As every other Saturday, I’m bringing you another cool open-source project from James Bruton. Today, how about becoming an experimental musician with your own barcode scanner synthesizer?
I introduced James Bruton in the first post of this focus series on him, where I showed you the Boston Dynamics-inspired open robot dogs projects that consolidated him as one of the top maker on YouTube. As a sort of musician, the barcode synth project I’ve picked for this second post grabbed my attention among the countless videos he’s got on his channel.
To be more specific, the barcode synth consists of two projects. A bit more than a year ago, James showed how to build a four-neck guitar synth with the frets (the place where you put your fingers to play a note on the guitar) being barcodes instead of strings. To play this guitar, you only need a barcode reader connected to an Arduino that converts the data read from the barcodes into a number that represents a MIDI note – which is a digital representation of a musical note based on the MIDI standard. You can then plug the Arduino into a synth or your computer (if you love virtual instruments as much as I do!) to transform the MIDI output into actual sound. Extra features of this guitar included pitch bending and octave shifting buttons. You can access the open-source code of this type of guitar here, and enjoy James’ explanation (and performance) in the following video:
A couple of months ago, James made an improved version of the previous guitar synth. Instead of using the number given by the barcode, for this improved synth he hacked the barcode reader to interpret the barcodes as images so that the output is the raw square wave that it sees. With he help of a Teensy microcontroller to do the digital signal processing and a Raspberry Pi to display barcode images on a screen fitted to a 3D-printed guitar, he could produce a richer range of sounds compared to the previous version. If you want to build you own barcode synth, check out the open-source files and his video (you’ll be impressed to find out how a zebra sounds like!):
New research has shown robots can encourage humans to take greater risks in a simulated gambling scenario than they would if there was nothing to influence their behaviours. Increasing our understanding of whether robots can affect risk-taking could have clear ethical, practical and policy implications, which this study set out to explore.
Several global organizations are already developing more and more uses for robots for inspection, maintenance, and repairs. Let’s look at some reasons why robotic units are more popular now
Japan's SoftBank Group will sell an 80 percent stake in robotics firm Boston Dynamics to Hyundai, the trio said Friday, in a deal that values the US company at $1.1 billion.
Although robotics has reshaped and even redefined many industrial sectors, there still exists a gap between machines and humans in fields such as health and elderly care. For robots to safely manipulate or interact with fragile objects and living organisms, new strategies to enhance their perception while making their parts softer are needed. In fact, building a safe and dexterous robotic gripper with human-like capabilities is currently one of the most important goals in robotics.
A team of researchers from the University of Edinburgh and Zhejiang University has developed a way to combine deep neural networks (DNNs) to create a new type of system with a new kind of learning ability. The group describes their new architecture and its performance in the journal Science Robotics.
To achieve navigation accuracy, sensors use algorithms that look at a series of measurements (as opposed to a single measurement) and generate output numbers that compensate for measurement errors. These algorithms are known as sensor fusion algorithms or Kalman filtering.
The gendering of robots is something I’ve found fascinating since I first started building robots out of legos with my brother. We all ascribe character to robots, consciously or not, even when we understand exactly how robots work. Until recently we’ve been able to write this off as science fiction stuff, because real robots were boring industrial arms and anything else was fictional. However, since 2010, robots have been rolling out into the real world in a whole range of shapes, characters and notably, stereotypes. My original research on the naming of robots gave some indications as to just how insidious this human tendency to anthropomorphize and gender robots really is. Now we’re starting to face the consequences and it matters.
Firstly, let’s consider that many languages have gendered nouns, so there is a preliminary linguistic layer of labelling, ahead of the naming of robots, which if not defined, then tends to happen informally. The founders of two different robot companies have told me that they know when their robot has been accepted in a workplace by when it’s been named by teammates, and they deliberately leave the robot unnamed. Whereas some other companies focus on a more nuanced brand name such as Pepper or Relay, which can minimize gender stereotypes, but even then the effects persist.
Because with robots the physical appearance can’t be ignored and often aligns with ideas of gender. Next, there is the robot voice. Then, there are other layers of operation which can affect both a robot’s learning and its response. And finally, there is the robot’s task or occupation and its socio-cultural context.
Names are both informative and performative. We can usually ascribe a gender to a named object. Similarly, we can ascribe gender based on a robot’s appearance or voice, although it can differ in socio-cultural contexts.
