The new microbot inspired by starfish larva stirs up plastic beads. (Image: Cornel Dillinger/ETH Zurich)
By Rahel Künzler
Among scientists, there is great interest in tiny machines that are set to revolutionise medicine. These microrobots, often only a fraction of the diameter of a hair, are made to swim through the body to deliver medication to specific areas and perform the smallest surgical procedures.
The designs of these robots are often inspired by natural microorganisms such as bacteria or algae. Now, for the first time, a research group at ETH Zurich has developed a microrobot design inspired by starfish larva, which use ciliary bands on their surface to swim and feed. The ultrasound-activated synthetic system mimics the natural arrangements of starfish ciliary bands and leverages nonlinear acoustics to replicate the larva’s motion and manipulation techniques.
Hairs to push liquid away or suck it in
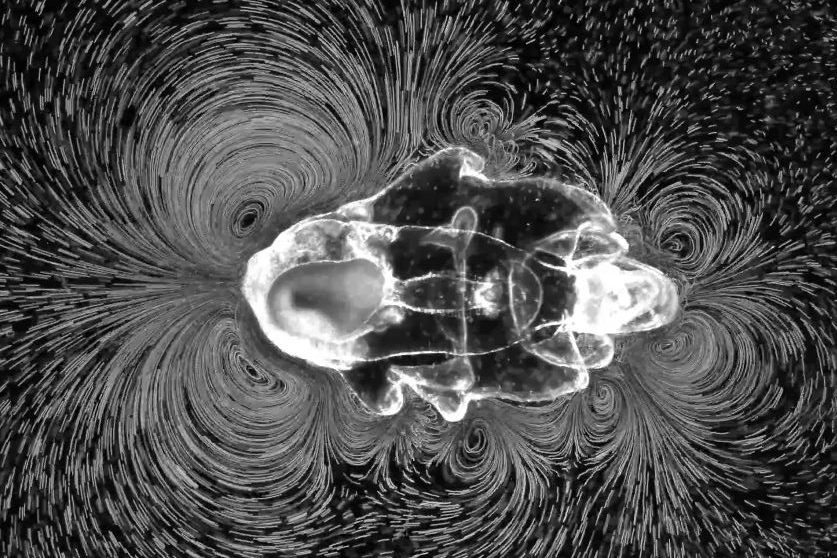
Depending on whether it is swimming or feeding, the starfish larva generates different patterns of vortices. (Image: Prakash Lab, Stanford University)
At first glance, the microrobots bear only scant similarity to starfish larva. In its larval stage, a starfish has a lobed body that measures just a few millimetres across. Meanwhile, the microrobot is a rectangle and ten times smaller, only a quarter of a millimetre across. But the two do share one important feature: a series of fine, movable hairs on the surface, called cilia.
A starfish larva is blanketed with hundreds of thousands of these hairs. Arranged in rows, they beat back and forth in a coordinated fashion, creating eddies in the surrounding water. The relative orientation of two rows determines the end result: Inclining two bands of beating cilia toward each other creates a vortex with a thrust effect, propelling the larva. On the other hand, inclining two bands away from each other creates a vortex that draws liquid in, trapping particles on which the larva feeds.
Artificial swimmers beat faster
These cilia were the key design element for the new microrobot developed by ETH researchers led by Daniel Ahmed, who is a Professor of Acoustic Robotics for life sciences and healthcare. “In the beginning,” Ahmed said, “we simply wanted to test whether we could create vortices similar to those of the starfish larva with rows of cilia inclined toward or away from each other.
To this end, the researchers used photolithography to construct a microrobot with appropriately inclined ciliary bands. They then applied ultrasound waves from an external source to make the cilia oscillate. The synthetic versions beat back and forth more than ten thousand times per second – about a thousand times faster than those of a starfish larva. And as with the larva, these beating cilia can be used to generate a vortex with a suction effect at the front and a vortex with a thrust effect at the rear, the combined effect “rocketing” the robot forward.
Besides swimming, the new microrobot can collect particles and steer them in a predetermined direction. (Video: Cornel Dillinger/ETH Zurich)
In their lab, the researchers showed that the microrobots can swim in a straight line through liquid such as water. Adding tiny plastic beads to the water made it possible to visualize the vortices created by the microrobot. The result is astonishing: both starfish larva and microrobots generate virtually identical flow patterns.
Next, the researchers arranged the ciliary bands so that a suction vortex was positioned next to a thrust vortex, imitating the feeding technique used by starfish larva. This arrangement enabled the robots to collect particles and send them out in a predetermined direction.
Ultrasound offers many advantages
Ahmed is convinced that this new type of microrobot will be ready for use in medicine in the foreseeable future. This is because a system that relies only on ultrasound offers decisive advantages: ultrasound waves are already widely used in imaging, penetrate deep inside the body, and pose no health risks.
“Our vision is to use ultrasound for propulsion, imaging and drug delivery.”
– Daniel Ahmed
The fact that this therapy requires only an ultrasound device makes it cheap, he adds, and hence suitable for use in both developed and developing countries.
Ahmed believes one initial field of application could be the treatment of gastric tumours. Uptake of conventional drugs by diffusion is inefficient, but having microrobots transport a drug specifically to the site of a stomach tumour and then deliver it there might make the drug’s uptake into tumour cells more efficient and reduce side effects.
Sharper images thanks to contrast agents
But before this vision can be realized, a major challenge remains to be overcome: imaging. Steering the tiny machines to the right place requires that a sharp image be generated in real time. The researchers have plans to make the microrobots more visible by incorporating contrast agents such as those already used in medical imaging with ultrasound.
In addition to medical applications, Ahmed anticipates this starfish-inspired design to have important implications for the manipulation of smallest liquid volumes in research and in industry. Bands of beating cilia could execute tasks such as mixing, pumping and particle trapping.

 :
:  : (1 / 10)
: (1 / 10)