Shortening Sales Cycles; A Top Priority for Manufacturers
Trade publications offer significant benefits for manufacturers in need of boosting inbound leads and sales, fast.
By Ben Eysenbach
Nearly all real-world applications of reinforcement learning involve some degree of shift between the training environment and the testing environment. However, prior work has observed that even small shifts in the environment cause most RL algorithms to perform markedly worse. As we aim to scale reinforcement learning algorithms and apply them in the real world, it is increasingly important to learn policies that are robust to changes in the environment.
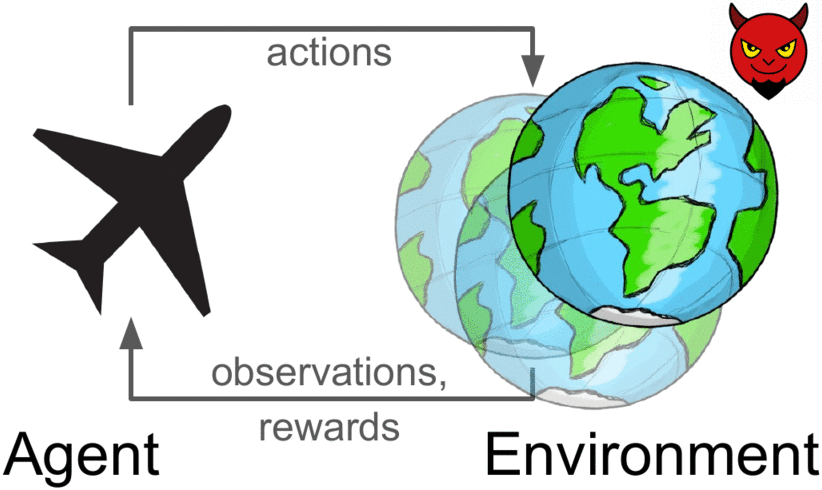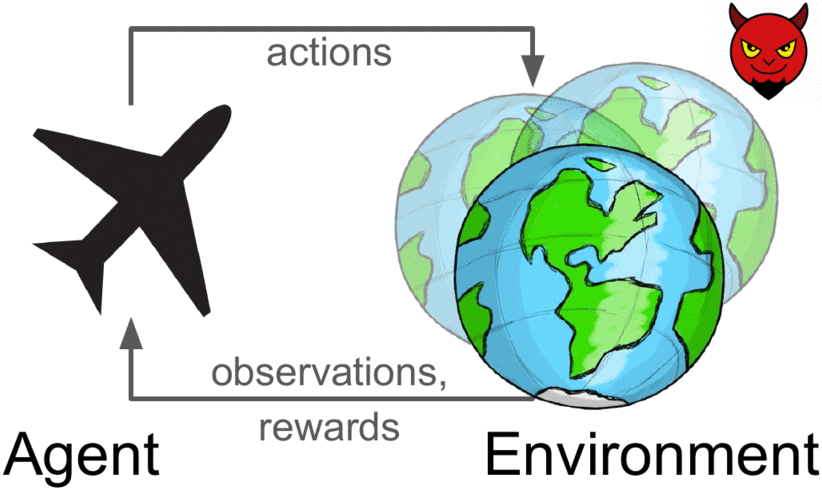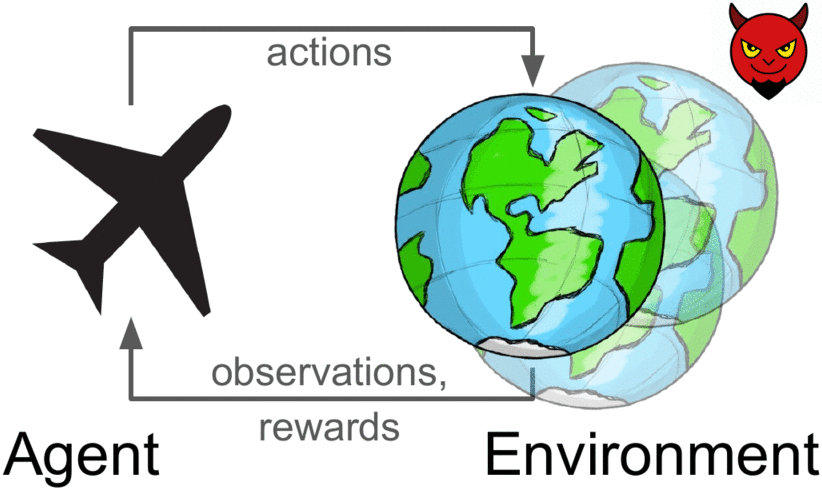
Robust reinforcement learning maximizes reward on an adversarially-chosen environment.
