While working at NASA in 2003, Dr. Robert Ambrose, director of the Robotics and Automation Design Lab (RAD Lab), designed a robot with no fixed top or bottom. A perfect sphere, the RoboBall could not flip over, and its shape promised access to places wheeled or legged machines could not reach—from the deepest lunar crater to the uneven sands of a beach.
The fastest way to stall an agentic AI project is to reuse a workflow that no longer fits. Using syftr, we identified “silver bullet” flows for both low-latency and high-accuracy priorities that consistently perform well across multiple datasets. These flows outperform random seeding and transfer learning early in optimization. They recover about 75% of the performance of a full syftr run at a fraction of the cost, which makes them a fast starting point but still leaves room to improve.
If you have ever tried to reuse an agentic workflow from one project in another, you know how often it falls flat. The model’s context length might not be enough. The new use case might require deeper reasoning. Or latency requirements might have changed.
Even when the old setup works, it may be overbuilt – and overpriced – for the new problem. In those cases, a simpler, faster setup might be all you need.
We set out to answer a simple question: Are there agentic flows that perform well across many use cases, so you can choose one based on your priorities and move forward?
Our research suggests the answer is yes, and we call them “silver bullets.”
We identified silver bullets for both low-latency and high-accuracy goals. In early optimization, they consistently beat transfer learning and random seeding, while avoiding the full cost of a full syftr run.
In the sections that follow, we explain how we found them and how they stack up against other seeding strategies.
A quick primer on Pareto-frontiers
You don’t need a math degree to follow along, but understanding the Pareto-frontier will make the rest of this post much easier to follow.
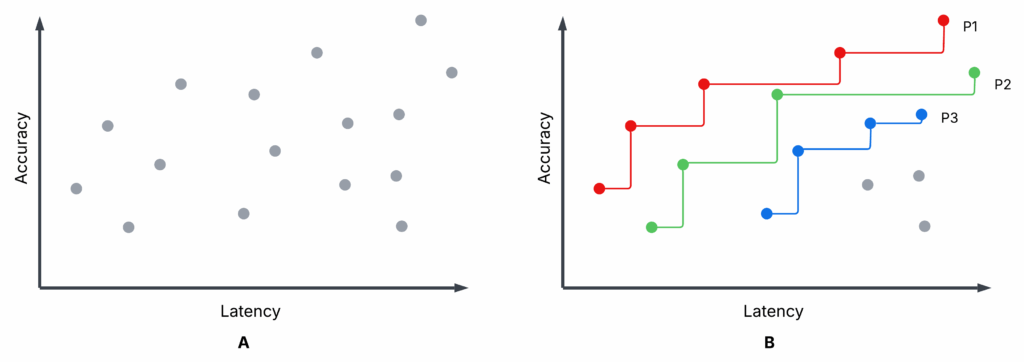
Figure 1 is an illustrative scatter plot – not from our experiments – showing completed syftr optimization trials. Sub-plot A and Sub-plot B are identical, but B highlights the first three Pareto-frontiers: P1 (red), P2 (green), and P3 (blue).
Each trial: A specific flow configuration is evaluated on accuracy and average latency (higher accuracy, lower latency are better).
Pareto-frontier (P1): No other flow has both higher accuracy and lower latency. These are non-dominated.
Non-Pareto flows: At least one Pareto flow beats them on both metrics. These are dominated.
P2, P3: If you remove P1, P2 becomes the next-best frontier, then P3, and so on.
You might choose between Pareto flows depending on your priorities (e.g., favoring low latency over maximum accuracy), but there’s no reason to choose a dominated flow — there’s always a better option on the frontier.
Optimizing agentic AI flows with syftr
Throughout our experiments, we used syftr to optimize agentic flows for accuracy and latency.
Set objectives such as accuracy and cost, or in this case, accuracy and latency
In short, syftr automates the exploration of flow configurations against your chosen objectives.
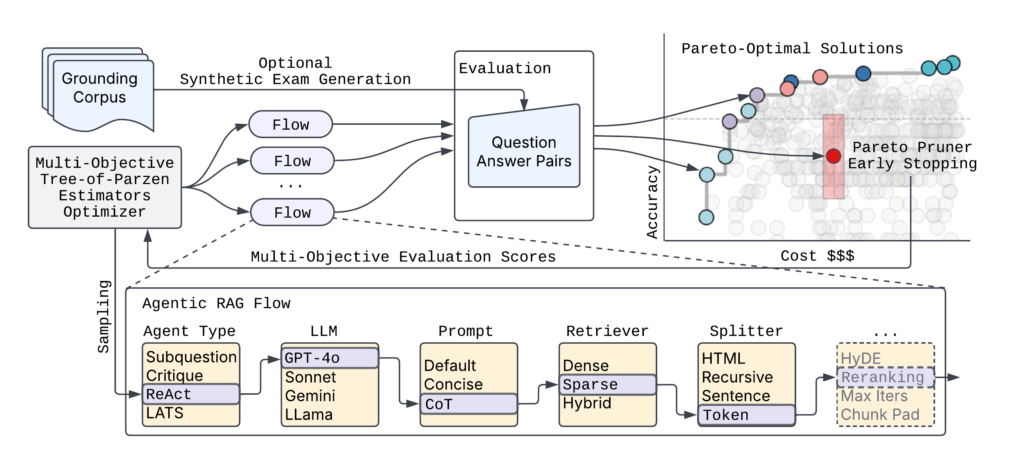
Figure 2 shows the high-level syftr architecture.
Figure 2: High-level syftr architecture. For a set of QA pairs, syftr can automatically explore agentic flows using multi-objective Bayesian optimization by comparing flow responses with actual answers.
Given the practically endless number of possible agentic flow parametrizations, syftr relies on two key techniques:
Multi-objective Bayesian optimization to navigate the search space efficiently.
ParetoPruner to stop evaluation of likely suboptimal flows early, saving time and compute while still surfacing the most effective configurations.
