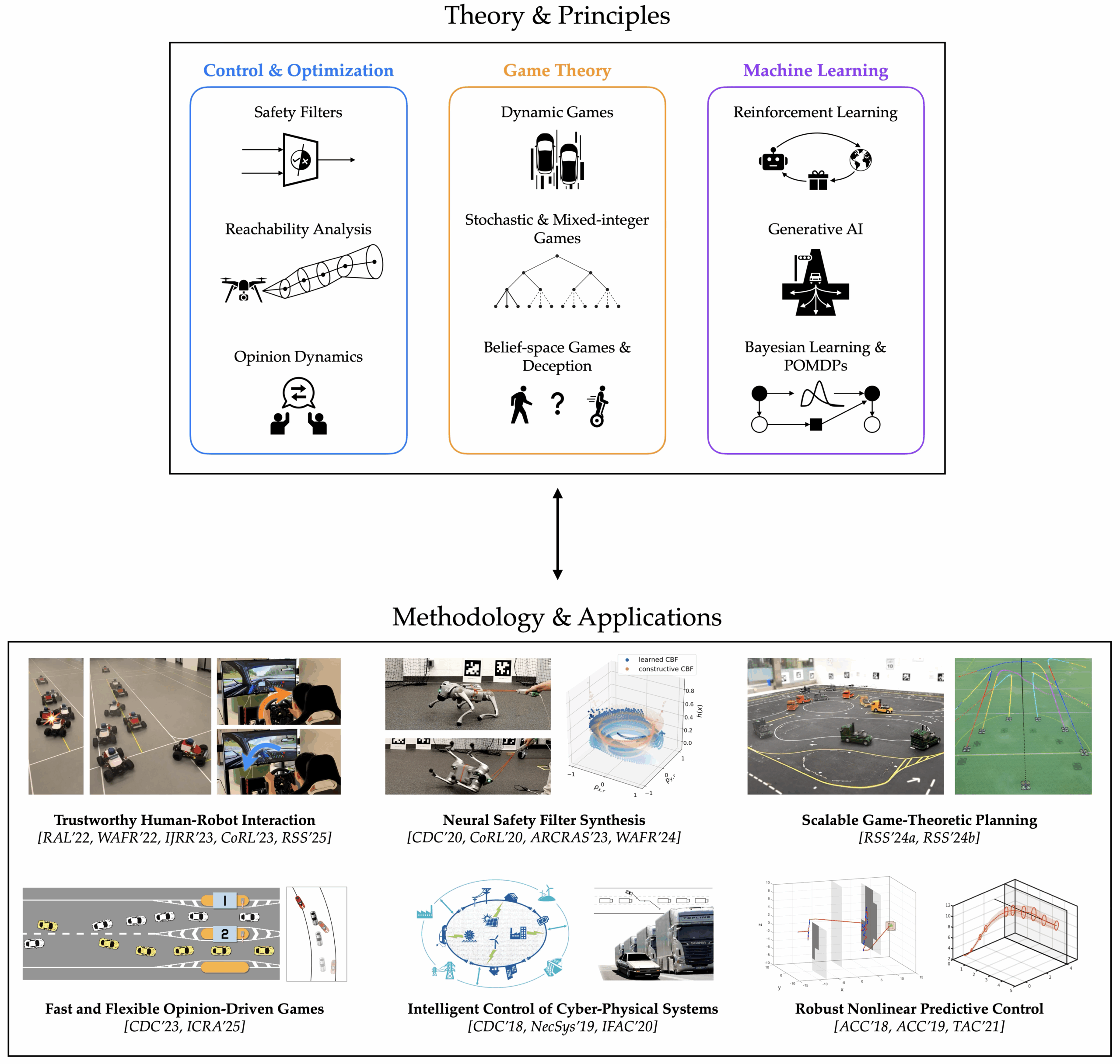
My PhD research, conducted under the supervision of Professor Jaime Fernández Fisac in the Princeton Safe Robotics Lab, focuses on the algorithmic foundations of human-centered autonomy. By integrating dynamic game theory with machine learning and safety-critical control, my work aims to ensure autonomous systems, from self-driving vehicles to drones and quadrupedal robots, are performant, verifiable, and trustworthy when deployed in human-populated space. The core principle of my PhD research is to plan robots’ motion in the joint space of both physical and information states, actively ensuring safety as they navigate uncertain, changing environments and interact with humans. Its key contribution is a unified algorithmic framework—backed by game theory—that allows robots to safely interact with their human peers, adapt to human preferences and goals, and even help humans refine their skills. Specifically, my PhD work contributes to the following areas in human-centered autonomy and multi-agent systems:
Trustworthy human–robot interaction: Planning safe and efficient robot trajectories by closing the computation loop between physical human-robot interaction and runtime learning that reduces the robot’s uncertainty about the human.
Verifiable neural safety analysis for complex robotic systems: Learning robust neural controllers for robots with high-dimensional dynamics; guaranteeing their training-time convergence and deployment-time safety.
Scalable interactive planning under uncertainty: Synthesizing game-theoretic control policies for complex and uncertain human–robot systems at scale.
Was there a project (or aspect of your research) that was particularly interesting?
Safety in human-robot interaction is especially difficult to define, because it hinges on an, I’d say, almost unanswerable question: How safe is safe enough when humans might behave in arbitrary ways? To give a concrete example: Is it sufficient if an autonomous vehicle can avoid hitting a fallen cyclist 99.9% of the time? What if this rate can only be achieved by the vehicle always stopping and waiting for the human to move out of the way?
I would argue that, for trustworthy deployment of robots in human-populated space, we need to complement standard statistical methods with clear-cut robust safety assurances under a vetted set of operation conditions as well established as those of bridges, power plants, and elevators. We need runtime learning to minimize the robot’s performance loss caused by safety-enforcing maneuvers; this calls for algorithms that can reduce the robot’s inherent uncertainty induced by its human peers, for example, their intent (does a human driver want to merge, cut behind, or stay in the lane?) or response (if the robot comes closer, how will the human react?). We need to close the loop between the robot’s learning and decision-making so that it can optimize efficiency by anticipating how its ongoing interaction with the human may affect the evolving uncertainty, and ultimately, its long-term performance.