Astro Boy original comic and Pepper from SoftBank Robotics
The robot Pepper was designed to be a childlike humanoid and according to SoftBank Robotics, Pepper is gender neutral. But in general, I’ve found that US people tend to see Pepper as female helper, while Asian people are more likely to see Pepper as a boy robot helper. This probably has something to do with the popularity of Astro Boy (Mighty Atom) from 1952 to 1968.
One of the significant issues with gendering robots is that once embodied, individuals are unlikely to have the power to change the robot that they interact with. Even if they rename it, recostume it and change the voice, the residual gender markers will be pervasive and ‘neutral’ will still elicit a gender response in everybody.
This will have an impact on how we treat and trust robots. This also has much deeper social implications for all of us, not just those who interact with robots, as robots are recreating all of our existing gender biases. And once the literal die is cast and robots are rolling out of a factory, it will be very hard to subsequently change the robot body.
Interestingly, I’m noticing a transition from a default male style of robot (think of all the small humanoid fighting, dancing and soccer playing robots) to a default female style of robot as the service robotics industry starts to grow. Even when the robot is simply a box shape on wheels, the use of voice can completely change our perception. One of the pioneering service robots from Savioke, Relay, deliberately preselected a neutral name for their robot and avoided using a human voice completely. Relay makes sounds but doesn’t use words. Just like R2D2, Relay expresses character through beeps and boops. This was a conscious, and significant, design choice for Savioke. Their preliminary experimentation on human-robot interaction showed that robots that spoke were expected to answer questions, and perform tasks at a higher level of competency than a robot that beeped.
Relay from Savioke delivering at Aloft Hotel
Not only did Savioke remove the cognitive dissonance of having a robot seem more human that it really is, but they removed some of the reiterative stereotyping that is starting to occur with less thoughtful robot deployments. The best practice for designing robots for real world interaction is to minimize human expressivity and remove any gender markers. (more about that next).
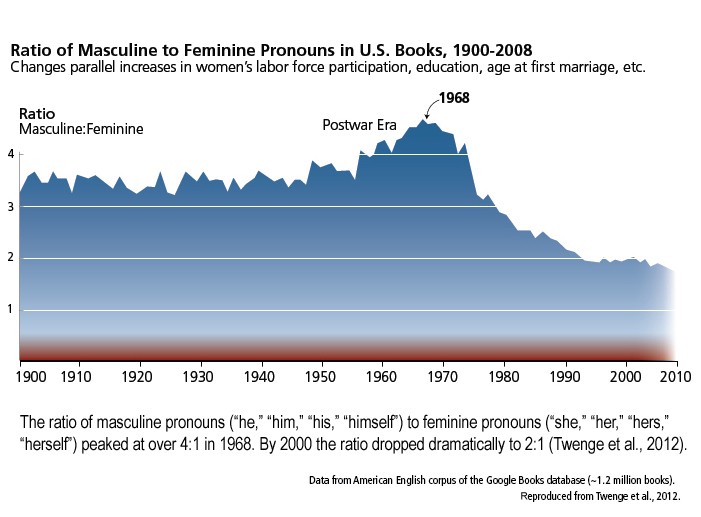
The concept of ‘marked’ and ‘unmarked’ arose in linguistics in the 1930s, but we’ve seen it play out in Natural Language Processing, search and deep learning repeatedly since then, perpetuating, reiterating and exaggerating the use of masculine terminology as the default, and feminine terminology used only in explicit (or marked) circumstances. Marked circumstances almost always relate to sexual characteristics or inferiority within power dynamics, rather than anything more interesting.
An example of unmarked or default terminology is the use of ‘man’ to describe people, but ‘woman’ to only describe a subset of ‘man’. This is also commonly seen in the use of a female specifier on a profession, ie. female police officer, female president, or female doctor. Otherwise, in spite of there being many female doctors, the search will return male examples, call female doctors he, or miscategorize them as nurse. We are all familiar with those mistakes in real life but had developed social policies to reduce the frequency of them. Now AI and robotics are bringing the stereotype back.
And so it happens that the ‘neutral’ physical appearance of robots is usually assumed to be male, rather than female, unless the robot has explicit female features. Sadly, female robots mean either a sexualized robot, or a robot performing a stereotypically female role. This is how people actually see and receive robots unless a company, like Savioke, consciously refrains from triggering our stereotypically gendered responses.
