Emergency-response drones to save lives in the digital skies
Uncrewed aircraft responding to fire and medical emergencies will be used to save lives—if digitalized air-traffic control can help them navigate safely in the skies over Europe.

As part of her role as one of the IEEE ICRA 2022 Science Communication Awardees, Avie Ravendran sat down virtually with a few researchers from academia and industry attending the conference. Curious about what they had to say? Read their quotes below!
“I really believe that learned methods, especially imitation and transfer learning, will enable scalable robot applications in human and unstructured environments We’re on the cusp of seeing robot agents dynamically adapt and solve real world problems”
– Nicholas Nadeau, CTO, Halodi Robotics
“On one hand I think that the interplay of perception and control is quite exciting, in terms of the common underlying principles, while on the other, it’s both cool and inspiring to see more robots getting out of the lab”
– Matías Mattamala, PhD Student, Oxford Dynamic Robot Systems, Oxford Robotics Institute
“I believe that incorporating priors regarding the existing scene geometry and the temporal consistency that’s present in the context of mobile robotics, can be used to guide the learning of more robust representations”
– Kavisha Vidanapathirana, QUT & CSIRORobotics
“At the moment, I am aiming to find out what researchers need in order to take care of their motivation and wellbeing”
– Daniel Carrillo-Zapata, Founder, Scientific Agitation
“We have an immense amount of unsupervised knowledge and we’re always updating our priors. Taking advantage of large-scale unsupervised pretraining and having a lifelong learning system seems like a significant step in the right direction”
– Nitish Dashora, Researcher, Berkeley AI Research & Redwood Center for Theoretical Neuroscience
“When objects are in clutter, with various objects lying on top of one another, the robot needs to interactively and autonomously rearrange the scene in order to retrieve the pose of the target object with minimal number of actions to achieve overall efficiency. I work on pose estimation algorithms to process dense visual data as well as sparse tactile data”
– Prajval Kumar, BMW & University of Glasgow
“Thinking of why the robots or even the structures behave the way they do, and framing and answering questions in that line satisfies my curiosity as a researcher”
– Tung Ta, Postdoctoral Researcher, The University of Tokyo
“I sometimes hear that legged locomotion is a solved problem, but I disagree. I think that the standards of performance have just been raised and collectively we can now tackle more dynamic, efficient and reliable gaits”
– Kevin Green, PhD Candidate, Oregon State University
“My goal in robotics research is to bring down the cost and improve the capabilities of marine research platforms by introducing modularity and underactuation into the field. We’re working on understanding how to bring our collective swimming technology into flowing environments now”
– Gedaliah Knizhnik, PhD Candidate, GRASP Laboratory & The modular robotics laboratory, University of Pennsylvania
“I am interested in how we can develop the algorithms and representations needed to enable long-term autonomous robot navigation without human intervention, such as in the case of an autonomous underwater robot persistently mapping a marine ecosystem for an extended period of time. There are lots of challenges like how can we build a compact representation of the world, ideally grounded in human-understandable semantics? How can we deal gracefully with outliers in perception that inevitably occur in the lifelong setting? and also how can we scale robot state estimation methods in time and space while bounding memory and computation requirements?”
– Kevin Doherty, Computer Science and AI Lab, MIT & Woods Hole Oceanographic Institution
“How can robots learn to interact with and reason about themselves and the world without an intuitive feel for either? Communication is at the heart of biological and robotic systems. Inspired by control theory, information theory, and neuroscience, early work in artificial intelligence (AI) and robotics focused on a class of dynamical system known as feedback systems. These systems are characterized by recurrent mechanisms or feedback loops that govern, regulate, or ‘steer’ the behaviour of the system toward desirable stable states in the presence of disturbance in diverse environments. Feedback between sensation, prediction, decision, action, and back is a critical component of sensorimotor learning needed to realize robust intelligent robotic systems in the wild, a grand challenge of the field. Existing robots are fundamentally numb to the world, limiting their ability to sense themselves and their environment. This problem will only increase as robots grow in complexity, dexterity, and maneuverability, guided by biomimicry. Feedback control systems such as the proportional integral derivative (PID), reinforcement learning (RL), and model predictive control (MPC) are now common in robotics, as is (optimal, Bayesian) Kálmán filtering of point-based IMU-GPS signals. Lacking are the distributed multi-modal, high-dimensional sensations needed to realize general intelligent behaviour, executing complex action sequences through high-level abstractions built up from an intuitive feel or understanding of physics.While the central nervous system and biological neural networks are quantum parallel distributed processing (PDP) engines, most digital artificial neural networks are fully decoupled from sensors and provide only a passive image of the world. We are working to change that by coupling parallel distributed sensing and data processing through a neural paradigm. This involves innovations in hardware, software, and datasets. At Nervosys, we aim to make this dream a reality by building the first nervous system and platform for general robotic intelligence.”
– Adam Erickson, Founder, Nervosys
Accessbility@ICRA2022 and OhmniLabs provided three OhmniBots for the conference, allowing students, faculty and interested industry members to attend the expo and poster sessions. The deployment of telepresence robots was greatly appreciated by everyone, from people with medical conditions or visa issues preventing them from attending, to people who were able to sample a little bit of the conference as an introduction, including future conference organizers.
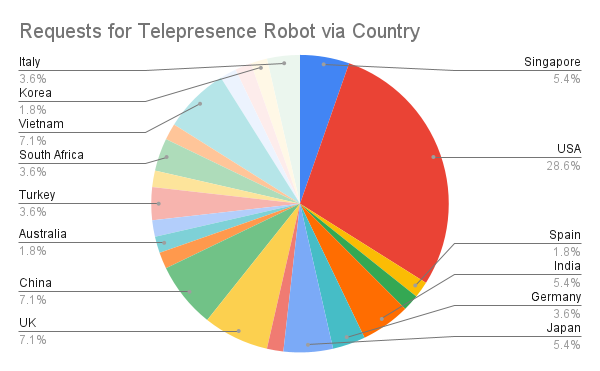
There were more than 60 requests to “Tour ICRA 2022 via Telepresence Robots” from as far away as Africa, India, Asia Pacific, Australia and Europe, as well as across the USA. 24.6% of requests came from interested industry people, with an additional 1.8% from the investment community, 1.8% from the media and 5.3% was interest from the general public.
ICRA 2022 General Chair George Pappas commented that “The telepresence robots were a big hit! It added a very nice innovation and was discussed very positively on social media, particularly from registrants that could not make it.”
Thuc Vu, the CEO of OhmniLabs, the company that provided ICRA with telepresence robots, was delighted to see a conference that was taking a meaningful step for people with accessibility issues. OhmniLabs provide telepresence robots for hospitals and schools as well as for manufacturing or workplace settings and have seen first hand the difference that having a physical ‘body’ and the ability to move around makes in the experience, compared to a video call.
One ICRA researcher presented their poster session via robot, and several faculty who couldn’t attend in person were able to be there for their student’s poster sessions. 12.5% of the requests for telepresence robots came from people who had a paper or poster accepted at ICRA but couldn’t travel. PhD Student at The Sydney Institute for Robotics and Intelligent Systems (SIRIS) at Sydney University, Ahalya Ravendran said,
“Did I tell y’all I bot-suit myself for my conference #ICRA2022 poster session? @RobotLaunch was kind enough to allocate a slot for me during my poster session and oh I had a lot of fun touring with the telepresence robot, via @OhmniLabs”
“Hi from Robotic Imaging Team ”