What made you want to study AI, and the area of human-centered robotic systems in particular?
I’ve been fascinated by robotics and intelligent systems since childhood, when I’d spend entire days watching sci-fi anime like Mobile Suit Gundam, Neon Genesis Evangelion, or Future GPX Cyber Formula. What captivated me wasn’t just the futuristic technology, but the vision of AI as a true partner—augmenting human abilities rather than replacing them. Cyber Formula in particular planted the idea of human-AI co-evolution in my mind: an AI co-pilot that not only helps a human driver navigate high-speed, high-stakes environments, but also adapts to the driver’s style over time, ultimately making the human a better racer and deepening mutual trust along the way. Today, during my collaboration with Toyota Research Institute (TRI), I work on human-centered robotics systems that embody this principle: designing AI systems that collaborate with people in dynamic, safety-critical settings by rapidly aligning with human intent through multimodal inputs, from physical assistance to visual cues and language feedback, bringing to life the very ideas that once lived in my childhood imagination.
You’ve landed a faculty position at Johns Hopkins University (JHU) – congratulations! Could you talk a bit about the process of job searching, and perhaps share some advice and insights for PhD students who may be at a similar stage in their career?
The job search was definitely intense but also deeply rewarding. My advice to PhD students: start thinking early about the kind of long-term impact you want to make, and act early on your application package and job talk. Also, make sure you talk to people, especially your senior colleagues and peers on the job market. I personally benefited a lot from the following resources:
Autonomy Talks (examples of great talks in broad areas of autonomy and AI)
Do you have an idea of the research projects you’ll be working on at JHU?
I wish to help create a future where humans can unquestionably embrace the presence of robots around them. Towards this vision, my lab at JHU will investigate the following topics:
Uncertainty-aware interactive motion planning: How can robots plan safe and efficient motion by accounting for their evolving uncertainty, as well as their ability to reduce it through future interaction, sensing, communication, and learning?
Human–AI co-evolution and co-adaptation: How can embodied AI systems learn from human teammates while helping them refine existing skills and acquire new ones in a safe, personalized manner?
Safe human-compatible autonomy: How can autonomous systems ensure prescribed safety while remaining aligned with human values and attuned to human cognitive limitations?
Scalable and generalizable strategic decision-making: How can multi-robot systems make safe, coordinated decisions in dynamic, human-populated environments?
How was the experience attending the AAAI Doctoral Consortium?
I had the privilege of attending the 2025 AAAI Doctoral Consortium, and it was an incredibly valuable experience. I’m especially grateful to the organizers for curating such a thoughtful and supportive environment for early-career researchers. The highlight for me was the mentoring session with Dr Ming Yin (postdoc at Princeton, now faculty at Georgia Tech CSE), whose insights on navigating the uncertain and competitive job market were both encouraging and eye-opening.
Could you tell us an interesting (non-AI related) fact about you?
I am passionate about skiing. I learned to ski primarily by vision-based imitation learning from a chairlift, though I’m definitely paying the price now for poor generalization! One day, I hope to build an exoskeleton that teaches me to ski better while keeping me safe on the double black diamonds.
About Haimin
Haimin Hu is an incoming Assistant Professor of Computer Science at Johns Hopkins University, where he is also a member of the Data Science and AI Institute, the Institute for Assured Autonomy, and the Laboratory for Computational Sensing and Robotics. His research focuses on the algorithmic foundations of human-centered autonomy. He has received several awards and recognitions, including a 2025 Robotics: Science and Systems Pioneer, a 2025 Cyber-Physical Systems Rising Star, and a 2024 Human-Robot Interaction Pioneer. Additionally, he has served as an Associate Editor for IEEE Robotics and Automation Letters since his fourth year as a PhD student. He obtained a PhD in Electrical and Computer Engineering from Princeton University in 2025, an MSE in Electrical Engineering from the University of Pennsylvania in 2020, and a BE in Electronic and Information Engineering from ShanghaiTech University in 2018.
At UC Berkeley, researchers in Sergey Levine's Robotic AI and Learning Lab eyed a table where a tower of 39 Jenga blocks stood perfectly stacked. Then a white-and-black robot, its single limb doubled over like a hunched-over giraffe, zoomed toward the tower, brandishing a black leather whip. Through what might have seemed to a casual viewer like a miracle of physics, the whip struck in precisely the right spot to send a single block flying from the stack while the rest of the tower remained structurally sound.
Modular robots built by Dartmouth researchers are finding their feet outdoors. Engineered to assemble into structures that best suit the task at hand, the robots are pieced together from cube-shaped robotic blocks that combine rigid rods and soft, stretchy strings whose tension can be adjusted to deform the blocks and control their shape.
Robots come in a vast array of shapes and sizes. By definition, they're machines that perform automatic tasks and can be operated by humans, but sometimes work autonomously—without human help.
Researchers from Scottish universities have developed an innovative way to breathe new life into outdated robot pets and toys using augmented reality technology.
For humanoid robots, size and weight are critical. The form factor must mimic human proportions while housing a complex network of sensors, motors and mechanical joints. This is where thin-section bearings prove essential.
While working at NASA in 2003, Dr. Robert Ambrose, director of the Robotics and Automation Design Lab (RAD Lab), designed a robot with no fixed top or bottom. A perfect sphere, the RoboBall could not flip over, and its shape promised access to places wheeled or legged machines could not reach—from the deepest lunar crater to the uneven sands of a beach.
The fastest way to stall an agentic AI project is to reuse a workflow that no longer fits. Using syftr, we identified “silver bullet” flows for both low-latency and high-accuracy priorities that consistently perform well across multiple datasets. These flows outperform random seeding and transfer learning early in optimization. They recover about 75% of the performance of a full syftr run at a fraction of the cost, which makes them a fast starting point but still leaves room to improve.
If you have ever tried to reuse an agentic workflow from one project in another, you know how often it falls flat. The model’s context length might not be enough. The new use case might require deeper reasoning. Or latency requirements might have changed.
Even when the old setup works, it may be overbuilt – and overpriced – for the new problem. In those cases, a simpler, faster setup might be all you need.
We set out to answer a simple question: Are there agentic flows that perform well across many use cases, so you can choose one based on your priorities and move forward?
