Automation of the oil and gas industry has been slow, but we seem to be standing on the brink of a revolution in this niche. All eyes are now turned to the first fully automated robot starting its work in the North Sea and heralding a major change.
Over the past 30 years, researchers have studied actuating materials that can reversibly change their volume under various stimuli in order to develop micro- and biomimetic robots, artificial muscles and medical devices.
The NEW Collaborative Robot Vacuum Tool (CRVT) from Bimba adds unparalleled flexibility to your collaborative robot. The standard CRVT is highly configurable to meet your application needs, but simple to install and operate. This fully integrated tool means all you need to supply is compressed air and a signal to control the valve. A variety of standard and custom options make the Bimba CRVT the perfect tool for your next collaborative robot project.
A research team of Seoul National University has developed a skin-like electronic system that is soft, thin, lightweight and can wirelessly activate soft robots through a simple lamination process.
In this episode of Robots in Depth, Per Sjöborg speaks with Anouk Wipprecht, a Dutch FashionTech Designer who incorporates technology and robotics into fashion. She thinks that “Fashion lacks Microcontrollers”.
Anouk creates instinctual and behavioral wearables; essentially clothes that can sense, process and react. She creates dresses that move, including motors and special effects. They don´t follow the normal fashion cycle of becoming irrelevant after six months, since they can be updated, improved, and interacted with.
She is a big supporter of open source and is contributing an open source unicorn horn + cam design for children with ADHD amongst other things that she publishes on Instructables.com or Hackster.io.
In this episode of Robots in Depth, Per Sjöborg speaks with Anouk Wipprecht, a Dutch FashionTech Designer who incorporates technology and robotics into fashion. She thinks that “Fashion lacks Microcontrollers”.
Anouk creates instinctual and behavioral wearables; essentially clothes that can sense, process and react. She creates dresses that move, including motors and special effects. They don´t follow the normal fashion cycle of becoming irrelevant after six months, since they can be updated, improved, and interacted with.
She is a big supporter of open source and is contributing an open source unicorn horn + cam design for children with ADHD amongst other things that she publishes on Instructables.com or Hackster.io.
TL;DR, we released the largest and most diverse driving video dataset with richannotations called BDD100K. You can access the data for research now at http://bdd-data.berkeley.edu. We haverecently released an arXivreport on it. And there is still time to participate in our CVPR 2018 challenges!
Large-scale, Diverse, Driving, Video: Pick Four
Autonomous driving is poised to change the life in every community. However,recent events show that it is not clear yet how a man-made perception system canavoid even seemingly obvious mistakes when a driving system is deployed in thereal world. As computer vision researchers, we are interested in exploring thefrontiers of perception algorithms for self-driving to make it safer. To designand test potential algorithms, we would like to make use of all the informationfrom the data collected by a real driving platform. Such data has four majorproperties: it is large-scale, diverse, captured on the street, and withtemporal information. Data diversity is especially important to test therobustness of perception algorithms. However, current open datasets can onlycover a subset of the properties described above. Therefore, with the help of Nexar, we are releasing the BDD100Kdatabase, which is the largest and most diverse open driving video dataset sofar for computer vision research. This project is organized and sponsored by Berkeley DeepDrive IndustryConsortium, which investigates state-of-the-art technologies in computer visionand machine learning for automotive applications.
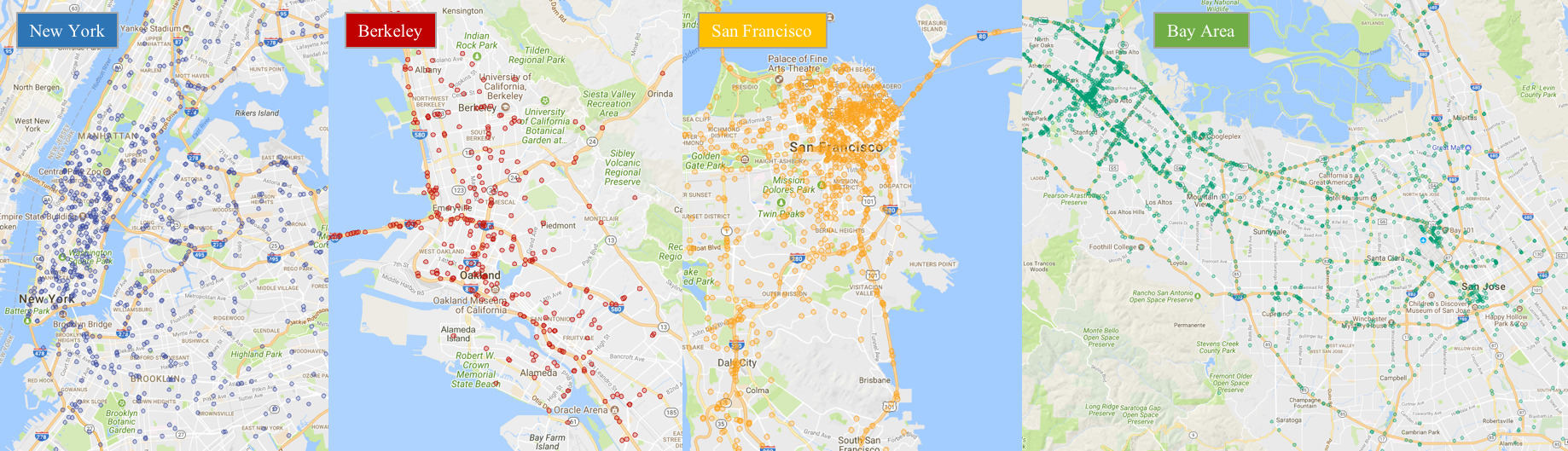
Locations of a random video subset.