Silver bullet experiments
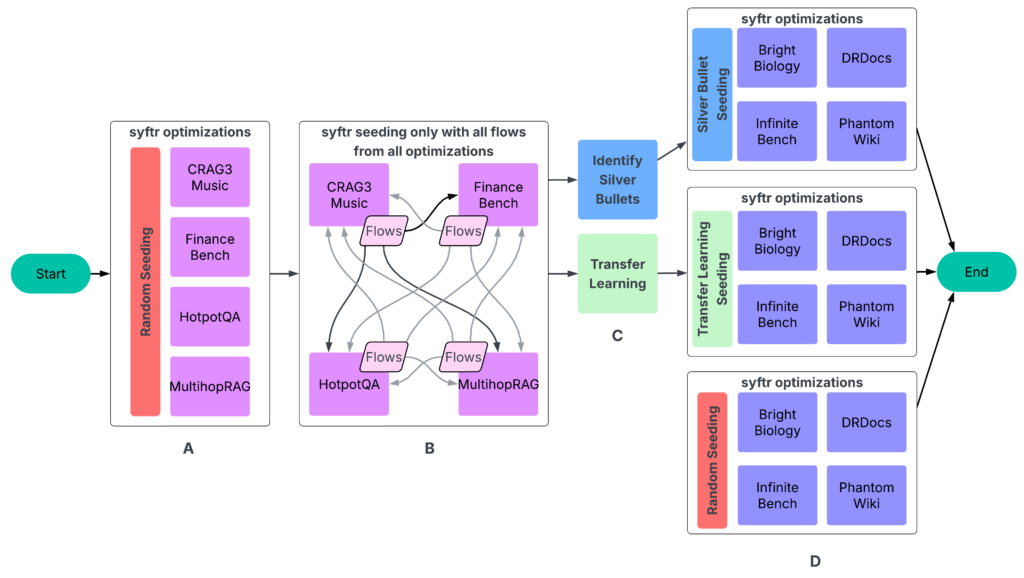
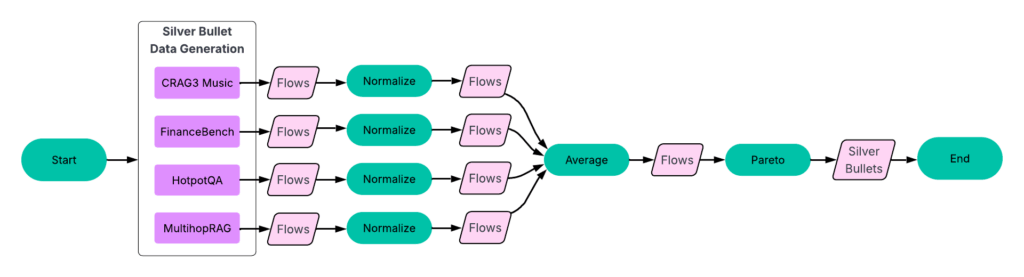
Our experiments followed a four-part process (Figure 3).
Figure 3: The workflow starts with a two-step data generation phase: A: Run syftr using simple random sampling for seeding. B: Run all finished flows on all other experiments. The resulting data then feeds into the next step. C: Identifying silver bullets and conducting transfer learning. D: Running syftr on four held-out datasets three times, using three different seeding strategies.
Step 1: Optimize flows per dataset
We ran several hundred trials on each of the following datasets:
CRAG Task 3 Music
FinanceBench
HotpotQA
MultihopRAG
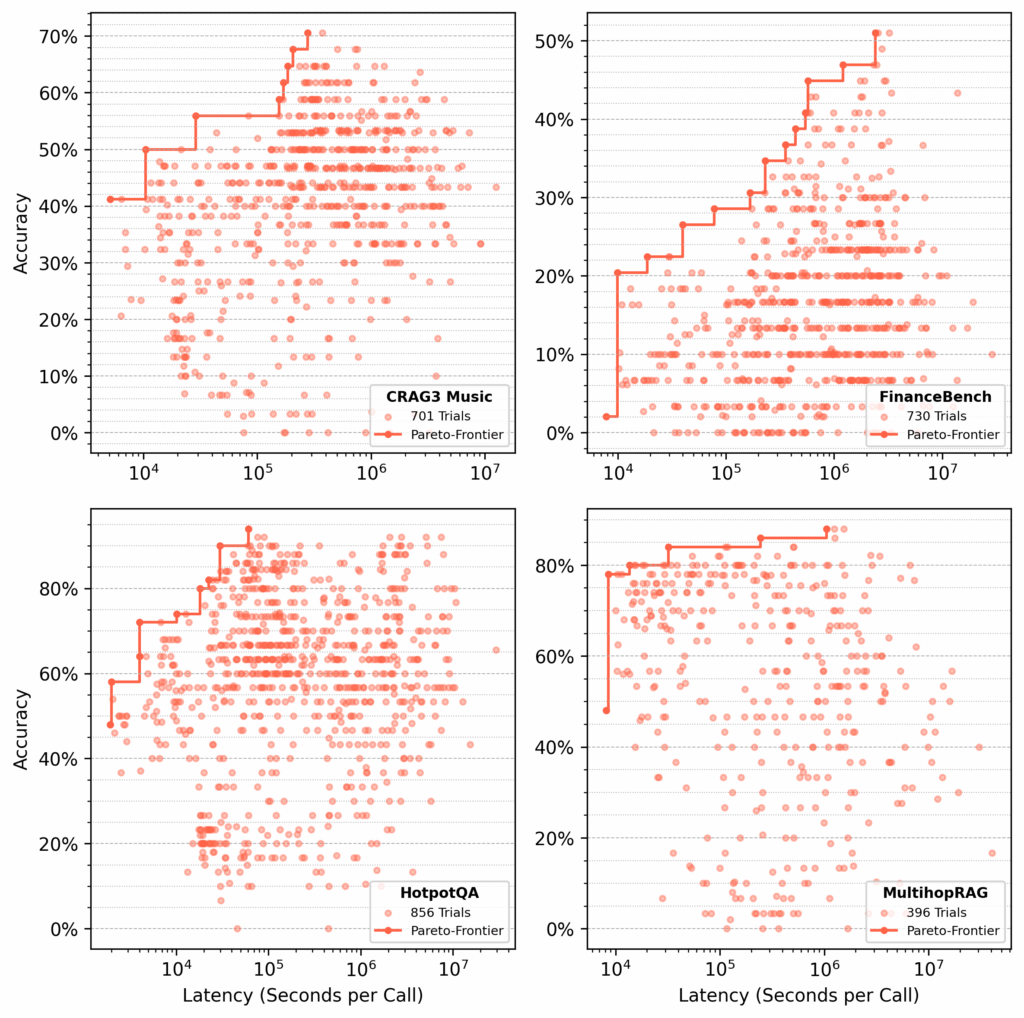
For each dataset, syftr searched for Pareto-optimal flows, optimizing for accuracy and latency (Figure 4).