Our research suggests the answer is yes, and we call them “silver bullets.”
We identified silver bullets for both low-latency and high-accuracy goals. In early optimization, they consistently beat transfer learning and random seeding, while avoiding the full cost of a full syftr run.
In the sections that follow, we explain how we found them and how they stack up against other seeding strategies.
A quick primer on Pareto-frontiers
You don’t need a math degree to follow along, but understanding the Pareto-frontier will make the rest of this post much easier to follow.
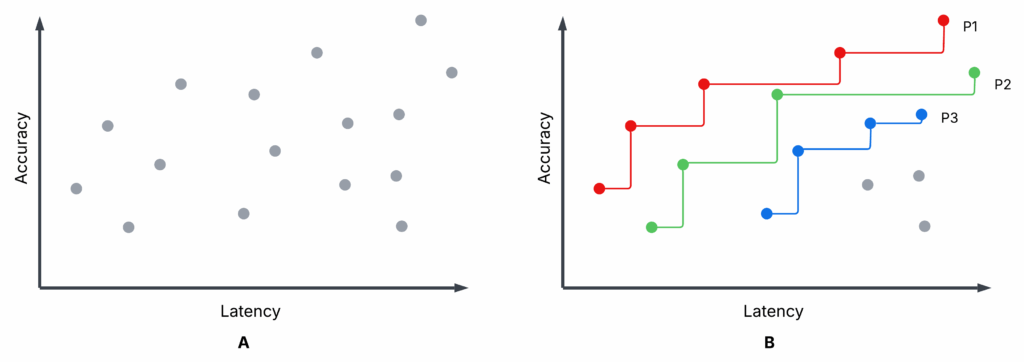
Figure 1 is an illustrative scatter plot – not from our experiments – showing completed syftr optimization trials. Sub-plot A and Sub-plot B are identical, but B highlights the first three Pareto-frontiers: P1 (red), P2 (green), and P3 (blue).
Each trial: A specific flow configuration is evaluated on accuracy and average latency (higher accuracy, lower latency are better).
Pareto-frontier (P1): No other flow has both higher accuracy and lower latency. These are non-dominated.
Non-Pareto flows: At least one Pareto flow beats them on both metrics. These are dominated.
P2, P3: If you remove P1, P2 becomes the next-best frontier, then P3, and so on.
You might choose between Pareto flows depending on your priorities (e.g., favoring low latency over maximum accuracy), but there’s no reason to choose a dominated flow — there’s always a better option on the frontier.
Optimizing agentic AI flows with syftr
Throughout our experiments, we used syftr to optimize agentic flows for accuracy and latency.
Set objectives such as accuracy and cost, or in this case, accuracy and latency
In short, syftr automates the exploration of flow configurations against your chosen objectives.
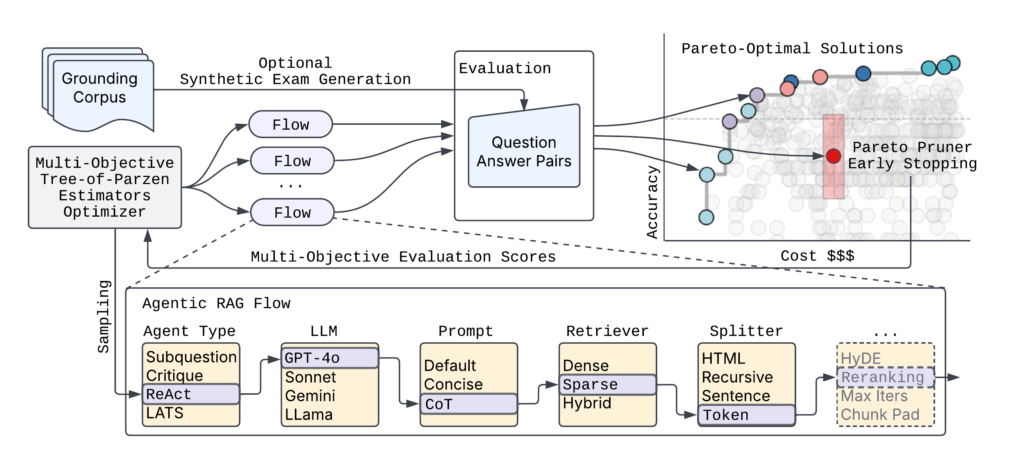
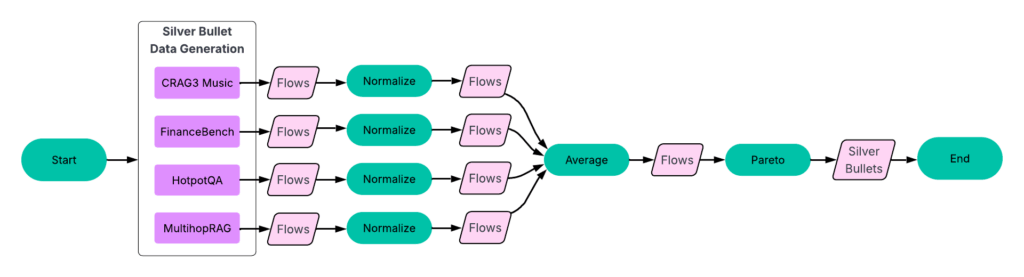
Figure 2 shows the high-level syftr architecture.
Figure 2: High-level syftr architecture. For a set of QA pairs, syftr can automatically explore agentic flows using multi-objective Bayesian optimization by comparing flow responses with actual answers.
Given the practically endless number of possible agentic flow parametrizations, syftr relies on two key techniques:
Multi-objective Bayesian optimization to navigate the search space efficiently.
ParetoPruner to stop evaluation of likely suboptimal flows early, saving time and compute while still surfacing the most effective configurations.