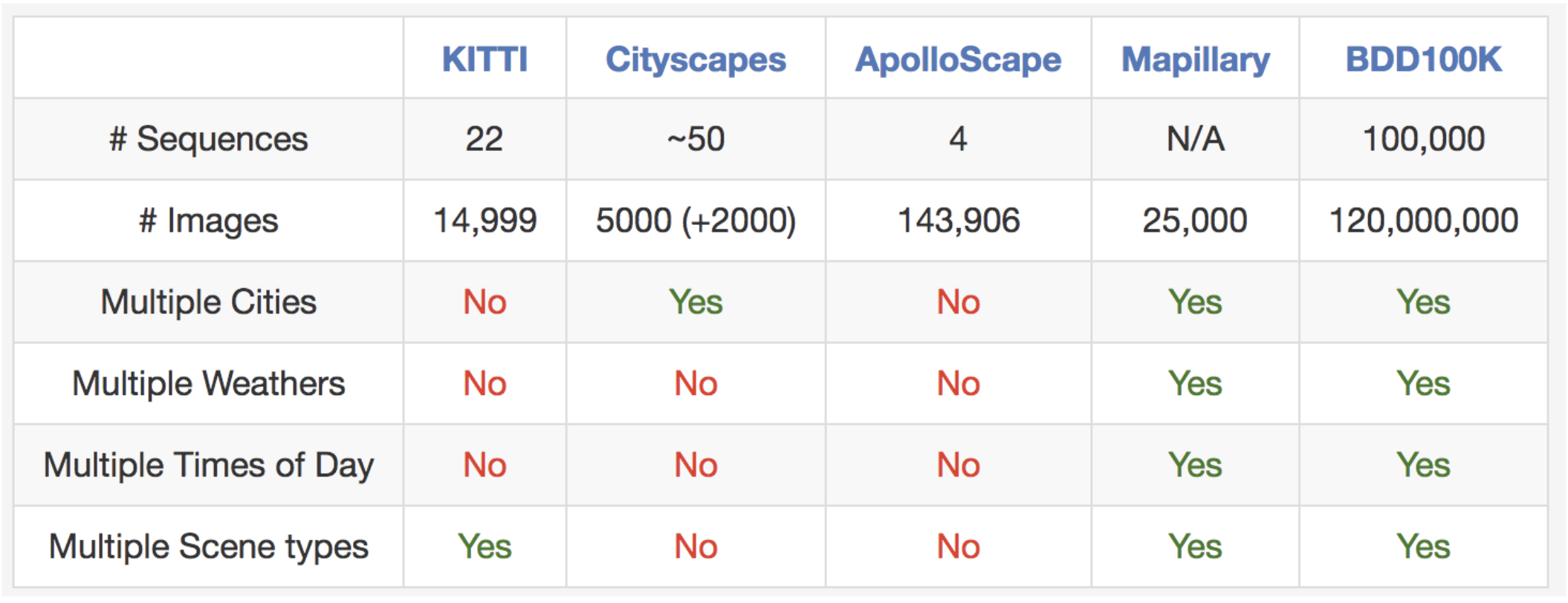
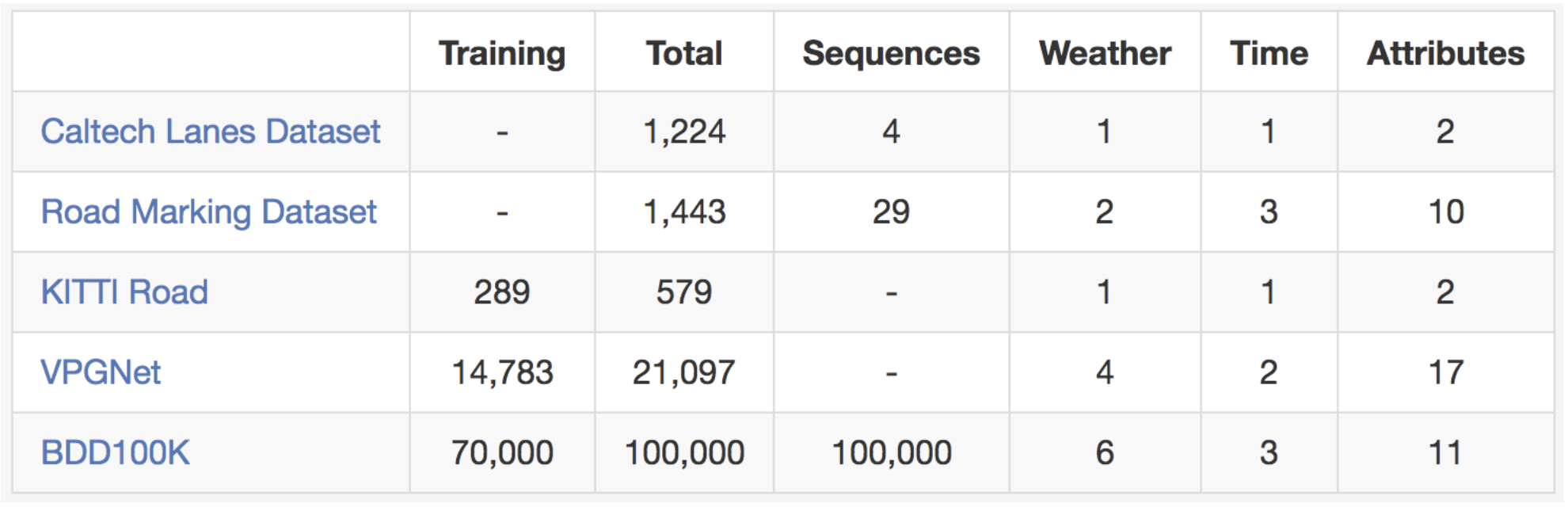
As suggested in the name, our dataset consists of 100,000 videos. Each video isabout 40 seconds long, 720p, and 30 fps. The videos also come with GPS/IMUinformation recorded by cell-phones to show rough driving trajectories. Ourvideos were collected from diverse locations in the United States, as shown inthe figure above. Our database covers different weather conditions, includingsunny, overcast, and rainy, as well as different times of day including daytimeand nighttime. The table below summarizes comparisons with previous datasets,which shows our dataset is much larger and more diverse.
Comparisons with some other street scene datasets. It is hard to fairly compare# images between datasets, but we list them here as a rough reference.
The videos and their trajectories can be useful for imitation learning ofdriving policies, as in our CVPR 2017paper. To facilitate computer vision research on our large-scale dataset, wealso provide basic annotations on the video keyframes, as detailed in the nextsection. You can download the data and annotations now at http://bdd-data.berkeley.edu.
Annotations