Figure 4: Optimization results for four datasets. Each dot represents a parameter combination evaluated on 50 QA pairs. Red lines mark Pareto-frontiers with the best accuracy–latency tradeoffs found by the TPE estimator.
Step 3: Identify silver bullets
Once we had identical flows across all training datasets, we could pinpoint the silver bullets — the flows that are Pareto-optimal on average across all datasets.
Figure 5: Silver bullet generation process, detailing the “Identify Silver Bullets” step from Figure 3.
Process:
Normalize results per dataset. For each dataset, we normalize accuracy and latency scores by the highest values in that dataset.
Group identical flows. We then group matching flows across datasets and calculate their average accuracy and latency.
Identify the Pareto-frontier. Using this averaged dataset (see Figure 6), we select the flows that build the Pareto-frontier.
These 23 flows are our silver bullets — the ones that perform well across all training datasets.
Figure 6: Normalized and averaged scores across datasets. The 23 flows on the Pareto-frontier perform well across all training datasets.
Step 4: Seed with transfer learning
In our original syftr paper, we explored transfer learning as a way to seed optimizations. Here, we compared it directly against silver bullet seeding.
In this context, transfer learning simply means selecting specific high-performing flows from historical (training) studies and evaluating them on held-out datasets. The data we use here is the same as for silver bullets (Figure 3).
Process:
Select candidates. From each training dataset, we took the top-performing flows from the top two Pareto-frontiers (P1 and P2).
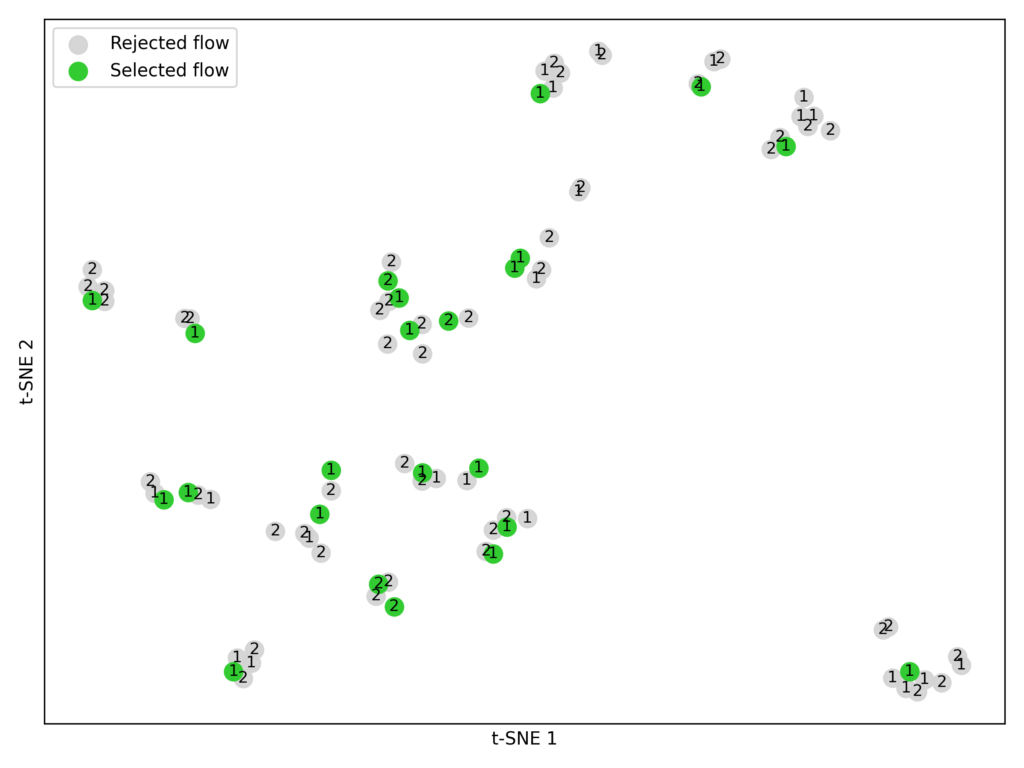
Embed and cluster. Using the embedding model BAAI/bge-large-en-v1.5, we converted each flow’s parameters into numerical vectors. We then applied K-means clustering (K = 23) to group similar flows (Figure 7).
Match experiment constraints. We limited each seeding strategy (silver bullets, transfer learning, random sampling) to 23 flows for a fair comparison, since that’s how many silver bullets we identified.
Note: Transfer learning for seeding isn’t yet fully optimized. We could use more Pareto-frontiers, select more flows, or try different embedding models.
Figure 7: Clustered trials from Pareto-frontiers P1 and P2 across the training datasets.
Step 5: Testing it all
In the final evaluation phase (Step D in Figure 3), we ran ~1,000 optimization trials on four test datasets — Bright Biology, DRDocs, InfiniteBench, and PhantomWiki — repeating the process three times for each of the following seeding strategies:
Silver bullet seeding
Transfer learning seeding
Random sampling
For each trial, GPT-4o-mini served as the judge, verifying an agent’s response against the ground-truth answer.
Results
We set out to answer:
Which seeding approach — random sampling, transfer learning, or silver bullets — delivers the best performance for a new dataset in the fewest trials?
For each of the four held-out test datasets (Bright Biology, DRDocs, InfiniteBench, and PhantomWiki), we plotted:
Accuracy
Latency
Cost
Pareto-area: a measure of how close results are to the optimal result
In each plot, the vertical dotted line marks the point when all seeding trials have completed. After seeding, silver bullets showed on average:
9% higher maximum accuracy
84% lower minimum latency
28% larger Pareto-area
compared to the other strategies.