Broadly, prior approaches to handling distribution shift in RL aim to maximize performance in either the average case or the worst case. The first set of approaches, such as domain randomization, train a policy on a distribution of environments, and optimize the average performance of the policy on these environments. While these methods have been successfully applied to a number of areas (e.g., self-driving cars, robot locomotion and manipulation), their success rests critically on the design of the distribution of environments. Moreover, policies that do well on average are not guaranteed to get high reward on every environment. The policy that gets the highest reward on average might get very low reward on a small fraction of environments. The second set of approaches, typically referred to as robust RL, focus on the worst-case scenarios. The aim is to find a policy that gets high reward on every environment within some set. Robust RL can equivalently be viewed as a two-player game between the policy and an environment adversary. The policy tries to get high reward, while the environment adversary tries to tweak the dynamics and reward function of the environment so that the policy gets lower reward. One important property of the robust approach is that, unlike domain randomization, it is invariant to the ratio of easy and hard tasks. Whereas robust RL always evaluates a policy on the most challenging tasks, domain randomization will predict that the policy is better if it is evaluated on a distribution of environments with more easy tasks.
Prior work has suggested a number of algorithms for solving robust RL problems. Generally, these algorithms all follow the same recipe: take an existing RL algorithm and add some additional machinery on top to make it robust. For example, robust value iteration uses Q-learning as the base RL algorithm, and modifies the Bellman update by solving a convex optimization problem in the inner loop of each Bellman backup. Similarly, Pinto ‘17 uses TRPO as the base RL algorithm and periodically updates the environment based on the behavior of the current policy. These prior approaches are often difficult to implement and, even once implemented correctly, they requiring tuning of many additional hyperparameters. Might there be a simpler approach, an approach that does not require additional hyperparameters and additional lines of code to debug?
To answer this question, we are going to focus on a type of RL algorithm known as maximum entropy RL, or MaxEnt RL for short (Todorov ‘06, Rawlik ‘08, Ziebart ‘10). MaxEnt RL is a slight variant of standard RL that aims to learn a policy that gets high reward while acting as randomly as possible; formally, MaxEnt maximizes the entropy of the policy. Some prior work has observed empirically that MaxEnt RL algorithms appear to be robust to some disturbances the environment. To the best of our knowledge, no prior work has actually proven that MaxEnt RL is robust to environmental disturbances.
In a recent paper, we prove that every MaxEnt RL problem corresponds to maximizing a lower bound on a robust RL problem. Thus, when you run MaxEnt RL, you are implicitly solving a robust RL problem. Our analysis provides a theoretically-justified explanation for the empirical robustness of MaxEnt RL, and proves that MaxEnt RL is itself a robust RL algorithm. In the rest of this post, we’ll provide some intuition into why MaxEnt RL should be robust and what sort of perturbations MaxEnt RL is robust to. We’ll also show some experiments demonstrating the robustness of MaxEnt RL.
So, why would we expect MaxEnt RL to be robust to disturbances in the environment? Recall that MaxEnt RL trains policies to not only maximize reward, but to do so while acting as randomly as possible. In essence, the policy itself is injecting as much noise as possible into the environment, so it gets to “practice” recovering from disturbances. Thus, if the change in dynamics appears like just a disturbance in the original environment, our policy has already been trained on such data. Another way of viewing MaxEnt RL is as learning many different ways of solving the task (Kappen ‘05). For example, let’s look at the task shown in videos below: we want the robot to push the white object to the green region. The top two videos show that standard RL always takes the shortest path to the goal, whereas MaxEnt RL takes many different paths to the goal. Now, let’s imagine that we add a new obstacle (red blocks) that wasn’t included during training. As shown in the videos in the bottom row, the policy learned by standard RL almost always collides with the obstacle, rarely reaching the goal. In contrast, the MaxEnt RL policy often chooses routes around the obstacle, continuing to reach the goal for a large fraction of trials.