We sample a keyframe at the 10th second from each video and provide annotationsfor those keyframes. They are labeled at several levels: image tagging, roadobject bounding boxes, drivable areas, lane markings, and full-frame instancesegmentation. These annotations will help us understand the diversity of thedata and object statistics in different types of scenes. We will discuss thelabeling process in a different blog post. More information about theannotations can be found in our arXivreport.
Overview of our annotations.
Road Object Detection
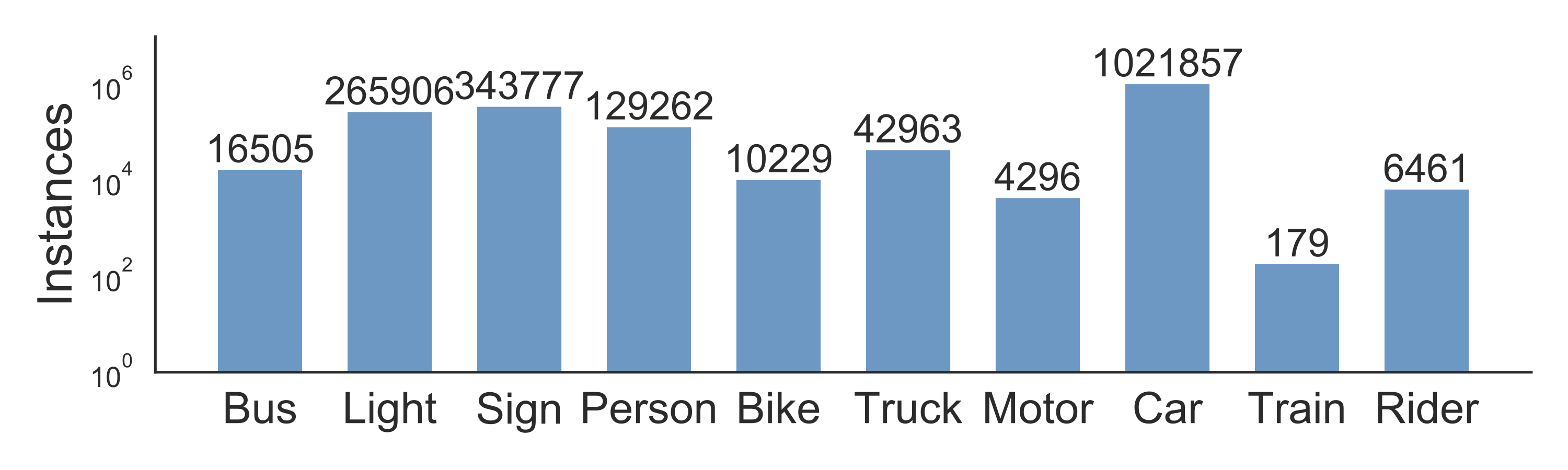
We label object bounding boxes for objects that commonly appear on the road onall of the 100,000 keyframes to understand the distribution of the objects andtheir locations. The bar chart below shows the object counts. There are alsoother ways to play with the statistics in our annotations. For example, we cancompare the object counts under different weather conditions or in differenttypes of scenes. This chart also shows the diverse set of objects that appear inour dataset, and the scale of our dataset – more than 1 million cars. Thereader should be reminded here that those are distinct objects with distinctappearances and contexts.