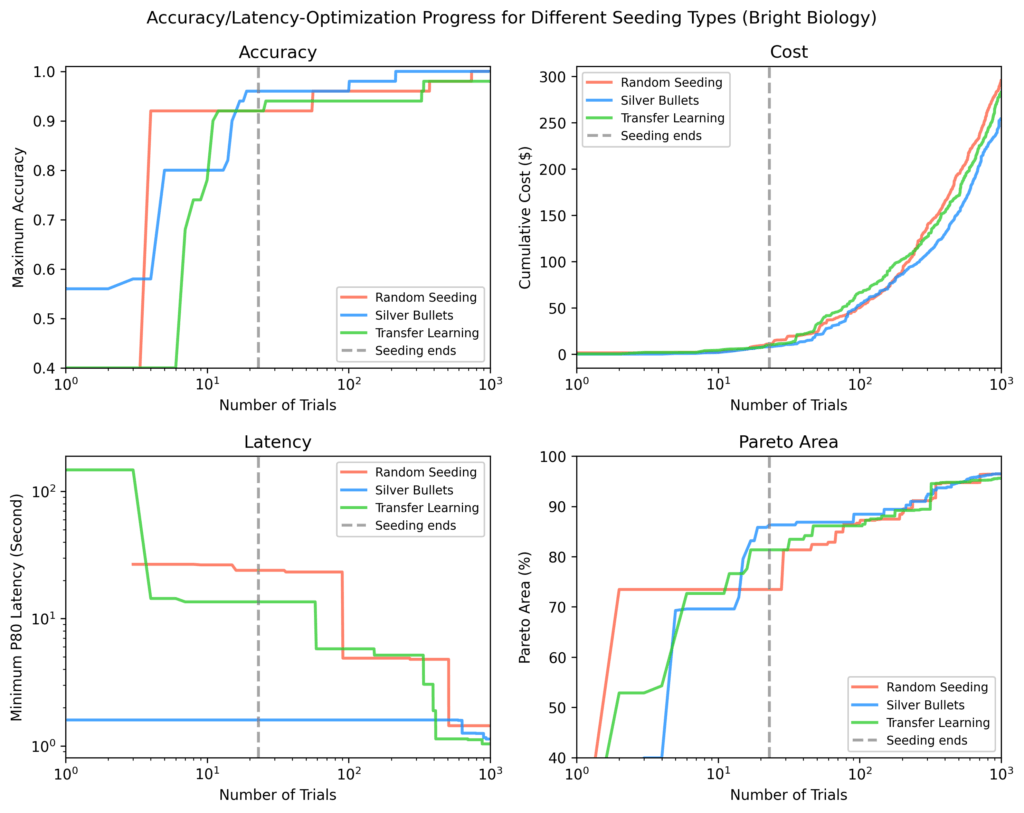
Bright Biology
Silver bullets had the highest accuracy, lowest latency, and largest Pareto-area after seeding. Some random seeding trials did not finish. Pareto-areas for all methods increased over time but narrowed as optimization progressed.
Figure 8: Bright Biology results
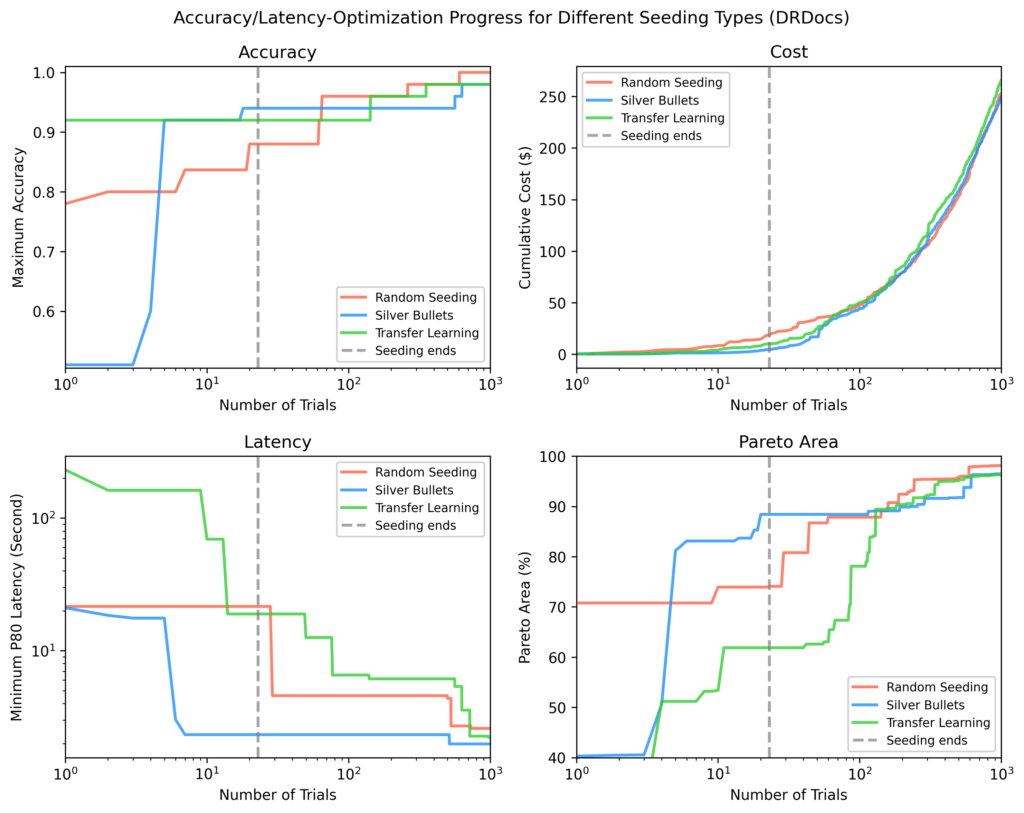
DRDocs
Similar to Bright Biology, silver bullets reached an 88% Pareto-area after seeding vs. 71% (transfer learning) and 62% (random).