Silver bullet experiments
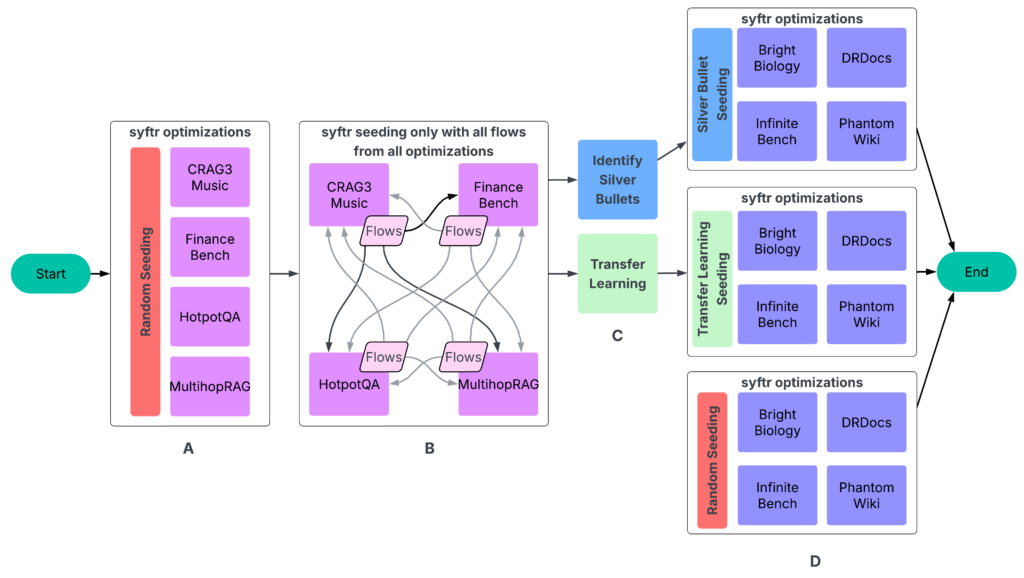
Our experiments followed a four-part process (Figure 3).
Figure 3: The workflow starts with a two-step data generation phase: A: Run syftr using simple random sampling for seeding. B: Run all finished flows on all other experiments. The resulting data then feeds into the next step. C: Identifying silver bullets and conducting transfer learning. D: Running syftr on four held-out datasets three times, using three different seeding strategies.
Step 1: Optimize flows per dataset
We ran several hundred trials on each of the following datasets:
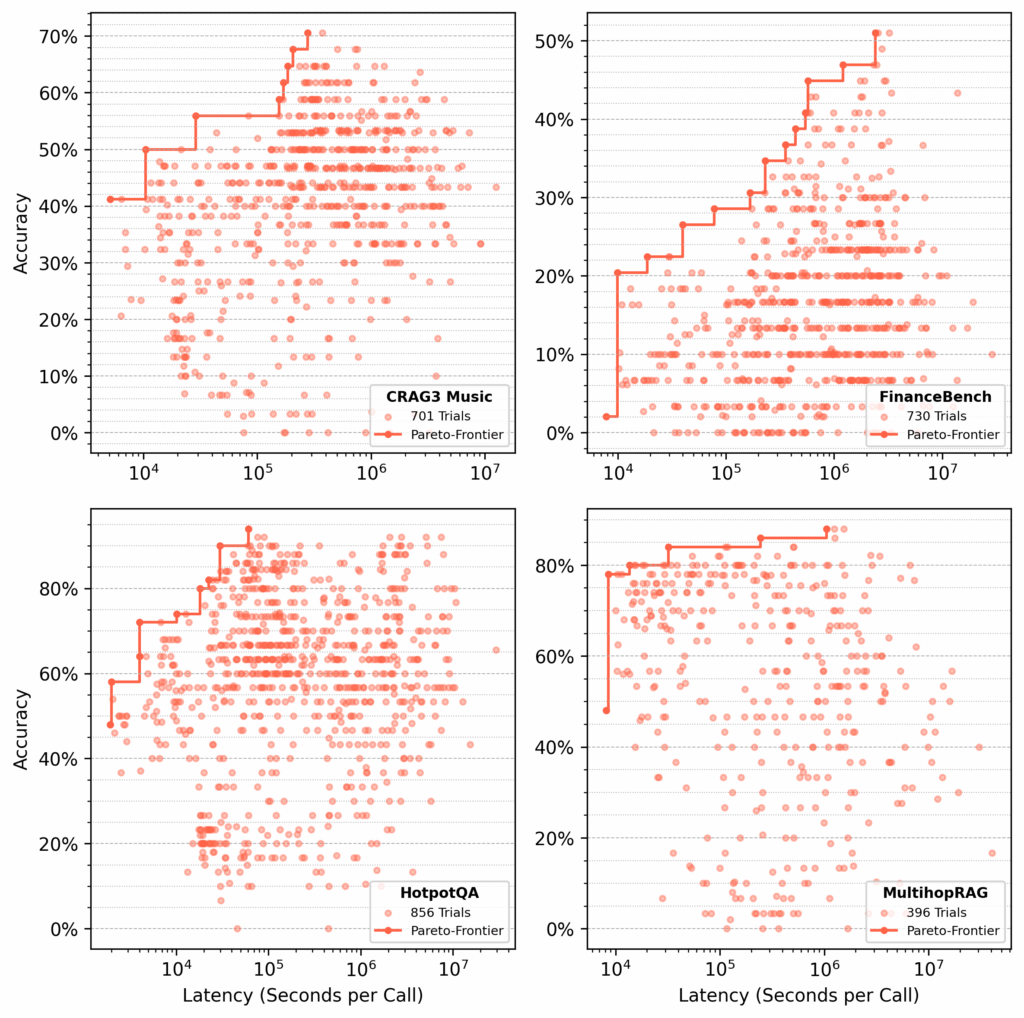
CRAG Task 3 Music
FinanceBench
HotpotQA
MultihopRAG
For each dataset, syftr searched for Pareto-optimal flows, optimizing for accuracy and latency (Figure 4).
Figure 4: Optimization results for four datasets. Each dot represents a parameter combination evaluated on 50 QA pairs. Red lines mark Pareto-frontiers with the best accuracy–latency tradeoffs found by the TPE estimator.
Step 3: Identify silver bullets
Once we had identical flows across all training datasets, we could pinpoint the silver bullets — the flows that are Pareto-optimal on average across all datasets.
Figure 5: Silver bullet generation process, detailing the “Identify Silver Bullets” step from Figure 3.
Process:
Normalize results per dataset. For each dataset, we normalize accuracy and latency scores by the highest values in that dataset.