Statistics of different types of objects.
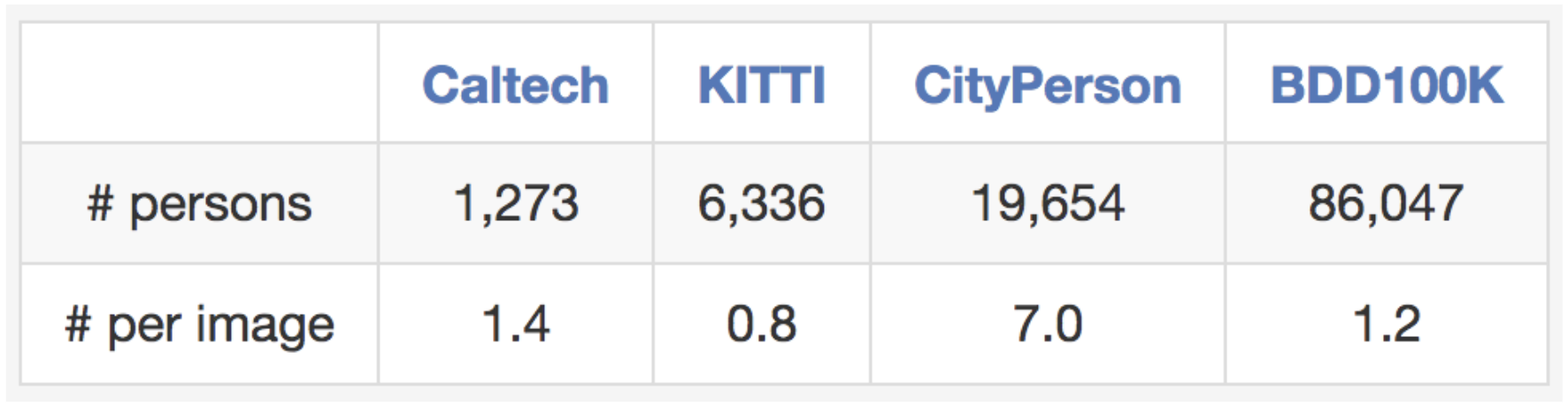
Our dataset is also suitable for studying some particular domains. For example,if you are interested in detecting and avoiding pedestrians on the streets, youalso have a reason to study our dataset since it contains more pedestrianinstances than previous specialized datasets as shown in the table below.
Comparisons with other pedestrian datasets regarding training set size.
Lane Markings
Lane markings are important road instructions for human drivers. They are alsocritical cues of driving direction and localization for the autonomous drivingsystems when GPS or maps does not have accurate global coverage. We divide thelane markings into two types based on how they instruct the vehicles in thelanes. Vertical lane markings (marked in red in the figures below) indicatemarkings that are along the driving direction of their lanes. Parallel lanemarkings (marked in blue in the figures below) indicate those that are for thevehicles in the lanes to stop. We also provide attributes for the markings suchas solid vs. dashed and double vs. single.
If you are ready to try out your lane marking prediction algorithms, please lookno further. Here is the comparison with existing lane marking datasets.
Drivable Areas
Whether we can drive on a road does not only depend on lane markings and trafficdevices. It also depends on the complicated interactions with other objectssharing the road. In the end, it is important to understand which area can bedriven on. To investigate this problem, we also provide segmentation annotationsof drivable areas as shown below. We divide the drivable areas into twocategories based on the trajectories of the ego vehicle: direct drivable, andalternative drivable. Direct drivable, marked in red, means the ego vehicle hasthe road priority and can keep driving in that area. Alternative drivable,marked in blue, means the ego vehicle can drive in the area, but has to becautious since the road priority potentially belongs to other vehicles.