Figure 9: DRDocs results
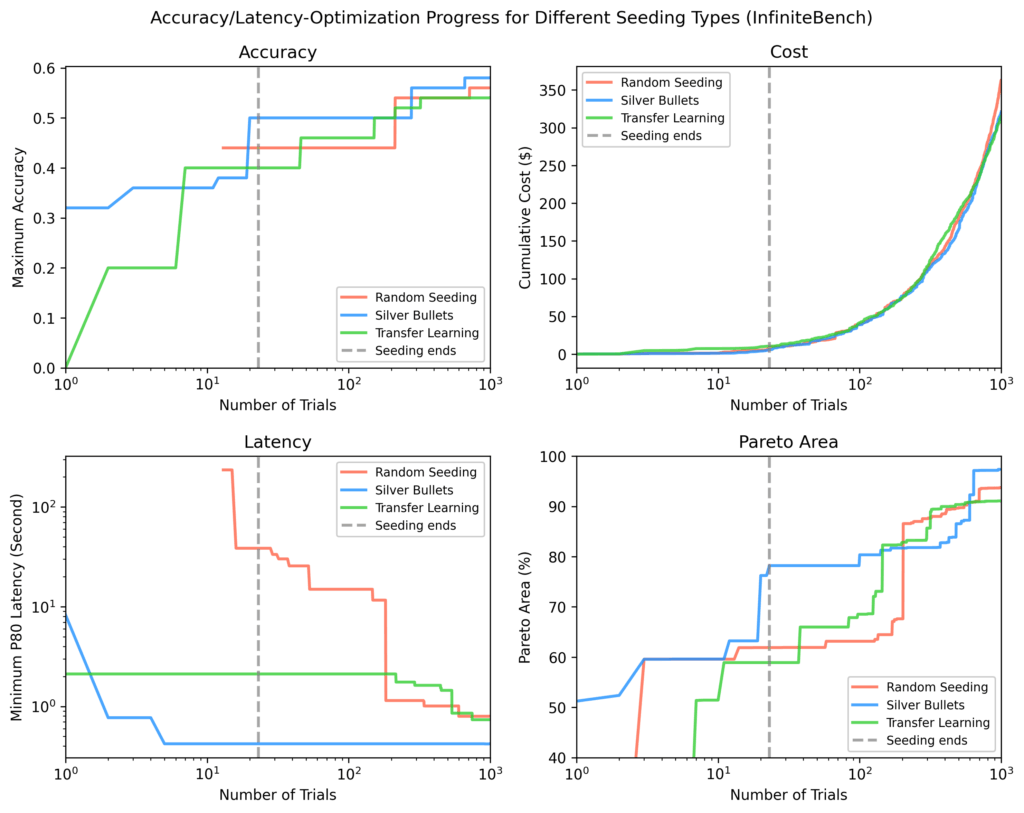
InfiniteBench
Other methods needed ~100 additional trials to match the silver bullet Pareto-area, and still didn’t match the fastest flows found via silver bullets by the end of ~1,000 trials.
Figure 10: InfiniteBench results
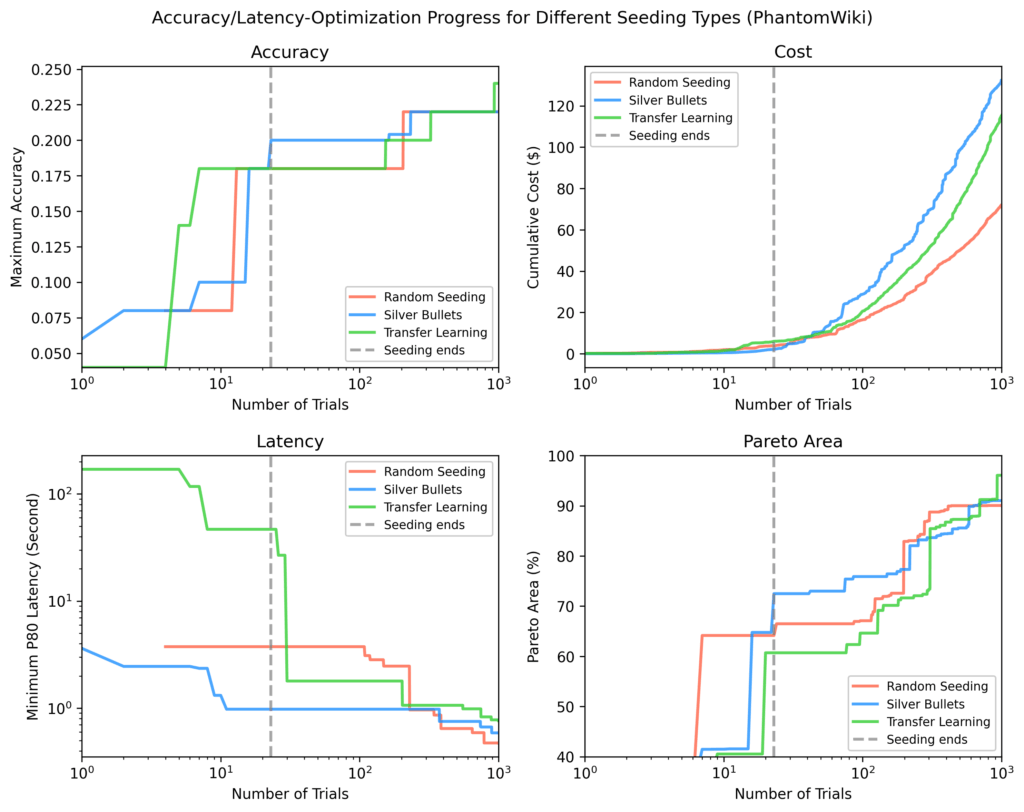
PhantomWiki
Silver bullets again performed best after seeding. This dataset showed the widest cost divergence. After ~70 trials, the silver bullet run briefly focused on more expensive flows.
Figure 11: PhantomWiki results
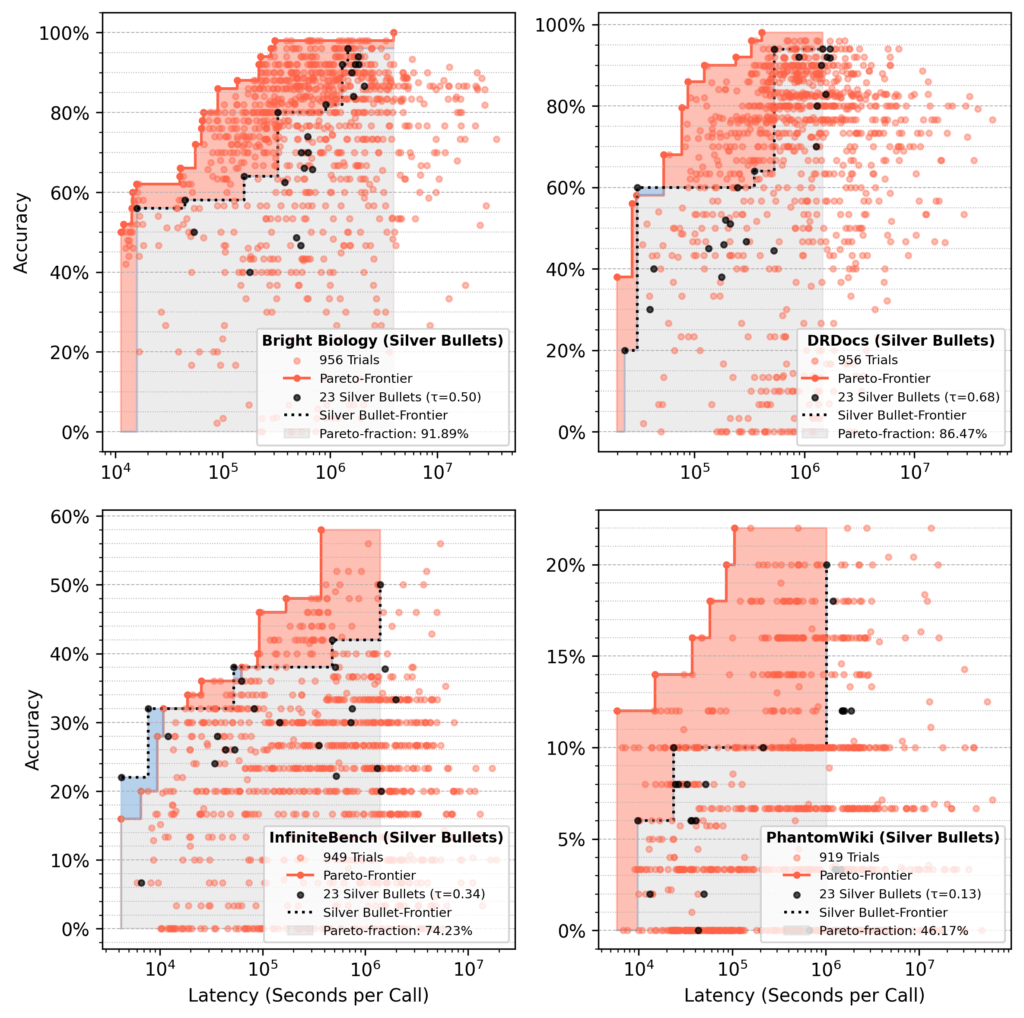
Pareto-fraction analysis
In runs seeded with silver bullets, the 23 silver bullet flows accounted for ~75% of the final Pareto-area after 1,000 trials, on average.