| Standard RL | MaxEnt RL | |
|
Trained and evaluated without the obstacle: |
|
|
|
Trained without the obstacle, but evaluated with |

|

|
We now formally describe the technical results from the paper. The aim here is not to provide a full proof (see the paper Appendix for that), but instead to build some intuition for what the technical results say. Our main result is that, when you apply MaxEnt RL with some reward function and some dynamics, you are actually maximizing a lower bound on the robust RL objective. To explain this result, we must first define the MaxEnt RL objective: $J_{MaxEnt}(\pi; p, r)$ is the entropy-regularized cumulative return of policy $\pi$ when evaluated using dynamics $p(s’ \mid s, a)$ and reward function $r(s, a)$. While we will train the policy using one dynamics $p$, we will evaluate the policy on a different dynamics, $\tilde{p}(s’ \mid s, a)$, chosen by the adversary. We can now formally state our main result as follows:
The left-hand-side is the robust RL objective. It says that the adversary gets to choose whichever dynamics function $\tilde{p}(s’ \mid s, a)$ makes our policy perform as poorly as possible, subject to some constraints (as specified by the set $\tilde{\mathcal{P}}$). On the right-hand-side we have the MaxEnt RL objective (note that $\log T$ is a constant, and the function $\exp(\cdots)$ is always increasing). Thus, this objective says that a policy that has a high entropy-regularized reward (right hand-side) is guaranteed to also get high reward when evaluated on an adversarially-chosen dynamics.
The most important part of this equation is the set $\tilde{\mathcal{P}}$ of dynamics that the adversary can choose from. Our analysis describes precisely how this set is constructed and shows that, if we want a policy to be robust to a larger set of disturbances, all we have to do is increase the weight on the entropy term and decrease the weight on the reward term. Intuitively, the adversary must choose dynamics that are “close” to the dynamics on which the policy was trained. For example, in the special case where the dynamics are linear-Gaussian, this set corresponds to all perturbations where the original expected next state and the perturbed expected next state have a Euclidean distance less than $\epsilon$.