Group identical flows. We then group matching flows across datasets and calculate their average accuracy and latency.
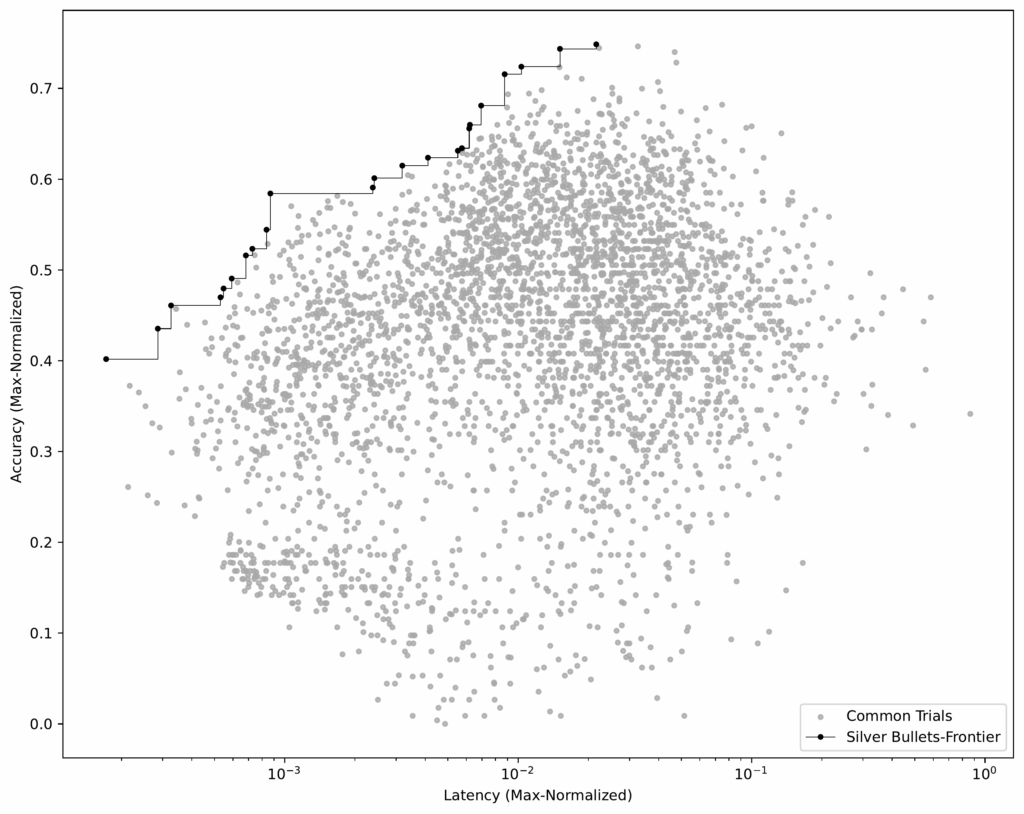
Identify the Pareto-frontier. Using this averaged dataset (see Figure 6), we select the flows that build the Pareto-frontier.
These 23 flows are our silver bullets — the ones that perform well across all training datasets.
Figure 6: Normalized and averaged scores across datasets. The 23 flows on the Pareto-frontier perform well across all training datasets.
Step 4: Seed with transfer learning
In our original syftr paper, we explored transfer learning as a way to seed optimizations. Here, we compared it directly against silver bullet seeding.
In this context, transfer learning simply means selecting specific high-performing flows from historical (training) studies and evaluating them on held-out datasets. The data we use here is the same as for silver bullets (Figure 3).
Process:
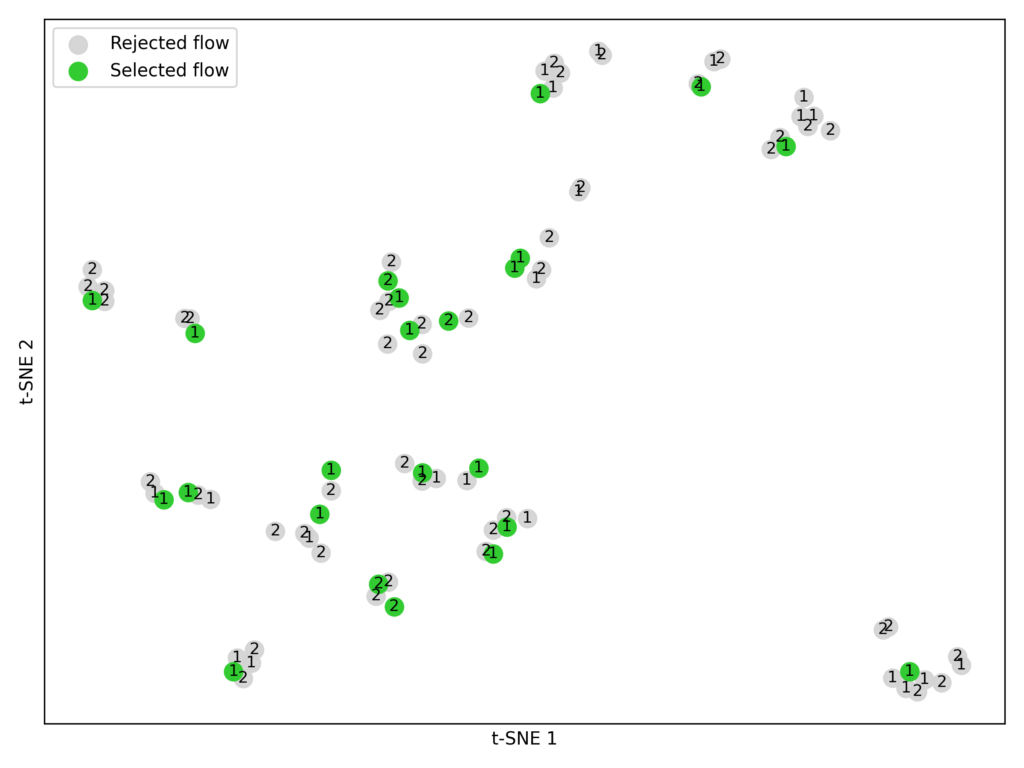
Select candidates. From each training dataset, we took the top-performing flows from the top two Pareto-frontiers (P1 and P2).