I can vouch for the fact that searching for images using the term “female roboticists”, for example, always presents me with lots of men building female robots instead. It will take a concerted effort to change things. Robot builders have the tendency to give our robots character. And unless you happen to be a very good (and rich) robotics company, there is also no financial incentive to degender robots. Quite the opposite. There is financial pressure to take advantage of our inherent anthropomorphism and gender stereotypes.
In The Media Equation in 1996, Clifford Reeves and Byron Nass demonstrated how we all attributed character, including gender, to our computing machines, and that this then affected our thoughts and actions, even though most people consciously deny conflating a computer with a personality. This unconscious anthropomorphizing can be used to make us respond differently, so of course robot builders will increasingly utilize the effect as more robots enter society and competition increases.
Can human beings relate to computer or television programs in the same way they relate to other human beings? Based on numerous psychological studies, this book concludes that people not only can but do treat computers, televisions, and new media as real people and places. Studies demonstrate that people are “polite” to computers; that they treat computers with female voices differently than “male” ones; that large faces on a screen can invade our personal space; and that on-screen and real-life motion can provoke the same physical responses.
The Media Equation
The history of voice assistants shows a sad trend. These days, they are all female, with the exception of IBM Watson, but then Watson occupies a different ecosystem niche. Watson is an expert. Watson is the doctor to the rest of our subservient, map reading, shopping list helpful nurses. By default, unless you’re in Arabia, your voice assistant device will have a female voice. You have to go through quite a few steps to consciously change it and there are very few options. In 2019, Q, a genderless voice assistant was introduced, however I can’t find it offered on any devices yet.
And while it may be possible to upload a different voice to a robot, there’s nothing we can do if the physical design of the robot evokes gender. Alan Winfield wrote a very good article “Should robots be gendered?” here on Robohub in 2016, in which he outlines three reasons that gendered robots are a bad idea, all stemming from the 4th of the EPSRC Principles of Robotics, that robots should be transparent in action, rather than capitalizing on the illusion of character, so as not to influence vulnerable people.
Robots are manufactured artefacts: the illusion of emotions and intent should not be used to exploit vulnerable users.
My biggest quibble with the EPSRC Principles is underestimating the size of the problem. By stating that vulnerable users are the young or the elderly, the principles imply that the rest of us are immune from emotional reaction to robots, whereas Reeves and Nass clearly show the opposite. We are all easily manipulated by our digital voice and robot assistants. And while Winfield recognizes that gender queues are powerful enough to elicit a response in everybody, he only sees the explicit gender markers rather than understanding that unmarked or neutral seeming robots also elicit a gendered response, as ‘not female’.
So Winfield’s first concern is emotional manipulation for vulnerable users (all of us!), his second concern is anthropomorphism inducing cognitive dissonance (over promising and under delivering), and his final concern is that the all the negative stereotypes contributing to sexism will be reproduced and reiterated as normal through the introduction of gendered robots in stereotyped roles (it’s happening!). These are all valid concerns, and yet while we’re just waking up to the problem, the service robot industry is growing by more than 30% per annum.
Where the growth of the industrial robotics segment is comparatively predictable, the world’s most trusted robotics statistics body, the International Federation of Robotics is consistently underestimating the growth of the service robotics industry. In 2016, the IFR predicted 10% growth for professional service robotics over the next few years from \$4.6 Billion, but by 2018 they were recording 61% growth to \$12.6B and by 2020 the IFR has recorded 85% overall growth expecting revenue from service robotics to hit \$37B by 2021.
It’s unlikely that we’ll recall robots, once designed, built and deployed, for anything other than a physical safety issue. And the gendering of robots isn’t something we can roll out a software update to fix. We need to start requesting companies to not deploy robots that reinforce gender stereotyping. They can still be cute and lovable, I’m not opposed to the R2D2 robot stereotype!
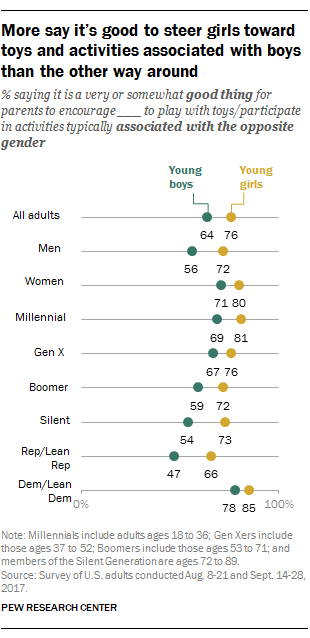
Consumers are starting to fight back against the gender stereotyping of toys, which really only started in the 20th century as a way to extract more money from parents, and some brands are realizing that there’s an opportunity for them in developing gender neutral toys. Recent research from the Pew Research Center found that overall 64% of US adults wanted boys to play with toys associated with girls, and 76% of US adults wanted girls to play with toys associated with boys. The difference between girls and boys can be explained because girls’ role playing (caring and nurturing) is still seen as more negative than boys’ roles (fighting and leadership). But the overall range that shows that society has developed a real desire to avoid gender stereotyping completely.