Our analysis predicts that MaxEnt RL should be robust to many types of disturbances. The first set of videos in this post showed that MaxEnt RL is robust to static obstacles. MaxEnt RL is also robust to dynamic perturbations introduced in the middle of an episode. To demonstrate this, we took the same robotic pushing task and knocked the puck out of place in the middle of the episode. The videos below show that the policy learned by MaxEnt RL is more robust at handling these perturbations, as predicted by our analysis.
|
Standard RL |
MaxEnt RL |

|

|
The policy learned by MaxEntRL is robust to dynamic perturbations of the puck (red frames).
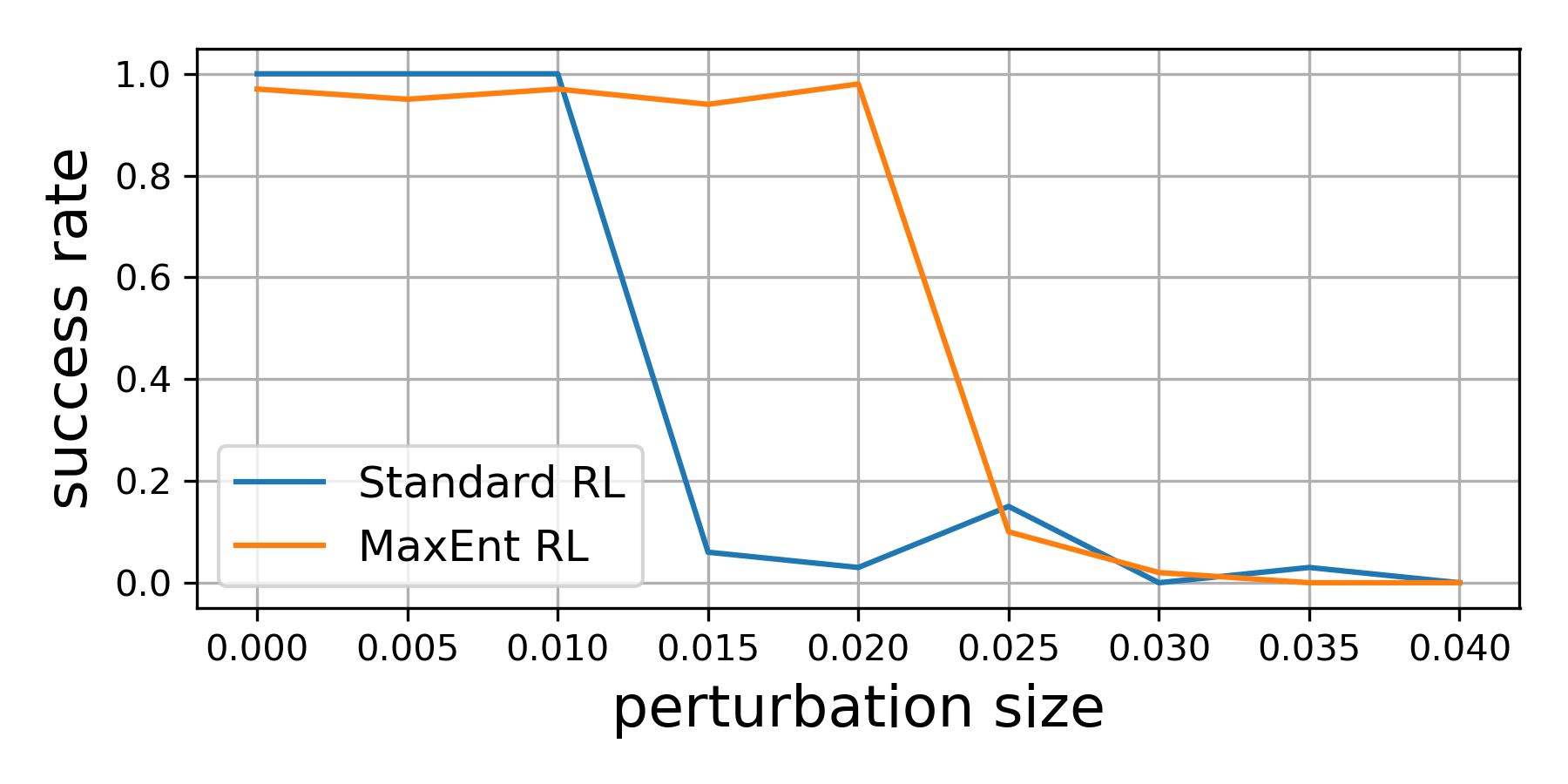
Our theoretical results suggest that, even if we optimize the environment perturbations so the agent does as poorly as possible, MaxEnt RL policies will still be robust. To demonstrate this capability, we trained both standard RL and MaxEnt RL on a peg insertion task shown below. During evaluation, we changed the position of the hole to try to make each policy fail. If we only moved the hole position a little bit ($\le$ 1 cm), both policies always solved the task. However, if we moved the hole position up to 2cm, the policy learned by standard RL almost never succeeded in inserting the peg, while the MaxEnt RL policy succeeded in 95% of trials. This experiment validates our theoretical findings that MaxEnt really is robust to (bounded) adversarial disturbances in the environment.

|

|
|
|
Standard RL |
MaxEnt RL |
Evaluation on adversarial perturbations |
MaxEnt RL is robust to adversarial perturbations of the hole (where the robot
inserts the peg).
In summary, our paper shows that a commonly-used type of RL algorithm, MaxEnt RL, is already solving a robust RL problem. We do not claim that MaxEnt RL will outperform purpose-designed robust RL algorithms. However, the striking simplicity of MaxEnt RL compared with other robust RL algorithms suggests that it may be an appealing alternative to practitioners hoping to equip their RL policies with an ounce of robustness.
Acknowledgements
Thanks to Gokul Swamy, Diba Ghosh, Colin Li, and Sergey Levine for feedback on drafts of this post, and to Chloe Hsu and Daniel Seita for help with the blog.