Embed and cluster. Using the embedding model BAAI/bge-large-en-v1.5, we converted each flow’s parameters into numerical vectors. We then applied K-means clustering (K = 23) to group similar flows (Figure 7).
Match experiment constraints. We limited each seeding strategy (silver bullets, transfer learning, random sampling) to 23 flows for a fair comparison, since that’s how many silver bullets we identified.
Note: Transfer learning for seeding isn’t yet fully optimized. We could use more Pareto-frontiers, select more flows, or try different embedding models.
Figure 7: Clustered trials from Pareto-frontiers P1 and P2 across the training datasets.
Step 5: Testing it all
In the final evaluation phase (Step D in Figure 3), we ran ~1,000 optimization trials on four test datasets — Bright Biology, DRDocs, InfiniteBench, and PhantomWiki — repeating the process three times for each of the following seeding strategies:
Silver bullet seeding
Transfer learning seeding
Random sampling
For each trial, GPT-4o-mini served as the judge, verifying an agent’s response against the ground-truth answer.
Results
We set out to answer:
Which seeding approach — random sampling, transfer learning, or silver bullets — delivers the best performance for a new dataset in the fewest trials?
For each of the four held-out test datasets (Bright Biology, DRDocs, InfiniteBench, and PhantomWiki), we plotted:
Accuracy
Latency
Cost
Pareto-area: a measure of how close results are to the optimal result
In each plot, the vertical dotted line marks the point when all seeding trials have completed. After seeding, silver bullets showed on average:
9% higher maximum accuracy
84% lower minimum latency
28% larger Pareto-area
compared to the other strategies.
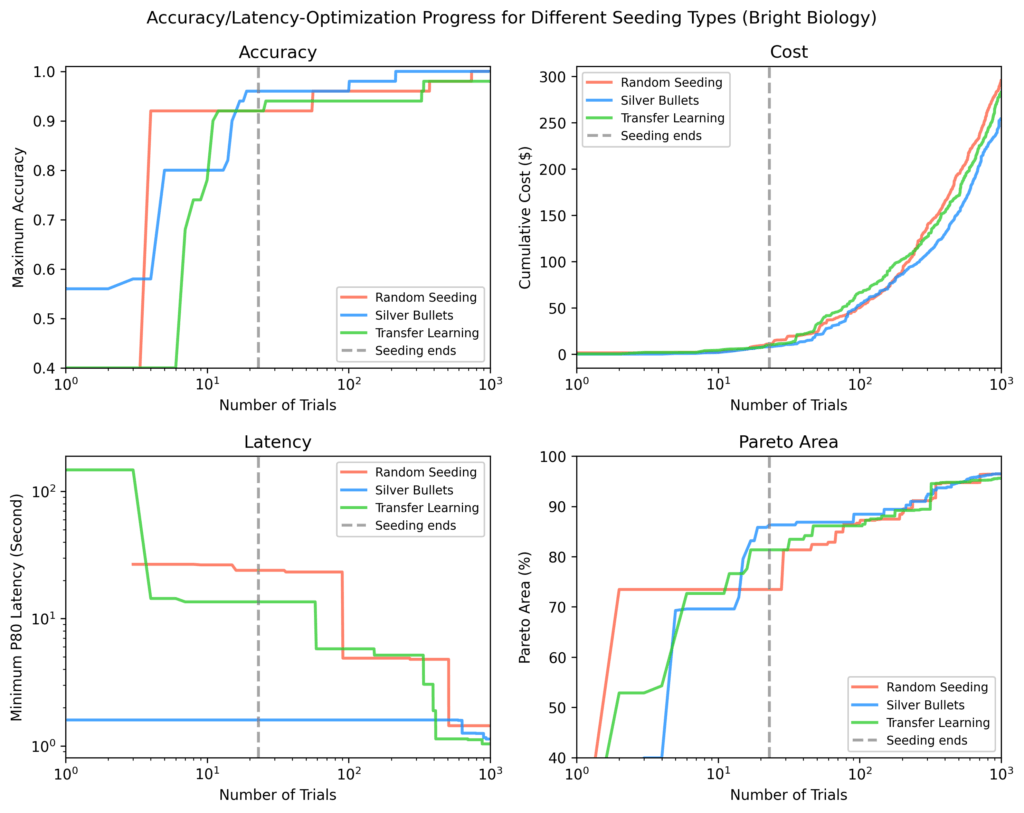
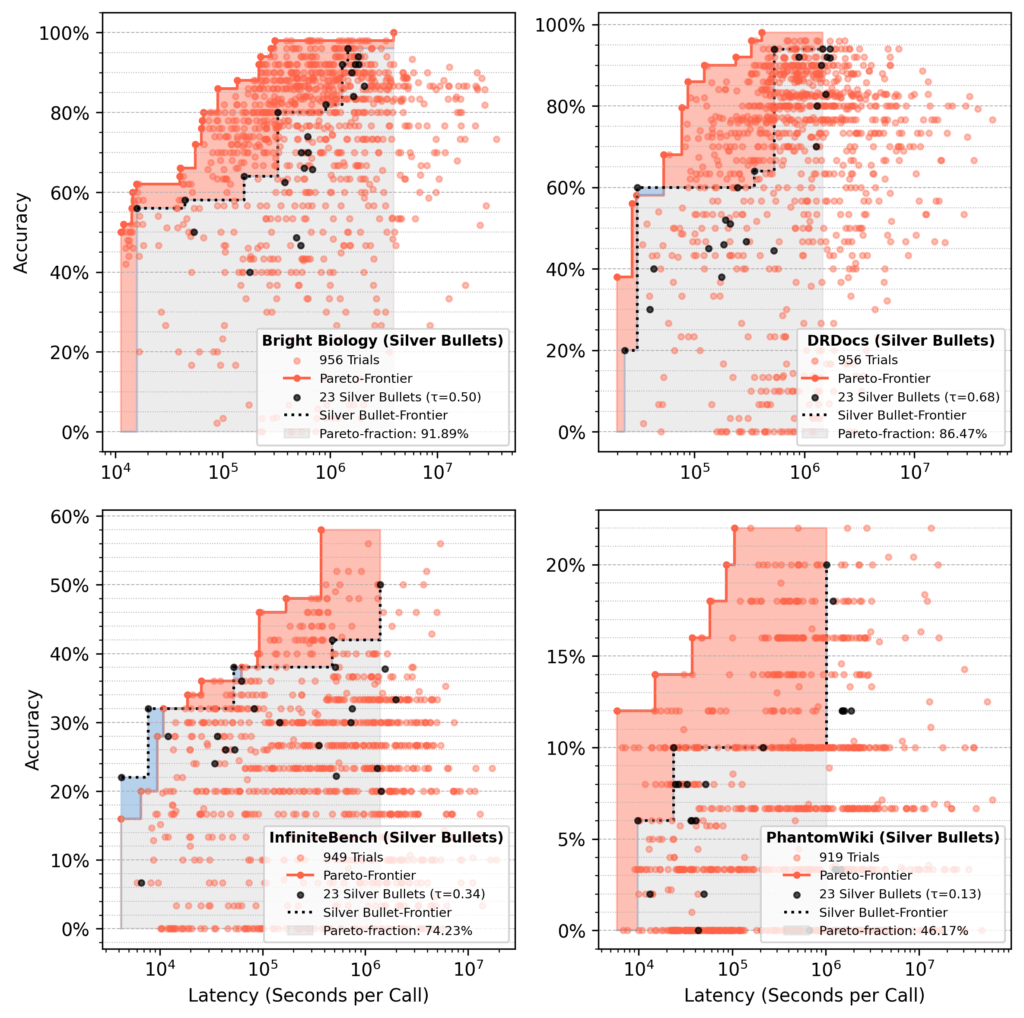
Bright Biology
Silver bullets had the highest accuracy, lowest latency, and largest Pareto-area after seeding. Some random seeding trials did not finish. Pareto-areas for all methods increased over time but narrowed as optimization progressed.
Figure 8: Bright Biology results
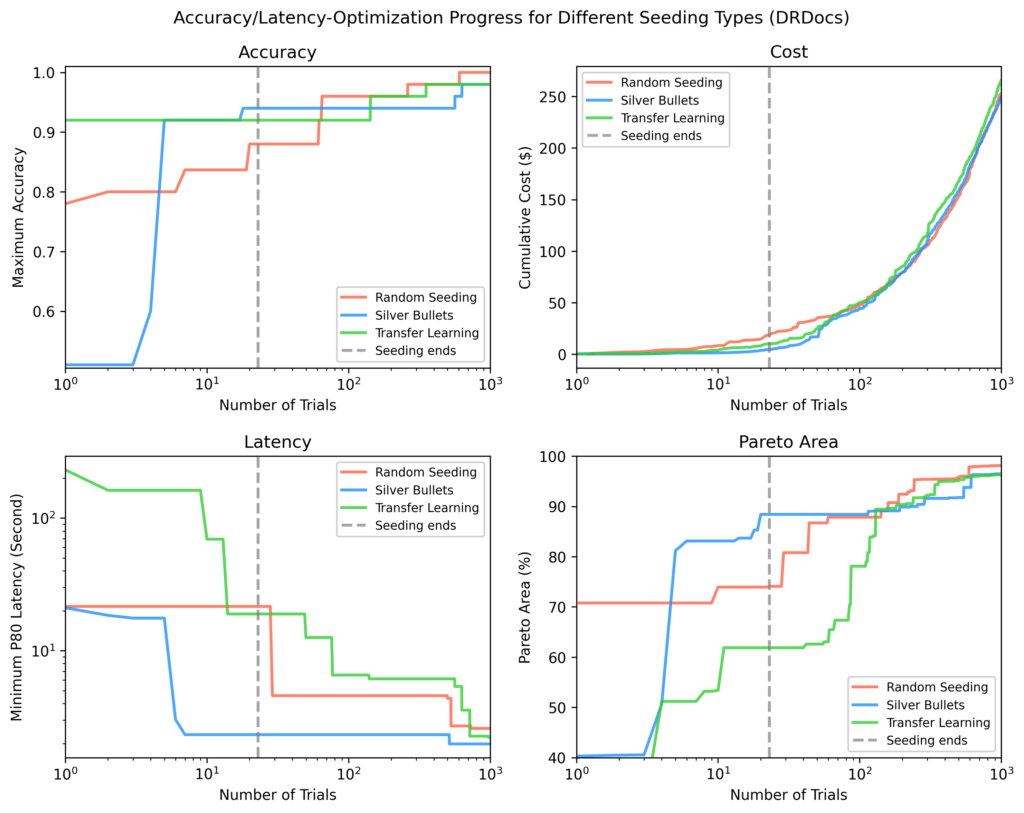
DRDocs
Similar to Bright Biology, silver bullets reached an 88% Pareto-area after seeding vs. 71% (transfer learning) and 62% (random).