Sadly, it’s like knowing sugar is bad for us, while it still tastes sweet.
In 2016, I debated Ben Goertzel, maker of Sophia the Robot, on the main stage of the Web Summit on whether humanoid robots were good or bad. I believe I made the better case in terms of argument, but ultimately the crowd sided with Goertzel, and by default with Sophia. (there are a couple of descriptions of the debate referenced below).
Robots are still bright shiny new toys to us. When are we going to realize that we’ve already opened the box and played this game, and women, or any underrepresented group, or any stereotype role, is going to be the loser. No, we’re all going to lose! Because we don’t want these stereotypes any more and robots are just going to reinforce the stereotypes that we already know we don’t want.
The gendering of robots is something I’ve found fascinating since I first started building robots out of legos with my brother. We all ascribe character to robots, consciously or not, even when we understand exactly how robots work. Until recently we’ve been able to write this off as science fiction stuff, because real robots were boring industrial arms and anything else was fictional. However, since 2010, robots have been rolling out into the real world in a whole range of shapes, characters and notably, stereotypes. My original research on the naming of robots gave some indications as to just how insidious this human tendency to anthropomorphize and gender robots really is. Now we’re starting to face the consequences and it matters.
Firstly, let’s consider that many languages have gendered nouns, so there is a preliminary linguistic layer of labelling, ahead of the naming of robots, which if not defined, then tends to happen informally. The founders of two different robot companies have told me that they know when their robot has been accepted in a workplace by when it’s been named by teammates, and they deliberately leave the robot unnamed. Whereas some other companies focus on a more nuanced brand name such as Pepper or Relay, which can minimize gender stereotypes, but even then the effects persist.
Because with robots the physical appearance can’t be ignored and often aligns with ideas of gender. Next, there is the robot voice. Then, there are other layers of operation which can affect both a robot’s learning and its response. And finally, there is the robot’s task or occupation and its socio-cultural context.
Names are both informative and performative. We can usually ascribe a gender to a named object. Similarly, we can ascribe gender based on a robot’s appearance or voice, although it can differ in socio-cultural contexts.
Astro Boy original comic and Pepper from SoftBank Robotics
The robot Pepper was designed to be a childlike humanoid and according to SoftBank Robotics, Pepper is gender neutral. But in general, I’ve found that US people tend to see Pepper as female helper, while Asian people are more likely to see Pepper as a boy robot helper. This probably has something to do with the popularity of Astro Boy (Mighty Atom) from 1952 to 1968.
One of the significant issues with gendering robots is that once embodied, individuals are unlikely to have the power to change the robot that they interact with. Even if they rename it, recostume it and change the voice, the residual gender markers will be pervasive and ‘neutral’ will still elicit a gender response in everybody.
This will have an impact on how we treat and trust robots. This also has much deeper social implications for all of us, not just those who interact with robots, as robots are recreating all of our existing gender biases. And once the literal die is cast and robots are rolling out of a factory, it will be very hard to subsequently change the robot body.
Interestingly, I’m noticing a transition from a default male style of robot (think of all the small humanoid fighting, dancing and soccer playing robots) to a default female style of robot as the service robotics industry starts to grow. Even when the robot is simply a box shape on wheels, the use of voice can completely change our perception. One of the pioneering service robots from Savioke, Relay, deliberately preselected a neutral name for their robot and avoided using a human voice completely. Relay makes sounds but doesn’t use words. Just like R2D2, Relay expresses character through beeps and boops. This was a conscious, and significant, design choice for Savioke. Their preliminary experimentation on human-robot interaction showed that robots that spoke were expected to answer questions, and perform tasks at a higher level of competency than a robot that beeped.
Relay from Savioke delivering at Aloft Hotel
Not only did Savioke remove the cognitive dissonance of having a robot seem more human that it really is, but they removed some of the reiterative stereotyping that is starting to occur with less thoughtful robot deployments. The best practice for designing robots for real world interaction is to minimize human expressivity and remove any gender markers. (more about that next).