This post is based on the following paper:


 Research is all about being the first, but commercialization is all about repeatability, not just many times but every single time. This was one of the key takeaways from the Transitioning Research From Academia to Industry panel during the National Robotics Initiative Foundational Research in Robotics PI Meeting on March 10 2021. I had the pleasure of moderating a discussion between Lael Odhner, Co-Founder of RightHand Robotics, Andrea Thomaz, Co-Founder/CEO of Diligent Robotics and Assoc Prof at UTexas Austin, and Kel Guerin, Co-Founder/CIO of READY Robotics.
Research is all about being the first, but commercialization is all about repeatability, not just many times but every single time. This was one of the key takeaways from the Transitioning Research From Academia to Industry panel during the National Robotics Initiative Foundational Research in Robotics PI Meeting on March 10 2021. I had the pleasure of moderating a discussion between Lael Odhner, Co-Founder of RightHand Robotics, Andrea Thomaz, Co-Founder/CEO of Diligent Robotics and Assoc Prof at UTexas Austin, and Kel Guerin, Co-Founder/CIO of READY Robotics.
RightHand Robotics, Diligent Robotics and READY Robotics are young robotics startups that have all transitioned from the ICorps program and SBIR grant funding into becoming venture backed robotics startups. RightHand Robotics was founded in 2014 and is a Boston based company that specializes in robotics manipulation. It is spun out of work performed for the DARPA Autonomous Robotics Manipulation program and has since raised more than $34.3 million from investors that include Maniv Mobility, Playground and Menlo Ventures.
Diligent Robotics is based in Austin where they design and build robots like Moxi that assist clinical staff with routine activities so they can focus on caring for patients. Diligent Robotics is the youngest startup, founded in 2017 and having raised $15.8 million so far from investors that include True Ventures and Ubiquity Ventures. Andrea Thomaz maintains her position at UTexas Austin but has taken leave to focus on Diligent Robotics.
READY Robotics creates unique solutions that remove the barriers faced by small manufacturers when adopting robotic automation. Founded in 2016, and headquartered in Columbus, Ohio, the company has raised more than $41.8 million with investors that include Drive Capital and Canaan Capital. READY Robotics enables manufacturers to more easily deploy robots to the factory floor through a patented technology platform that combines a very easy to use programming interface and plug’n’play hardware. This enables small to medium sized manufacturers to be more competitive through the use of industrial robots.
To summarize the conversation into 8 key takeaways for startups.
And for robotics startups that don’t have immediate access to universities, then robotics clusters can provide similar assistance. From large clusters like RoboValley in Odense, MassRobotics in Boston and Silicon Valley Robotics which have startup programs, space and prototyping equipment, to smaller robotics clusters that can still provide a connection point to other resources.
Research is all about being the first, but commercialization is all about repeatability, not just many times but every single time. This was one of the key takeaways from the Transitioning Research From Academia to Industry panel during the National Robotics Initiative Foundational Research in Robotics PI Meeting on March 10 2021. I had the pleasure of moderating a discussion between Lael Odhner, Co-Founder of RightHand Robotics, Andrea Thomaz, Co-Founder/CEO of Diligent Robotics and Assoc Prof at UTexas Austin, and Kel Guerin, Co-Founder/CIO of READY Robotics.
RightHand Robotics, Diligent Robotics and READY Robotics are young robotics startups that have all transitioned from the ICorps program and SBIR grant funding into becoming venture backed robotics startups. RightHand Robotics was founded in 2014 and is a Boston based company that specializes in robotics manipulation. It is spun out of work performed for the DARPA Autonomous Robotics Manipulation program and has since raised more than $34.3 million from investors that include Maniv Mobility, Playground and Menlo Ventures.
Diligent Robotics is based in Austin where they design and build robots like Moxi that assist clinical staff with routine activities so they can focus on caring for patients. Diligent Robotics is the youngest startup, founded in 2017 and having raised $15.8 million so far from investors that include True Ventures and Ubiquity Ventures. Andrea Thomaz maintains her position at UTexas Austin but has taken leave to focus on Diligent Robotics.