Full-frame Segmentation
It has been shown on Cityscapes dataset that full-frame fine instancesegmentation can greatly bolster research in dense prediction and objectdetection, which are pillars of a wide range of computer vision applications. Asour videos are in a different domain, we provide instance segmentationannotations as well to compare the domain shift relative by different datasets.It can be expensive and laborious to obtain full pixel-level segmentation.Fortunately, with our own labeling tool, the labeling cost could be reduced by50%. In the end, we label a subset of 10K images with full-frame instancesegmentation. Our label set is compatible with the training annotations inCityscapes to make it easier to study domain shift between the datasets.
Driving Challenges
We are hosting threechallenges in CVPR 2018 Workshop on Autonomous Driving based on our data:road object detection, drivable area prediction, and domain adaptation ofsemantic segmentation. The detection task requires your algorithm to find all ofthe target objects in our testing images and drivable area prediction requiressegmenting the areas a car can drive in. In domain adaptation, the testing datais collected in China. Systems are thus challenged to get models learned in theUS to work in the crowded streets in Beijing, China. You can submit your resultsnow after logging in ouronline submission portal. Make sure to check out our toolkit to jump start yourparticipation.
Join our CVPR workshop challenges to claim your cash prizes!!!
Future Work
The perception system for self-driving is by no means only about monocularvideos. It may also include panorama and stereo videos as well as other typesof sensors like LiDAR and radar. We hope to provide and study thosemulti-modality sensor data as well in the near future.
TL;DR, we released the largest and most diverse driving video dataset with richannotations called BDD100K. You can access the data for research now at http://bdd-data.berkeley.edu. We haverecently released an arXivreport on it. And there is still time to participate in our CVPR 2018 challenges!
Large-scale, Diverse, Driving, Video: Pick Four
Autonomous driving is poised to change the life in every community. However,recent events show that it is not clear yet how a man-made perception system canavoid even seemingly obvious mistakes when a driving system is deployed in thereal world. As computer vision researchers, we are interested in exploring thefrontiers of perception algorithms for self-driving to make it safer. To designand test potential algorithms, we would like to make use of all the informationfrom the data collected by a real driving platform. Such data has four majorproperties: it is large-scale, diverse, captured on the street, and withtemporal information. Data diversity is especially important to test therobustness of perception algorithms. However, current open datasets can onlycover a subset of the properties described above. Therefore, with the help of Nexar, we are releasing the BDD100Kdatabase, which is the largest and most diverse open driving video dataset sofar for computer vision research. This project is organized and sponsored by Berkeley DeepDrive IndustryConsortium, which investigates state-of-the-art technologies in computer visionand machine learning for automotive applications.
Locations of a random video subset.
As suggested in the name, our dataset consists of 100,000 videos. Each video isabout 40 seconds long, 720p, and 30 fps. The videos also come with GPS/IMUinformation recorded by cell-phones to show rough driving trajectories. Ourvideos were collected from diverse locations in the United States, as shown inthe figure above. Our database covers different weather conditions, includingsunny, overcast, and rainy, as well as different times of day including daytimeand nighttime. The table below summarizes comparisons with previous datasets,which shows our dataset is much larger and more diverse.
Comparisons with some other street scene datasets. It is hard to fairly compare# images between datasets, but we list them here as a rough reference.
The videos and their trajectories can be useful for imitation learning ofdriving policies, as in our CVPR 2017paper. To facilitate computer vision research on our large-scale dataset, wealso provide basic annotations on the video keyframes, as detailed in the nextsection. You can download the data and annotations now at http://bdd-data.berkeley.edu.
Annotations
We sample a keyframe at the 10th second from each video and provide annotationsfor those keyframes. They are labeled at several levels: image tagging, roadobject bounding boxes, drivable areas, lane markings, and full-frame instancesegmentation. These annotations will help us understand the diversity of thedata and object statistics in different types of scenes. We will discuss thelabeling process in a different blog post. More information about theannotations can be found in our arXivreport.
Overview of our annotations.
Road Object Detection
We label object bounding boxes for objects that commonly appear on the road onall of the 100,000 keyframes to understand the distribution of the objects andtheir locations. The bar chart below shows the object counts. There are alsoother ways to play with the statistics in our annotations. For example, we cancompare the object counts under different weather conditions or in differenttypes of scenes. This chart also shows the diverse set of objects that appear inour dataset, and the scale of our dataset – more than 1 million cars. Thereader should be reminded here that those are distinct objects with distinctappearances and contexts.
Statistics of different types of objects.
Our dataset is also suitable for studying some particular domains. For example,if you are interested in detecting and avoiding pedestrians on the streets, youalso have a reason to study our dataset since it contains more pedestrianinstances than previous specialized datasets as shown in the table below.
Comparisons with other pedestrian datasets regarding training set size.
Lane Markings
Lane markings are important road instructions for human drivers. They are alsocritical cues of driving direction and localization for the autonomous drivingsystems when GPS or maps does not have accurate global coverage. We divide thelane markings into two types based on how they instruct the vehicles in thelanes. Vertical lane markings (marked in red in the figures below) indicatemarkings that are along the driving direction of their lanes. Parallel lanemarkings (marked in blue in the figures below) indicate those that are for thevehicles in the lanes to stop. We also provide attributes for the markings suchas solid vs. dashed and double vs. single.