The concept of ‘marked’ and ‘unmarked’ arose in linguistics in the 1930s, but we’ve seen it play out in Natural Language Processing, search and deep learning repeatedly since then, perpetuating, reiterating and exaggerating the use of masculine terminology as the default, and feminine terminology used only in explicit (or marked) circumstances. Marked circumstances almost always relate to sexual characteristics or inferiority within power dynamics, rather than anything more interesting.
An example of unmarked or default terminology is the use of ‘man’ to describe people, but ‘woman’ to only describe a subset of ‘man’. This is also commonly seen in the use of a female specifier on a profession, ie. female police officer, female president, or female doctor. Otherwise, in spite of there being many female doctors, the search will return male examples, call female doctors he, or miscategorize them as nurse. We are all familiar with those mistakes in real life but had developed social policies to reduce the frequency of them. Now AI and robotics are bringing the stereotype back.
And so it happens that the ‘neutral’ physical appearance of robots is usually assumed to be male, rather than female, unless the robot has explicit female features. Sadly, female robots mean either a sexualized robot, or a robot performing a stereotypically female role. This is how people actually see and receive robots unless a company, like Savioke, consciously refrains from triggering our stereotypically gendered responses.
I can vouch for the fact that searching for images using the term “female roboticists”, for example, always presents me with lots of men building female robots instead. It will take a concerted effort to change things. Robot builders have the tendency to give our robots character. And unless you happen to be a very good (and rich) robotics company, there is also no financial incentive to degender robots. Quite the opposite. There is financial pressure to take advantage of our inherent anthropomorphism and gender stereotypes.
In The Media Equation in 1996, Clifford Reeves and Byron Nass demonstrated how we all attributed character, including gender, to our computing machines, and that this then affected our thoughts and actions, even though most people consciously deny conflating a computer with a personality. This unconscious anthropomorphizing can be used to make us respond differently, so of course robot builders will increasingly utilize the effect as more robots enter society and competition increases.
Can human beings relate to computer or television programs in the same way they relate to other human beings? Based on numerous psychological studies, this book concludes that people not only can but do treat computers, televisions, and new media as real people and places. Studies demonstrate that people are “polite” to computers; that they treat computers with female voices differently than “male” ones; that large faces on a screen can invade our personal space; and that on-screen and real-life motion can provoke the same physical responses.
The Media Equation
The history of voice assistants shows a sad trend. These days, they are all female, with the exception of IBM Watson, but then Watson occupies a different ecosystem niche. Watson is an expert. Watson is the doctor to the rest of our subservient, map reading, shopping list helpful nurses. By default, unless you’re in Arabia, your voice assistant device will have a female voice. You have to go through quite a few steps to consciously change it and there are very few options. In 2019, Q, a genderless voice assistant was introduced, however I can’t find it offered on any devices yet.
And while it may be possible to upload a different voice to a robot, there’s nothing we can do if the physical design of the robot evokes gender. Alan Winfield wrote a very good article “Should robots be gendered?” here on Robohub in 2016, in which he outlines three reasons that gendered robots are a bad idea, all stemming from the 4th of the EPSRC Principles of Robotics, that robots should be transparent in action, rather than capitalizing on the illusion of character, so as not to influence vulnerable people.
Robots are manufactured artefacts: the illusion of emotions and intent should not be used to exploit vulnerable users.
My biggest quibble with the EPSRC Principles is underestimating the size of the problem. By stating that vulnerable users are the young or the elderly, the principles imply that the rest of us are immune from emotional reaction to robots, whereas Reeves and Nass clearly show the opposite. We are all easily manipulated by our digital voice and robot assistants. And while Winfield recognizes that gender queues are powerful enough to elicit a response in everybody, he only sees the explicit gender markers rather than understanding that unmarked or neutral seeming robots also elicit a gendered response, as ‘not female’.
So Winfield’s first concern is emotional manipulation for vulnerable users (all of us!), his second concern is anthropomorphism inducing cognitive dissonance (over promising and under delivering), and his final concern is that the all the negative stereotypes contributing to sexism will be reproduced and reiterated as normal through the introduction of gendered robots in stereotyped roles (it’s happening!). These are all valid concerns, and yet while we’re just waking up to the problem, the service robot industry is growing by more than 30% per annum.