READY Robotics creates unique solutions that remove the barriers faced by small manufacturers when adopting robotic automation. Founded in 2016, and headquartered in Columbus, Ohio, the company has raised more than $41.8 million with investors that include Drive Capital and Canaan Capital. READY Robotics enables manufacturers to more easily deploy robots to the factory floor through a patented technology platform that combines a very easy to use programming interface and plug’n’play hardware. This enables small to medium sized manufacturers to be more competitive through the use of industrial robots.
To summarize the conversation into 8 key takeaways for startups.
And for robotics startups that don’t have immediate access to universities, then robotics clusters can provide similar assistance. From large clusters like RoboValley in Odense, MassRobotics in Boston and Silicon Valley Robotics which have startup programs, space and prototyping equipment, to smaller robotics clusters that can still provide a connection point to other resources.

Abate interviews Tessa Lau on her startup Dusty Robotics which is innovating in the field of construction.
At Dusty Robotics, they developed a robot to automate the laying of floor plans on the floors in construction sites. Typically, this is done manually using a tape measure and reading printed out plans. This difficult task can often take a team of two a week to complete. Time-consuming tasks like this are incredibly expensive on a construction site where multiple different teams are waiting on this task to complete. Any errors in this process are even more time-consuming to fix. By using a robot to automatically convert 3d models of building plans into markings on the floors, the amount of time and errors are dramatically reduced.
Dr. Tessa Lau

Dr. Tessa Lau is an experienced entrepreneur with expertise in AI, machine learning, and robotics. She is currently Founder/CEO at Dusty Robotics, a construction robotics company building robot-powered tools for the modern construction workforce. Prior to Dusty, she was CTO/co-founder at Savioke, where she orchestrated the deployment of 75+ delivery robots into hotels and high-rises. Previously, Dr. Lau was a Research Scientist at Willow Garage, where she developed simple interfaces for personal robots. She also spent 11 years at IBM Research working in business process automation and knowledge capture. More generally, Dr. Lau is interested in technology that gives people super-powers, and building businesses that bring that technology into people’s lives. Dr. Lau was recognized as one of the Top 5 Innovative Women to Watch in Robotics by Inc. in 2018 and one of Fast Company’s Most Creative People in 2015. Dr. Lau holds a PhD in Computer Science from the University of Washington.
Links

The European Commission has published a report by an independent group of experts on Ethics of Connected and Automated Vehicles (CAVs). This report advises on specific ethical issues raised by driverless mobility for road transport. The report aims to promote a safe and responsible transition to connected and automated vehicles by supporting stakeholders in the systematic inclusion of ethical considerations in the development and regulation of CAVs.
The report presents 20 ethical recommendations concerning the future development and use of CAVs based on ethical and legal principles. The recommendations are discussed in the context of three topics areas:
Road Safety, Risk, Dilemmas
Improvements in safety achieved by CAVs should be publicly demonstrable and monitored through solid and shared scientific methods and data; these improvements should be achieved in compliance with basic ethical and legal principles, such as a fair distribution of risk and the protection of basic rights, including those of vulnerable users; these same considerations should apply to dilemma scenarios.
Data and algorithm Ethics: Privacy, Fairness, Explainability
The acquisition and processing of static and dynamic data by CAVs should safeguard basic privacy rights, should not create discrimination between users, and should happen via processes that are accessible and understandable to the subjects involved.
Responsibility
Considering who should be liable for paying compensation following a collision is not sufficient; it is also important to make different stakeholders willing, able and motivated to take responsibility for preventing undesirable outcomes and promoting societally beneficial outcomes of CAVs, that is creating a culture of responsibility for CAVs.
Read the full report.

In the last online technical talk, Adam Bry and Hayk Martiros from Skydio explained how their company tackles real-world issues when it comes to drone flying.