Red area: Gains from optimization over initial silver bullet performance.
Blue area: Silver bullet flows still dominating at the end.
Figure 12: Pareto-fraction for silver bullet seeding across all datasets
Our takeaway
Seeding with silver bullets delivers consistently strong results and even outperforms transfer learning, despite that method pulling from a diverse set of historical Pareto-frontier flows.
For our two objectives (accuracy and latency), silver bullets always start with higher accuracy and lower latency than flows from other strategies.
In the long run, the TPE sampler reduces the initial advantage. Within a few hundred trials, results from all strategies often converge, which is expected since each should eventually find optimal flows.
So, do agentic flows exist that work well across many use cases? Yes — to a point:
On average, a small set of silver bullets recovers about 75% of the Pareto-area from a full optimization.
Performance varies by dataset, such as 92% recovery for Bright Biology compared to 46% for PhantomWiki.
Bottom line: silver bullets are an inexpensive and efficient way to approximate a full syftr run, but they are not a replacement. Their impact could grow with more training datasets or longer training optimizations.
Here’s the full list of all 23 silver bullets, sorted from low accuracy / low latency to high accuracy / high latency: silver_bullets.json.
Try it yourself
Want to experiment with these parametrizations? Use the running_flows.ipynb notebook in our syftr repository — just make sure you have access to the models listed above.
For a deeper dive into syftr’s architecture and parameters, check out our technical paper or explore the codebase.
Nature, particularly humans and other animals, has always been among the primary sources of inspiration for roboticists. In fact, most existing robots physically resemble specific animals and/or are engineered to tackle tasks by emulating the actions, movements and behaviors of specific species.
In high-precision motion control systems like those used in precision manufacturing, the terms "sensor resolution" and "servo bandwidth" are often tossed around interchangeably, sometimes even confused as being functionally synonymous. But they're not.
You might have noticed that humanoid robots are having a bit of a moment. From Tesla's Optimus to Figure AI's Figure 02, these machines are no longer just science fiction—they're walking, and in some cases, cartwheeling into the real world.
In a world where automation is advancing by leaps and bounds, collaboration between robots is no longer science fiction. Imagine a warehouse where dozens of machines transport goods without colliding, a restaurant where robots serve dishes to the correct tables, or a factory where robot teams instantly adjust their tasks according to demand.
The rise of autonomous freight is more than a technological upgrade — it’s a fundamental shift in how goods move around the globe. Robotics innovations are rewriting the rules of efficiency, sustainability and safety.
Most existing robots designed to move on the ground rely on either wheels or legs, as opposed to a combination of the two. Yet robots that can seamlessly switch between wheeled and legged locomotion could be highly advantageous, as they could move more efficiently on a wider range of terrains, which could in turn contribute to the successful completion of missions.
The reason: ChatGPT-maker OpenAI is currently involved in a price war with one of its top competitors – Anthropic – in pricing that’s offered to volume users of AI, computer coders.
Observes Bort: “Some on X called OpenAI’s fees for the model ‘a pricing killer,’ while others on Hacker News are offering similar praise.”
Essentially, many users were turned-off by GPT-5’s initial personality, which was perceived as cold, distant and terse.
Observes writer Will Knight: “The backlash has sparked a fresh debate over the psychological attachments some users form with chatbots trained to push their emotional buttons.”
Observes Willson: “ChatGPT 5 is now one of the most powerful writing tools available, helping authors, bloggers, journalists, and content creators produce better work in less time.
“This model improves accuracy, expands creative depth, and introduces features that make writing easier, faster, and more engaging.”
*ChatGPT-5 Gets High Marks In Creative Writing: The Nerdy Novelist – a YouTube channel that closely tracks AI performance in fiction writing – is generally jazzed about the release of GPT-5.
Specifically, the channel’s testing finds that GPT-5 excels at generating imaginative and detailed prose.
Plus, compared to competitors like Claude 4 and Muse, GPT-5 offers more enhanced creative depth, versatility — as well s the ability to balance function with imagination.
Observes Orland: “Strictly by the numbers, GPT-5 ekes out a victory here, with the preferable response on four prompts to GPT-4o’s three prompts — with one tie.
“But on a majority of the prompts, which response was ‘better’ was more of a judgment call than a clear win.”
Observes writer Suzanne Blake: “AI has quickly shifted from a theoretical concept to a foundational aspect of education and workforce readiness.
“Nearly three-quarters of respondents reported that their schools have established AI usage policies, reflecting how students and institutions are adapting to new realities brought about by rapid technological change.”
*U.S. Federal Government Gets AI Subscriptions for a Buck: In what many consumers hope will be a long and bloody pricing war amidst the AI titans, Anthropic is now offering AI subscriptions to the U.S. federal government for one dollar.