Figure 9: DRDocs results
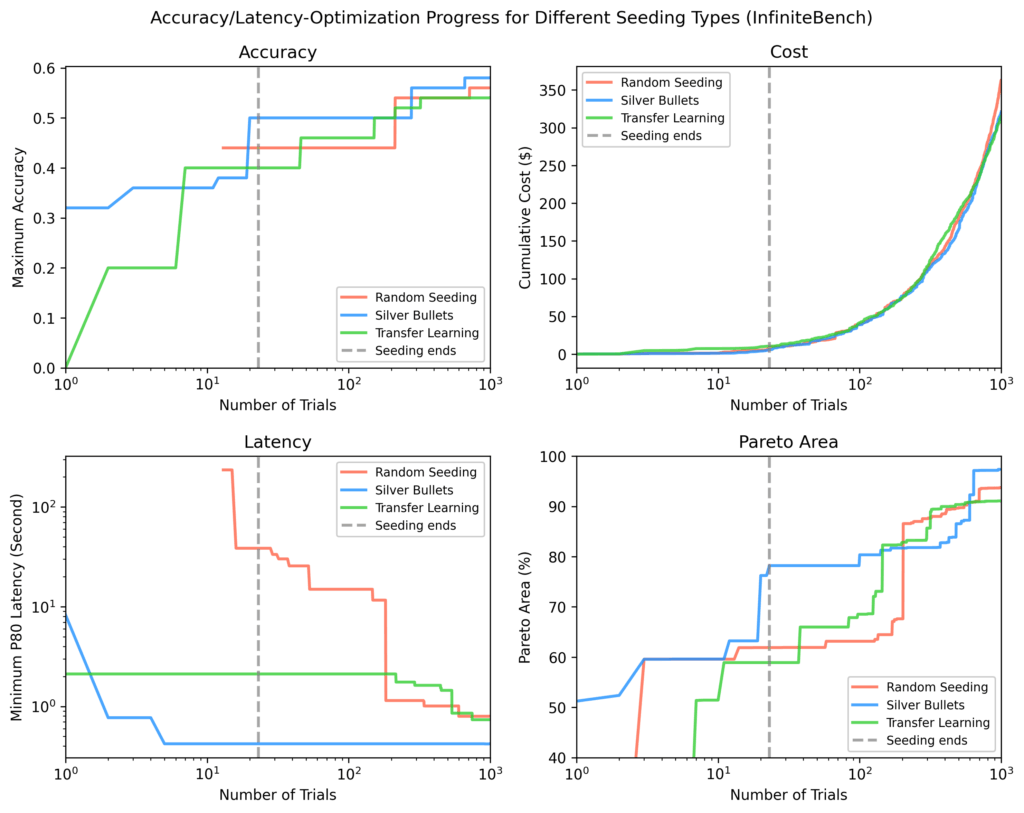
InfiniteBench
Other methods needed ~100 additional trials to match the silver bullet Pareto-area, and still didn’t match the fastest flows found via silver bullets by the end of ~1,000 trials.
Figure 10: InfiniteBench results
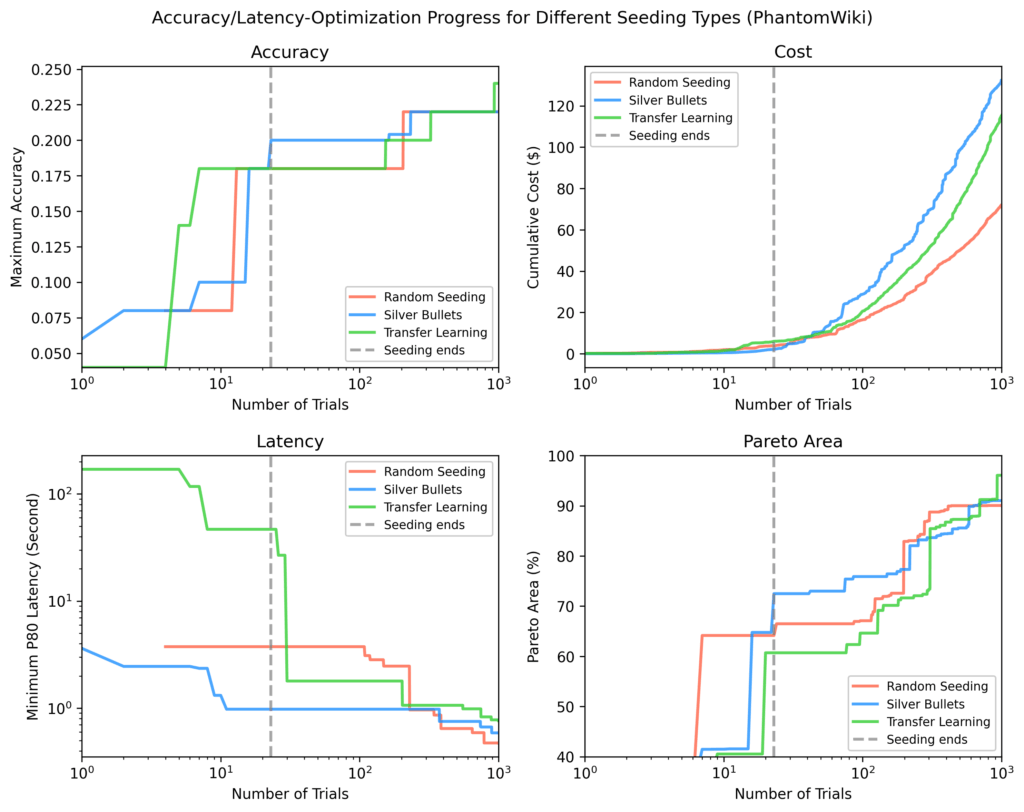
PhantomWiki
Silver bullets again performed best after seeding. This dataset showed the widest cost divergence. After ~70 trials, the silver bullet run briefly focused on more expensive flows.
Figure 11: PhantomWiki results
Pareto-fraction analysis
In runs seeded with silver bullets, the 23 silver bullet flows accounted for ~75% of the final Pareto-area after 1,000 trials, on average.
Red area: Gains from optimization over initial silver bullet performance.
Blue area: Silver bullet flows still dominating at the end.
Figure 12: Pareto-fraction for silver bullet seeding across all datasets
Our takeaway
Seeding with silver bullets delivers consistently strong results and even outperforms transfer learning, despite that method pulling from a diverse set of historical Pareto-frontier flows.
For our two objectives (accuracy and latency), silver bullets always start with higher accuracy and lower latency than flows from other strategies.
In the long run, the TPE sampler reduces the initial advantage. Within a few hundred trials, results from all strategies often converge, which is expected since each should eventually find optimal flows.
So, do agentic flows exist that work well across many use cases? Yes — to a point:
On average, a small set of silver bullets recovers about 75% of the Pareto-area from a full optimization.
Performance varies by dataset, such as 92% recovery for Bright Biology compared to 46% for PhantomWiki.
Bottom line: silver bullets are an inexpensive and efficient way to approximate a full syftr run, but they are not a replacement. Their impact could grow with more training datasets or longer training optimizations.
Here’s the full list of all 23 silver bullets, sorted from low accuracy / low latency to high accuracy / high latency: silver_bullets.json.
Try it yourself
Want to experiment with these parametrizations? Use the running_flows.ipynb notebook in our syftr repository — just make sure you have access to the models listed above.
For a deeper dive into syftr’s architecture and parameters, check out our technical paper or explore the codebase.