Skydio is the leading US drone company and the world leader in autonomous flight. Our drones are used for everything from capturing amazing video, to inspecting bridges, to tracking progress on construction sites. At the core of our products is a vision-based autonomy system with seven years of development at Skydio, drawing on decades of academic research. This system pushes the state of the art in deep learning, geometric computer vision, motion planning, and control with a particular focus on real-world robustness. Drones encounter extreme visual scenarios not typically considered by academia nor encountered by cars, ground robots, or AR applications. They are commonly flown in scenes with few or no semantic priors and must deftly navigate thin objects, extreme lighting, camera artifacts, motion blur, textureless surfaces, vibrations, dirt, camera smudges, and fog. These challenges are daunting for classical vision – because photometric signals are simply not consistent and for learning-based methods – because there is no ground truth for direct supervision of deep networks. In this talk we’ll take a detailed look at these issues and the algorithms we’ve developed to tackle them. We will also cover the new capabilities on top of our core navigation engine to autonomously map complex scenes and capture all surfaces, by performing real-time 3D reconstruction across multiple flights.
Adam is co-founder and CEO at Skydio. He has two decades of experience with small UAS, starting as a national champion R/C airplane aerobatics pilot. As a grad student at MIT, he did award winning research that pioneered autonomous flight for drones, transferring much of what he learned as an R/C pilot into software that enables drones to fly themselves. Adam co-founded Google’s drone delivery project. He currently serves on the FAA’s Drone Advisory Committee. He holds a BS in Mechanical Engineering from Olin College and an SM in Aero/Astro from MIT. He has co-authored numerous technical papers and patents, and was also recognized on MIT’s TR35 list for young innovators.
Hayk was the first engineering hire at Skydio and he leads the autonomy team. He is an experienced roboticist who develops robust approaches to computer vision, deep learning, nonlinear optimization, and motion planning to bring intelligent robots into the mainstream. His team’s state of the art work in UAV visual localization, obstacle avoidance, and navigation of complex scenarios is at the core of every Skydio drone. He also has an interest in systems architecture and symbolic computation. His previous works include novel hexapedal robots, collaboration between robot arms, micro-robot factories, solar panel farms, and self-balancing motorcycles. Hayk is a graduate of Stanford University and Princeton University.
Featuring Guest Panelist: Davide Scaramuzza and Margaritha Chli
The next technical talk is happening this Friday the 12th of March at 3pm EST. Join Chad Jenkins from the University of Michigan in his talk ‘That Ain’t Right: AI Mistakes and Black Lives’ using this link.

By Terri Park | MIT Schwarzman College of Computing
Traditional computer scientists and engineers are trained to develop solutions for specific needs, but aren’t always trained to consider their broader implications. Each new technology generation, and particularly the rise of artificial intelligence, leads to new kinds of systems, new ways of creating tools, and new forms of data, for which norms, rules, and laws frequently have yet to catch up. The kinds of impact that such innovations have in the world has often not been apparent until many years later.
As part of the efforts in Social and Ethical Responsibilities of Computing (SERC) within the MIT Stephen A. Schwarzman College of Computing, a new case studies series examines social, ethical, and policy challenges of present-day efforts in computing with the aim of facilitating the development of responsible “habits of mind and action” for those who create and deploy computing technologies.
“Advances in computing have undeniably changed much of how we live and work. Understanding and incorporating broader social context is becoming ever more critical,” says Daniel Huttenlocher, dean of the MIT Schwarzman College of Computing. “This case study series is designed to be a basis for discussions in the classroom and beyond, regarding social, ethical, economic, and other implications so that students and researchers can pursue the development of technology across domains in a holistic manner that addresses these important issues.”
By design, the case studies are brief and modular to allow users to mix and match the content to fit a variety of pedagogical needs. Series editors David Kaiser and Julie Shah, who are the associate deans for SERC, structured the cases primarily to be appropriate for undergraduate instruction across a range of classes and fields of study.
“Our goal was to provide a seamless way for instructors to integrate cases into an existing course or cluster several cases together to support a broader module within a course. They might also use the cases as a starting point to design new courses that focus squarely on themes of social and ethical responsibilities of computing,” says Kaiser, the Germeshausen Professor of the History of Science and professor of physics.
Shah, an associate professor of aeronautics and astronautics and a roboticist who designs systems in which humans and machines operate side by side, expects that the cases will also be of interest to those outside of academia, including computing professionals, policy specialists, and general readers. In curating the series, Shah says that “we interpret ‘social and ethical responsibilities of computing’ broadly to focus on perspectives of people who are affected by various technologies, as well as focus on perspectives of designers and engineers.”