The move comes after ChatGPT-maker OpenAI offered a similar deal to the feds.
One twist, according to writer Aishwarya Panda: “Reportedly, Anthropic is not only targeting the executive branch of the US government, but it will also offer $1 Claude AI subscription to the legislative and judiciary branches.”
Observes David Sharon, a Gemini Apps spokesperson: “To turn your photos into videos, select ‘Videos’ from the tool menu in the prompt box and upload a photo.
“Then, describe the scene and any audio instructions, and watch as your still image transforms into a dynamic video.”
A May 2025 study, for example, found that “Google’s Gemini Pro 2.5 failed at real-world office tasks 70% of the time,” according to writer Chris Taylor.
He adds: “It’s possible that ChatGPT agent will vault to the top of the reliability charts once it’s powered by GPT-5.”
Share a Link: Please consider sharing a link to https://RobotWritersAI.com from your blog, social media post, publication or emails. More links leading to RobotWritersAI.com helps everyone interested in AI-generated writing.
–Joe Dysart is editor of RobotWritersAI.com and a tech journalist with 20+ years experience. His work has appeared in 150+ publications, including The New York Times and the Financial Times of London.
Researchers have unveiled a new quantum material that could make quantum computers much more stable by using magnetism to protect delicate qubits from environmental disturbances. Unlike traditional approaches that rely on rare spin-orbit interactions, this method uses magnetic interactions—common in many materials—to create robust topological excitations. Combined with a new computational tool for finding such materials, this breakthrough could pave the way for practical, disturbance-resistant quantum computers.
The AIhub coffee corner captures the musings of AI experts over a short conversation. This month we tackle the topic of agentic AI. Joining the conversation this time are: Sanmay Das (Virginia Tech), Tom Dietterich (Oregon State University), Sabine Hauert (University of Bristol), Sarit Kraus (Bar-Ilan University), and Michael Littman (Brown University).
Sabine Hauert: Today’s topic is agentic AI. What is it? Why is it taking off? Sanmay, perhaps you could kick off with what you noticed at AAMAS [the Autonomous Agents and Multiagent Systems conference]?
Sanmay Das: It was very interesting because obviously there’s suddenly been an enormous interest in what an agent is and in the development of agentic AI. People in the AAMAS community have been thinking about what an agent is for at least three decades. Well, longer actually, but the community itself dates back about three decades in the form of these conferences. One of the very interesting questions was about why everybody is rediscovering the wheel and rewriting these papers about what it means to be an agent, and how we should think about these agents. The way in which AI has progressed, in the sense that large language models (LLMs) are now the dominant paradigm, is almost entirely different from the way in which people have thought about agents in the AAMAS community. Obviously, there’s been a lot of machine learning and reinforcement learning work, but there’s this historical tradition of thinking about reasoning and logic where you can actually have explicit world models. Even when you’re doing game theory, or MDPs, or their variants, you have an explicit world model that allows you to specify the notion of how to encode agency. Whereas I think that’s part of the disconnect now – everything is a little bit black boxy and statistical. How do you then think about what it means to be an agent? I think in terms of the underlying notion of what it means to be an agent, there’s a lot that can be learnt from what’s been done in the agents community and in philosophy.
I also think that there are some interesting ties to thinking about emergent behaviors, and multi-agent simulation. But it’s a little bit of a Wild West out there and there are all of these papers saying we need to first define what an agent is, which is definitely rediscovering the wheel. So, at AAMAS, there was a lot of discussion of stuff like that, but also questions about what this means in this particular era, because now we suddenly have these really powerful creatures that I think nobody in the AAMAS community saw coming. Fundamentally we need to adapt what we’ve been doing in the community to take into account that these are different from how we thought intelligent agents would emerge into this more general space where they can play. We need to work out how we adapt the kinds of things that we’ve learned about negotiation, agent interaction, and agent intention, to this world. Rada Mihalcea gave a really interesting keynote talk thinking about the natural language processing (NLP) side of things and the questions there.
Sabine: Do you feel like it was a new community joining the AAMAS community, or the AAMAS community that was converting?
Sanmay: Well, there were people who were coming to AAMAS and seeing that the community has been working on this for a long time. So learning something from that was definitely the vibe that I got. But my guess is, if you go to ICML or NeurIPS, that’s very much not the vibe.
Sarit Kraus: I think they’re wasting some time. I mean, forget the “what is an agent?”, but there have been many works from the agent community for many years about coordination, collaboration, etc. I heard about one recent paper where they reinvented Contract Nets. Contract Nets were introduced in 1980, and now there is a paper about it. OK, it’s LLMs that are transferring tasks from one another and signing contracts, but if they just read the past papers, it would save their time and then they could move to more interesting research questions. Currently, they say with LLM agents that you need to divide the task into sub agents. My PhD was about building a Diplomacy player, and in my design of the player there were agents that each played a different part of a Diplomacy play – one was a strategic agent, one was a Foreign Minister, etc. And now they are talking about it again.
Michael Littman: I totally agree with Sanmay and Sarit. The way I think about it is this: this notion of “let’s build agents now that we have LLMs” to me feels a little bit like we have a new programming language like Rust++, or whatever, and we can use it to write programs that we were struggling with before. It’s true that new programming languages can make some things easier, which is great, and LLMs give us a new, powerful way to create AI systems, and that’s also great. But it’s not clear that they solve the challenges that the agents community have been grappling with for so long. So, here’s a concrete example from an article that I read yesterday. Claudius is a version of Claude and it was agentified to run a small online shop. They gave it the ability to communicate with people, post slack messages, order products, set prices on things, and people were actually doing economic exchanges with the system. At the end of the day, it was terrible. Somebody talked it into buying tungsten cubes and selling them in the store. It was just nonsense. The Anthropic people viewed the experiment as a win. They said “ohh yeah, there were definitely problems, but they’re totally fixable”. And the fixes, to me, sounded like all they’d have to do is solve the problems that the agents community has been trying to solve for the last couple of decades. That’s all, and then we’ve got it perfect. And it’s not clear to me at all that just making LLMs generically better, or smarter, or better reasoners suddenly makes all these kinds of agents questions trivial because I don’t think they are. I think they’re hard for a reason and I think you have to grapple with the hard questions to actually solve these problems. But it’s true that LLMs give us a new ability to create a system that can have a conversation. But then the system’s decision-making is just really, really bad. And so I thought that was super interesting. But we agents researchers still have jobs, that’s the good news from all this.