If you are ready to try out your lane marking prediction algorithms, please lookno further. Here is the comparison with existing lane marking datasets.
Drivable Areas
Whether we can drive on a road does not only depend on lane markings and trafficdevices. It also depends on the complicated interactions with other objectssharing the road. In the end, it is important to understand which area can bedriven on. To investigate this problem, we also provide segmentation annotationsof drivable areas as shown below. We divide the drivable areas into twocategories based on the trajectories of the ego vehicle: direct drivable, andalternative drivable. Direct drivable, marked in red, means the ego vehicle hasthe road priority and can keep driving in that area. Alternative drivable,marked in blue, means the ego vehicle can drive in the area, but has to becautious since the road priority potentially belongs to other vehicles.
Full-frame Segmentation
It has been shown on Cityscapes dataset that full-frame fine instancesegmentation can greatly bolster research in dense prediction and objectdetection, which are pillars of a wide range of computer vision applications. Asour videos are in a different domain, we provide instance segmentationannotations as well to compare the domain shift relative by different datasets.It can be expensive and laborious to obtain full pixel-level segmentation.Fortunately, with our own labeling tool, the labeling cost could be reduced by50%. In the end, we label a subset of 10K images with full-frame instancesegmentation. Our label set is compatible with the training annotations inCityscapes to make it easier to study domain shift between the datasets.
Driving Challenges
We are hosting threechallenges in CVPR 2018 Workshop on Autonomous Driving based on our data:road object detection, drivable area prediction, and domain adaptation ofsemantic segmentation. The detection task requires your algorithm to find all ofthe target objects in our testing images and drivable area prediction requiressegmenting the areas a car can drive in. In domain adaptation, the testing datais collected in China. Systems are thus challenged to get models learned in theUS to work in the crowded streets in Beijing, China. You can submit your resultsnow after logging in ouronline submission portal. Make sure to check out our toolkit to jump start yourparticipation.
Join our CVPR workshop challenges to claim your cash prizes!!!
Future Work
The perception system for self-driving is by no means only about monocularvideos. It may also include panorama and stereo videos as well as other typesof sensors like LiDAR and radar. We hope to provide and study thosemulti-modality sensor data as well in the near future.
By Vitchyr Pong
You’ve decided that you want to bike from your house by UC Berkeley to the Golden Gate Bridge. It’s a nice 20 mile ride, but there’s a problem: you’ve never ridden a bike before!To make matters worse, you are new to the Bay Area, and all you have is a good ol’ fashion map to guide you. How do you get started? Let’s first figure out how to ride a bike. One strategy would be to do a lot of studying and planning. Read books on how to ride bicycles. Study physics and anatomy. Plan out all the different muscle movements that you’ll make in response to each perturbation. This approach is noble, but for anyone who’s ever learned to ride a bike, they know that this strategy is doomed to fail. There’s only one way to learn how to ride a bike: trial and error. Some tasks like riding a bike are just too complicated to plan out in your head. Once you’ve learned how to ride your bike, how would you get to the Golden Gate Bridge? You could reuse your trial-and-error strategy. Take a few random turns and see if you end up at the Golden Gate Bridge. Unfortunately, this strategy would take a very, very long time. For this sort of problem, planning is a much faster strategy, and requires considerably less real-world experience and trial-and-error. In reinforcement learning terms, it is more sample-efficient.
Left: some skills you learn by trial and error. Right: other times, planning ahead is better.
While simple, this thought experiment highlights some important aspects of human intelligence. For some tasks, we use a trial-and-error approach, and for others we use a planning approach. A similar phenomena seems to have emerged in reinforcement learning (RL). In the parlance of RL, empirical results show that some tasks are better suited for model-free (trial-and-error) approaches, and others are better suited for model-based (planning) approaches. However, the biking analogy also highlights that the two systems are not completely independent. In particularly, to say that learning to ride a bike is just trial-and-error is an oversimplification. In fact, when learning to bike by trial-and-error, you’ll employ a bit of planning. Perhaps your plan will initially be, “Don’t fall over.” As you improve, you’ll make more ambitious plans, such as, “Bike forwards for two meters without falling over.” Eventually, your bike-riding skills will be so proficient that you can start to plan in very abstract terms (“Bike to the end of the road.”) to the point that all there is left to do is planning and you no longer need to worry about the nitty-gritty details of riding a bike. We see that there is a gradual transition from the model-free (trial-and-error) strategy to a model-based (planning) strategy. If we could develop artificial intelligence algorithms–and specifically RL algorithms–that mimic this behavior, it could result in an algorithm that both performs well (by using trial-and-error methods early on) and is sample efficient (by later switching to a planning approach to achieve more abstract goals). This post covers temporal difference model (TDM), which is a RL algorithm that captures this smooth transition between model-free and model-based RL. Before describing TDMs, we start by first describing how a typical model-based RL algorithm works. Read More
By Vitchyr Pong
You’ve decided that you want to bike from your house by UC Berkeley to the Golden Gate Bridge. It’s a nice 20 mile ride, but there’s a problem: you’ve never ridden a bike before!To make matters worse, you are new to the Bay Area, and all you have is a good ol’ fashion map to guide you. How do you get started? Let’s first figure out how to ride a bike. One strategy would be to do a lot of studying and planning. Read books on how to ride bicycles. Study physics and anatomy. Plan out all the different muscle movements that you’ll make in response to each perturbation. This approach is noble, but for anyone who’s ever learned to ride a bike, they know that this strategy is doomed to fail. There’s only one way to learn how to ride a bike: trial and error. Some tasks like riding a bike are just too complicated to plan out in your head. Once you’ve learned how to ride your bike, how would you get to the Golden Gate Bridge? You could reuse your trial-and-error strategy. Take a few random turns and see if you end up at the Golden Gate Bridge. Unfortunately, this strategy would take a very, very long time. For this sort of problem, planning is a much faster strategy, and requires considerably less real-world experience and trial-and-error. In reinforcement learning terms, it is more sample-efficient.