The cases are not limited to a particular format and can take shape in various forms — from a magazine-like feature article or Socratic dialogues to choose-your-own-adventure stories or role-playing games grounded in empirical research. Each case study is brief, but includes accompanying notes and references to facilitate more in-depth exploration of a given topic. Multimedia projects will also be considered. “The main goal is to present important material — based on original research — in engaging ways to broad audiences of non-specialists,” says Kaiser.
The SERC case studies are specially commissioned and written by scholars who conduct research centrally on the subject of the piece. Kaiser and Shah approached researchers from within MIT as well as from other academic institutions to bring in a mix of diverse voices on a spectrum of topics. Some cases focus on a particular technology or on trends across platforms, while others assess social, historical, philosophical, legal, and cultural facets that are relevant for thinking critically about current efforts in computing and data sciences.
The cases published in the inaugural issue place readers in various settings that challenge them to consider the social and ethical implications of computing technologies, such as how social media services and surveillance tools are built; the racial disparities that can arise from deploying facial recognition technology in unregulated, real-world settings; the biases of risk prediction algorithms in the criminal justice system; and the politicization of data collection.
“Most of us agree that we want computing to work for social good, but which good? Whose good? Whose needs and values and worldviews are prioritized and whose are overlooked?” says Catherine D’Ignazio, an assistant professor of urban science and planning and director of the Data + Feminism Lab at MIT.
D’Ignazio’s case for the series, co-authored with Lauren Klein, an associate professor in the English and Quantitative Theory and Methods departments at Emory University, introduces readers to the idea that while data are useful, they are not always neutral. “These case studies help us understand the unequal histories that shape our technological systems as well as study their disparate outcomes and effects. They are an exciting step towards holistic, sociotechnical thinking and making.”
Kaiser and Shah formed an editorial board composed of 55 faculty members and senior researchers associated with 19 departments, labs, and centers at MIT, and instituted a rigorous peer-review policy model commonly adopted by specialized journals. Members of the editorial board will also help commission topics for new cases and help identify authors for a given topic.
For each submission, the series editors collect four to six peer reviews, with reviewers mostly drawn from the editorial board. For each case, half the reviewers come from fields in computing and data sciences and half from fields in the humanities, arts, and social sciences, to ensure balance of topics and presentation within a given case study and across the series.
“Over the past two decades I’ve become a bit jaded when it comes to the academic review process, and so I was particularly heartened to see such care and thought put into all of the reviews,” says Hany Farid, a professor at the University of California at Berkeley with a joint appointment in the Department of Electrical Engineering and Computer Sciences and the School of Information. “The constructive review process made our case study significantly stronger.”
Farid’s case, “The Dangers of Risk Prediction in the Criminal Justice System,” which he penned with Julia Dressel, recently a student of computer science at Dartmouth College, is one of the four commissioned pieces featured in the inaugural issue.
Cases are additionally reviewed by undergraduate volunteers, who help the series editors gauge each submission for balance, accessibility for students in multiple fields of study, and possibilities for adoption in specific courses. The students also work with them to create original homework problems and active learning projects to accompany each case study, to further facilitate adoption of the original materials across a range of existing undergraduate subjects.
“I volunteered to work with this group because I believe that it’s incredibly important for those working in computer science to include thinking about ethics not as an afterthought, but integrated into every step and decision that is made, says Annie Snyder, a mathematical economics sophomore and a member of the MIT Schwarzman College of Computing’s Undergraduate Advisory Group. “While this is a massive issue to take on, this project is an amazing opportunity to start building an ethical culture amongst the incredibly talented students at MIT who will hopefully carry it forward into their own projects and workplace.”
New sets of case studies, produced with support from the MIT Press’ Open Publishing Services program, will be published twice a year via the Knowledge Futures Group’s PubPub platform. The SERC case studies are made available for free on an open-access basis, under Creative Commons licensing terms. Authors retain copyright, enabling them to reuse and republish their work in more specialized scholarly publications.
“It was important to us to approach this project in an inclusive way and lower the barrier for people to be able to access this content. These are complex issues that we need to deal with, and we hope that by making the cases widely available, more people will engage in social and ethical considerations as they’re studying and developing computing technologies,” says Shah.