Sabine: My bread and butter is to design agents, in our case robots, that work together to arrive at desired emergent properties and collective behaviors. From this swarm perspective, I feel that over the past 20 years we have learned a lot of the mechanisms by which you reach consensus, the mechanisms by which you automatically design agent behaviours using machine learning to enable groups to achieve a desired collective task. We know how to make agent behaviours understandable, all that good stuff you want in an engineered system. But up until now, we’ve been profoundly lacking the individual agents’ ability to interact with the world in a way that gives you richness. So in my mind, there’s a really nice interface where the agents are more capable, so they can now do those local interactions that make them useful. But we have this whole overarching way to systematically engineer collectives that I think might make the best of both worlds. I don’t know at what point that interface happens. I guess it comes partly from every community going a little bit towards the other side. So from the swarm side, we’re trying visual language models (VLMs), we’re trying to have our robots understand using LLMs their local world to communicate with humans and with each other and get a collective awareness at a very local level of what’s happening. And then we use our swarm paradigms to be able to engineer what they do as a collective using our past research expertise. I imagine for those who are just entering this discipline they need to start from the LLMs and go up. I think it’s part of the process.
Tom Dietterich: I think a lot of it just doesn’t have anything to do with agents at all, you’re writing computer programs. People found that if you try to use a single LLM to do the whole thing, the context gets all messed up and the LLM starts having trouble interpreting it. In fact, these LLMs have a relatively small short-term memory that they can effectively use before they start getting interference among the different things in the buffer. So the engineers break the system into multiple LLM calls and chain them together, and it’s not an agent, it’s just a computer program. I don’t know how many of you have seen this system called DSPy (written by Omar Khattab)? It takes an explicit sort of software engineering perspective on things. Basically, you write a type signature for each LLM module that says “here’s what it’s going to take as input, here’s what it’s going to produce as output”, you build your system, and then DSPy automatically tunes all the prompts as a sort of compiler phase to get the system to do the right thing. I want to question whether building systems with LLMs as a software engineering exercise will branch off from the building of multi-agent systems. Because virtually all the “agentic systems” are not agents in the sense that we would call them that. They don’t have autonomy any more than a regular computer program does.
Sabine: I wonder about the anthropomorphization of this, because now that you have different agents, they’re all doing a task or a job, and all of a sudden you get articles talking about how you can replace a whole team by a set of agents. So we’re no longer replacing individual jobs, we’re now replacing teams and I wonder if this terminology also doesn’t help.
Sanmay: To be clear, this idea has existed at least since the early 90s, when there were these “soft bots” that were basically running Unix commands and they were figuring out what to do themselves. It’s really no different. What people mean when they’re talking about agents is giving a piece of code the opportunity to run its own stuff and to be able to do that in service of some kind of a goal.
I think about this in terms of economic agents, because that’s what I grew up (AKA, did my PhD) thinking about. And, do I want an agent? I could think about writing an agent that manages my (non-existent) stock portfolio. If I had enough money to have a stock portfolio, I might think about writing an agent that manages that portfolio, and that’s a reasonable notion of having autonomy, right? It has some goal, which I set, and then it goes about making decisions. If you think about the sensor-actuator framework, its actuator is that it can make trades and it can take money from my bank account in order to do so. So I think that there’s something in getting back to the basic question of “how does this agent act in the world?” and then what are the percepts that it is receiving?
I completely agree with what you were saying earlier about this question of whether the LLMs enable interactions to happen in different ways. If you look at pre-LLMs, with these agents that were doing pricing, there’s this hilarious story of how some old biology textbook ended up costing $17 million on Amazon because there were these two bots that were doing the pricing of those books at two different used book stores. One of them was a slightly higher-rated store than the other, so it would take whatever price that the lower-rated store had and push it up by 10%. Then the lower-rated store was an undercutter and it would take the current highest price and go to 99% of that price. But this just led to this spiral where suddenly that book cost $17 million. This is exactly the kind of thing that’s going to happen in this world. But the thing that I’m actually somewhat worried about, and anthropomorphising, is how these agents are going to decide on their goals.There’s an opportunity for really bad errors to come out of programming that wouldn’t be as harmful in a more constrained situation.
Tom: In the reinforcement learning literature, of course, there’s all this discussion about reward hacking and so on, but now we imagine two agents interacting with each other and hacking each other’s rewards effectively, so the whole dynamics blows up – people are just not prepared.
Sabine: The breakdown of the problem that Tom mentioned, I think there’s perhaps a real benefit to having these agents that are narrower and that as a result are perhaps more verifiable at the individual level, they maybe have clearer goals, they might be more green because we might be able to constrain what area they operate with. And then in the robotics world, we’ve been looking at collaborative awareness where narrow agents that are task-specific are aware of other agents and collectively they have some awareness of what they’re meant to be doing overall. And it’s quite anti-AGI in the sense that you have lots of narrow agents again. So part of me is wondering, are we going back to heterogeneous task-specific agents and the AGI is collective, perhaps? And so this new wave, maybe it’s anti-AGI – that would be interesting!
Tom: Well, it’s almost the only way we can hope to prove the correctness of the system, to have each component narrow enough that we can actually reason about it. That’s an interesting paradox that I was missing from Stuart Russell’s “What if we succeed?” chapter in his book, which is what if we succeed in building a broad-spectrum agent, how are we going to test it?
It does seem like it would be great to have some people from the agents community speak at the machine learning conferences and try to do some diplomatic outreach. Or maybe run some workshops at those conferences.
Sarit: I was always interested in human-agent interaction and the fact that LLMs have solved the language issue for me, I’m very excited. But the other problem that has been mentioned is still here – you need to integrate strategies and decision-making. So my model is you have LLM agents that have tools that are all sorts of algorithms that we developed and implemented and there should be several of them. But the fact that somebody solved our natural language interaction, I think this is really, really great and good for the agents community as well for the computer science community generally.
Sabine: And good for the humans. It’s a good point, the humans are agents as well in those systems.
When designing new robots, engineers often look to nature for inspiration. They base their robots on the designs and behaviors of snakes, fish, humans, and more, such as sea slugs, whose feeding behaviors have been studied in recent research by the Carnegie Mellon University Biohybrid and Organic Robotics group under the direction of Vickie Webster-Wood, associate professor of mechanical engineering.
A new AI-powered tool created by researchers at Carnegie Mellon University's School of Computer Science could change the way we manufacture and build things.