Left: some skills you learn by trial and error. Right: other times, planning ahead is better.
While simple, this thought experiment highlights some important aspects of human intelligence. For some tasks, we use a trial-and-error approach, and for others we use a planning approach. A similar phenomena seems to have emerged in reinforcement learning (RL). In the parlance of RL, empirical results show that some tasks are better suited for model-free (trial-and-error) approaches, and others are better suited for model-based (planning) approaches. However, the biking analogy also highlights that the two systems are not completely independent. In particularly, to say that learning to ride a bike is just trial-and-error is an oversimplification. In fact, when learning to bike by trial-and-error, you’ll employ a bit of planning. Perhaps your plan will initially be, “Don’t fall over.” As you improve, you’ll make more ambitious plans, such as, “Bike forwards for two meters without falling over.” Eventually, your bike-riding skills will be so proficient that you can start to plan in very abstract terms (“Bike to the end of the road.”) to the point that all there is left to do is planning and you no longer need to worry about the nitty-gritty details of riding a bike. We see that there is a gradual transition from the model-free (trial-and-error) strategy to a model-based (planning) strategy. If we could develop artificial intelligence algorithms–and specifically RL algorithms–that mimic this behavior, it could result in an algorithm that both performs well (by using trial-and-error methods early on) and is sample efficient (by later switching to a planning approach to achieve more abstract goals). This post covers temporal difference model (TDM), which is a RL algorithm that captures this smooth transition between model-free and model-based RL. Before describing TDMs, we start by first describing how a typical model-based RL algorithm works. Read More
A system developed at MIT aims to teach artificial agents a range of chores, including setting the table and making coffee. Image: MIT CSAIL By Adam Conner-Simons | Rachel Gordon
For many people, household chores are a dreaded, inescapable part of life that we often put off or do with little care. But what if a robot assistant could help lighten the load?
Recently, computer scientists have been working on teaching machines to do a wider range of tasks around the house. In a new paper spearheaded by MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) and the University of Toronto, researchers demonstrate “VirtualHome,” a system that can simulate detailed household tasks and then have artificial “agents” execute them, opening up the possibility of one day teaching robots to do such tasks.
The team trained the system using nearly 3,000 programs of various activities, which are further broken down into subtasks for the computer to understand. A simple task like “making coffee,” for example, would also include the step “grabbing a cup.” The researchers demonstrated VirtualHome in a 3-D world inspired by the Sims video game.
The team’s artificial agent can execute 1,000 of these interactions in the Sims-style world, with eight different scenes including a living room, kitchen, dining room, bedroom, and home office.
“Describing actions as computer programs has the advantage of providing clear and unambiguous descriptions of all the steps needed to complete a task,” says MIT PhD student Xavier Puig, who was lead author on the paper. “These programs can instruct a robot or a virtual character, and can also be used as a representation for complex tasks with simpler actions.”
The project was co-developed by CSAIL and the University of Toronto alongside researchers from McGill University and the University of Ljubljana. It will be presented at the Computer Vision and Pattern Recognition (CVPR) conference, which takes place this month in Salt Lake City.
Unlike humans, robots need more explicit instructions to complete easy tasks; they can’t just infer and reason with ease.
For example, one might tell a human to “switch on the TV and watch it from the sofa.” Here, actions like “grab the remote control” and “sit/lie on sofa” have been omitted, since they’re part of the commonsense knowledge that humans have.
To better demonstrate these kinds of tasks to robots, the descriptions for actions needed to be much more detailed. To do so, the team first collected verbal descriptions of household activities, and then translated them into simple code. A program like this might include steps like: walk to the television, switch on the television, walk to the sofa, sit on the sofa, and watch television.