Where the growth of the industrial robotics segment is comparatively predictable, the world’s most trusted robotics statistics body, the International Federation of Robotics is consistently underestimating the growth of the service robotics industry. In 2016, the IFR predicted 10% growth for professional service robotics over the next few years from \$4.6 Billion, but by 2018 they were recording 61% growth to \$12.6B and by 2020 the IFR has recorded 85% overall growth expecting revenue from service robotics to hit \$37B by 2021.
It’s unlikely that we’ll recall robots, once designed, built and deployed, for anything other than a physical safety issue. And the gendering of robots isn’t something we can roll out a software update to fix. We need to start requesting companies to not deploy robots that reinforce gender stereotyping. They can still be cute and lovable, I’m not opposed to the R2D2 robot stereotype!
Consumers are starting to fight back against the gender stereotyping of toys, which really only started in the 20th century as a way to extract more money from parents, and some brands are realizing that there’s an opportunity for them in developing gender neutral toys. Recent research from the Pew Research Center found that overall 64% of US adults wanted boys to play with toys associated with girls, and 76% of US adults wanted girls to play with toys associated with boys. The difference between girls and boys can be explained because girls’ role playing (caring and nurturing) is still seen as more negative than boys’ roles (fighting and leadership). But the overall range that shows that society has developed a real desire to avoid gender stereotyping completely.
Sadly, it’s like knowing sugar is bad for us, while it still tastes sweet.
In 2016, I debated Ben Goertzel, maker of Sophia the Robot, on the main stage of the Web Summit on whether humanoid robots were good or bad. I believe I made the better case in terms of argument, but ultimately the crowd sided with Goertzel, and by default with Sophia. (there are a couple of descriptions of the debate referenced below).
Robots are still bright shiny new toys to us. When are we going to realize that we’ve already opened the box and played this game, and women, or any underrepresented group, or any stereotype role, is going to be the loser. No, we’re all going to lose! Because we don’t want these stereotypes any more and robots are just going to reinforce the stereotypes that we already know we don’t want.
Follow along with a small AI startup on its journey to scale from 1 to millions of users. Learn what's a typical process to handle steady growth in the userbase, and what tools and techniques one can incorporate. All from a machine learning perspective
Northwestern University researchers have developed a first-of-its-kind life-like material that acts as a soft robot. It can walk at human speed, pick up and transport cargo to a new location, climb up hills and even break-dance to release a particle.
An AMR without a top module is like a robotic arm without an end-effector tool such as a gripper—it lacks functionality. The benefits of AMRs are only realized—and maximized—with top modules and high-quality gates and carts that transfer the transported materials.
THIS WHITE PAPER discusses how manufacturers in many industries are leveraging collaborative robots (cobots) to create safe zones for workers returning to production lines.
When your robot vacuum cleaner does its work around the house, beware that it could pick up private conversations along with the dust and dirt. Computer scientists from NUS have demonstrated that it is indeed possible to spy on private conversations using a common robot vacuum cleaner and its built-in Light Detection and Ranging (Lidar) sensor.
On Friday the 11th of December, Nikolas Martelaro (Assistant Professor at Carnegie Mellon’s Human-Computer Interaction Institute) gave an online seminar on ways robot design teams can do remote user research now (in these COVID-19 times) and in the future. If you missed it, you can now watch the recorded livestream.
About the speaker
Nikolas Martelaro is an Assistant Professor at Carnegie Mellon’s Human-Computer Interaction Institute. Martelaro’s lab focuses on augmenting designer’s capabilities through the use of new technology and design methods. Martelaro’s interest in developing new ways to support designers stems from my interest in creating interactive and intelligent products. Martelaro blends a background in product design methods, interaction design, human-robot interaction, and mechatronic engineering to build tools and methods that allow designers to understand people better and to create more human-centered products. Before moving to the HCII, Nikolas Martelaro was a researcher in the Digital Experiences group at the Accenture Technology Labs. Martelaro graduated with a Ph.D. in Mechanical Engineering from Stanford’s Center for Design Research where he was co-advised by Larry Leifer and Wendy Ju.
Abstract
COVID-19 has led to decreases in in-person user research. While designers who work on software can shift to using all digital remote research methods, people who work on hardware systems, including robots, are left with limited options. In this talk, I will discuss some ways the robot design teams can do remote user research now and in the future. I will draw on past work in human-computer interaction as well as my own work in creating systems to allow remote design teams to conduct remote observation and interaction prototyping. While things can be challenging for the user researcher team today, I believe that with some creative new methods, we can expand our abilities to do user research for robotics from anywhere in the world.