Sabine Hauert, Publicity Chair at ICRA, President of Robohub and Associate Professor of Swarm Engineering at Bristol University was unable to attend ICRA in person due to pregnancy, but she still visited her student’s poster sessions and explored the conference Expo, saying
“That was fun! The height of the telepresence robot is even accurate  Thanks @OhmniLabs, @RobotLaunch and @ieee_ras_icra for making it possible for this very pregnant lady to attend #ICRA2022 remotely. Congrats on the nice work @m_alhafnawi.”
Thanks @OhmniLabs, @RobotLaunch and @ieee_ras_icra for making it possible for this very pregnant lady to attend #ICRA2022 remotely. Congrats on the nice work @m_alhafnawi.”
Sabine’s PhD student Merihan Alhafnawi was delighted,
“Such an amazing surprise having @sabinehauert visit my poster remotely at @ieee_ras_icra! I presented MOSAIX, a swarm of expressive robot Tiles that we designed & built. Work done with Sabine, @DrEdmundHunt, @skadge & Paul O’Dowd. Check out photos from both perspectives #ICRA2022”
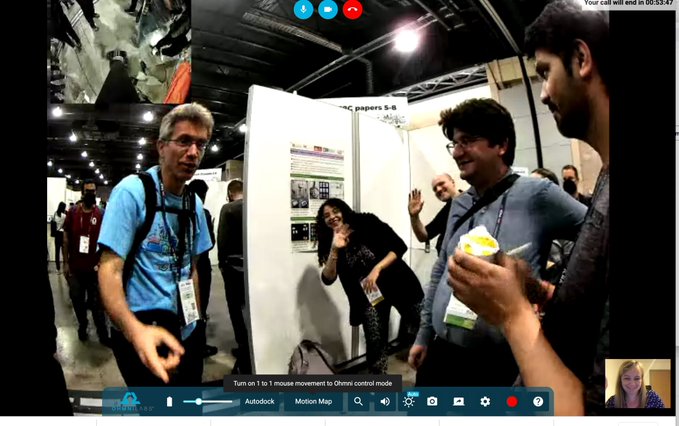
Specially Appointed Assistant Professor at Tohoku University in Japan, Seyed Amir Tafrishi said, “I was lucky to join #icra2022 physically by my avatar robot, where two of our papers will be presented. Thanks to #Ohmnilabs for the fantastic experience with the telepresence robot! It was a great experience to talk with different experts. P.S. Person on the robot’s screen is me! :))”