Once the programs were created, the team fed them to the VirtualHome 3-D simulator to be turned into videos. Then, a virtual agent would execute the tasks defined by the programs, whether it was watching television, placing a pot on the stove, or turning a toaster on and off.
The end result is not just a system for training robots to do chores, but also a large database of household tasks described using natural language.Companies like Amazon that are working to develop Alexa-like robotic systems at home could eventually use data like these to train their models to do more complex tasks.
The team’s model successfully demonstrated that their agents could learn to reconstruct a program, and therefore perform a task, given either a description: “pour milk into glass” or a video demonstration of the activity.
“This line of work could facilitate true robotic personal assistants in the future,” says Qiao Wang, a research assistant in arts, media, and engineering at Arizona State University. “Instead of each task programmed by the manufacturer, the robot can learn tasks just by listening to or watching the specific person it accompanies. This allows the robot to do tasks in a personalized way, or even some day invoke an emotional connection as a result of this personalized learning process.”
In the future, the team hopes to train the robots using actual videos instead of Sims-style simulation videos, which would enable a robot to learn simply by watching a YouTube video. The team is also working on implementing a reward-learning system in which the agent gets positive feedback when it does tasks correctly.
“You can imagine a setting where robots are assisting with chores at home and can eventually anticipate personalized wants and needs, or impending action,” says Puig. “This could be especially helpful as an assistive technology for the elderly, or those who may have limited mobility.”
A system developed at MIT aims to teach artificial agents a range of chores, including setting the table and making coffee. Image: MIT CSAIL By Adam Conner-Simons | Rachel Gordon
For many people, household chores are a dreaded, inescapable part of life that we often put off or do with little care. But what if a robot assistant could help lighten the load?
Recently, computer scientists have been working on teaching machines to do a wider range of tasks around the house. In a new paper spearheaded by MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL) and the University of Toronto, researchers demonstrate “VirtualHome,” a system that can simulate detailed household tasks and then have artificial “agents” execute them, opening up the possibility of one day teaching robots to do such tasks.
The team trained the system using nearly 3,000 programs of various activities, which are further broken down into subtasks for the computer to understand. A simple task like “making coffee,” for example, would also include the step “grabbing a cup.” The researchers demonstrated VirtualHome in a 3-D world inspired by the Sims video game.
The team’s artificial agent can execute 1,000 of these interactions in the Sims-style world, with eight different scenes including a living room, kitchen, dining room, bedroom, and home office.
“Describing actions as computer programs has the advantage of providing clear and unambiguous descriptions of all the steps needed to complete a task,” says MIT PhD student Xavier Puig, who was lead author on the paper. “These programs can instruct a robot or a virtual character, and can also be used as a representation for complex tasks with simpler actions.”
The project was co-developed by CSAIL and the University of Toronto alongside researchers from McGill University and the University of Ljubljana. It will be presented at the Computer Vision and Pattern Recognition (CVPR) conference, which takes place this month in Salt Lake City.
Unlike humans, robots need more explicit instructions to complete easy tasks; they can’t just infer and reason with ease.
For example, one might tell a human to “switch on the TV and watch it from the sofa.” Here, actions like “grab the remote control” and “sit/lie on sofa” have been omitted, since they’re part of the commonsense knowledge that humans have.
To better demonstrate these kinds of tasks to robots, the descriptions for actions needed to be much more detailed. To do so, the team first collected verbal descriptions of household activities, and then translated them into simple code. A program like this might include steps like: walk to the television, switch on the television, walk to the sofa, sit on the sofa, and watch television.
Once the programs were created, the team fed them to the VirtualHome 3-D simulator to be turned into videos. Then, a virtual agent would execute the tasks defined by the programs, whether it was watching television, placing a pot on the stove, or turning a toaster on and off.
The end result is not just a system for training robots to do chores, but also a large database of household tasks described using natural language.Companies like Amazon that are working to develop Alexa-like robotic systems at home could eventually use data like these to train their models to do more complex tasks.
The team’s model successfully demonstrated that their agents could learn to reconstruct a program, and therefore perform a task, given either a description: “pour milk into glass” or a video demonstration of the activity.
“This line of work could facilitate true robotic personal assistants in the future,” says Qiao Wang, a research assistant in arts, media, and engineering at Arizona State University. “Instead of each task programmed by the manufacturer, the robot can learn tasks just by listening to or watching the specific person it accompanies. This allows the robot to do tasks in a personalized way, or even some day invoke an emotional connection as a result of this personalized learning process.”
In the future, the team hopes to train the robots using actual videos instead of Sims-style simulation videos, which would enable a robot to learn simply by watching a YouTube video. The team is also working on implementing a reward-learning system in which the agent gets positive feedback when it does tasks correctly.
“You can imagine a setting where robots are assisting with chores at home and can eventually anticipate personalized wants and needs, or impending action,” says Puig. “This could be especially helpful as an assistive technology for the elderly, or those who may have limited mobility.”
 In this episode of
In this episode of