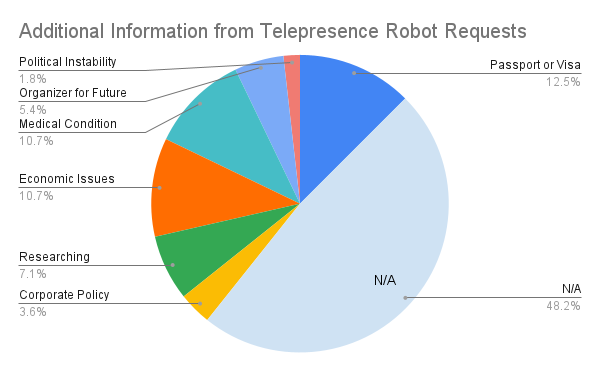
Many people gave us additional information to help us understand why they wanted to access ICRA via telepresence robots, ranging from people stuck in war torn countries, to economic or visa difficulties traveling from some parts of the world. Corporate policy contributed to several people’s inability to attend in person, as sustainably minded companies seek to minimize their carbon impact.

There was also interest from roboticists researching the telepresence experience as well as from future robotics conference organizers. And there were a wide range of medical reasons underpinning the requests for telepresence. Some medical issues are temporary conditions but some roboticists have permanent conditions requiring accessibility support. As telepresence robots become more of the norm, we will be helping to empower researchers who are otherwise isolated from the rest of the community.
Kavita Krishnaswamy is a Google Lime Scholar and Microsoft Research Fellow, with a Ford Foundation Predoctoral and National Science Foundation Graduate Research Fellowship. She is currently a Ph.D. candidate in Computer Science at University of Maryland working with Dr. Tim Oates. Kavita was one of the researchers who was only able to attend ICRA through the use of a telepresence robot, due to her permanent medical conditions.
As a professional researcher with a physical disability, Kavita is highly motivated to develop robotics systems to provide assistance and increase independence for people with disabilities. She is developing prototype robotics systems to support transferring, repositioning and personal care, with a focus on usable interfaces for people with severe disabilities.
Kavita was interviewed by Robohub attending ICRA 2015 via telepresence robot and was excited to hear that IEEE RAS and OhmniLabs are working on making telepresence a permanent conference feature.
https://robohub.org/robotic-assistive-devices-for-independent-living/
And of course, without dedicated volunteers managing the robots and helping visitors maneuver around the conference, we wouldn’t have been able to do anything. Many thanks to everyone who volunteered, the visitors who shared their experiences with us, and to the team at OhmniLabs for their generosity and support.
Interested in getting an Ohmni yourself? Reach out to Ohmni team at sales@ohmnilabs.com.

Links to original tweets or posts used in the report:
https://twitter.com/sabinehauert/status/1529809074338021377
https://twitter.com/m_alhafnawi/status/1529790038246141952
https://twitter.com/girlinrobotics/status/1529282946095804417
https://www.linkedin.com/feed/update/urn:li:activity:6935214535754555392/