Understanding the opportunities created by robotics in healthcare and why human nurses can never be replaced, is significant if both are to work in tandem to complement the tasks performed daily.
This, in turn, is driving inventory stakeholders to move their top-tier sites from majority bulk storage to majority racking, and from traditional aisles to very narrow aisles (VNAs). Rack heights have steadily increased from 25 feet, on average, to 35 feet or more.
In this episode, we hear from Brad Hayes, Assistant Professor of Computer Science at the University of Colorado Boulder, who directs the university’s Collaborative AI and Robotics lab. The lab’s work focuses on developing systems that can learn from and work with humans—from physical robots or machines, to software systems or decision support tools—so that together, the human and system can achieve more than each could achieve on their own.
Our interviewer Audrow caught up with Dr. Hayes to discuss why collaboration may at times be preferable to full autonomy and automation, how human naration can be used to help robots learn from demonstration, and the challenges of developing collaborative systems, including the importance of shared models and safety to allow adoption of such technologies in future.
Smart Warehousing is growing at an incredible pace, and it also happens to be the future of ecommerce. In this piece, I’m going to set out the main reasons why.
FABTECH EXPO takes place in Chicago, IL November 11th - 14th. This RoboticsTomorrow.com Special Tradeshow report aims to bring you news, articles and products from this years event.
FABTECH EXPO takes place in Chicago, IL November 11th - 14th. This RoboticsTomorrow.com Special Tradeshow report aims to bring you news, articles and products from this years event.
So, will AI replace the architect? With the aid of AI, the role of the architect or designer will change. Artificial intelligence will have the ability to generate rapid mass production in the future.
FANUC’s new collaborative arc welding robots offer the same high level of performance that FANUC ARC Mate robots are known for including world-renowned technology and proven reliability.
For those who can’t make it in person, or can’t possibly see everything, IROS is launching IROS TV. The first two episodes are below, but you can have a look at the 22 videos already produced here.
The Wyss Institute’s and SEAS robotics team built different models of the soft actuator powered RoboBee. Shown here is a four-wing, two actuator, and an eight-wing, four-actuator RoboBee model the latter of which being the first soft actuator-powered flying microrobot that is capable of controlled hovering flight. Credit: Harvard Microrobotics Lab/Harvard SEASBy Leah Burrows
Researchers at SEAS and Harvard’s Wyss Institute for Biologically Inspired Engineering have developed a resilient RoboBee powered by soft artificial muscles that can crash into walls, fall onto the floor, and collide with other RoboBees without being damaged. It is the first microrobot powered by soft actuators to achieve controlled flight.
“There has been a big push in the field of microrobotics to make mobile robots out of soft actuators because they are so resilient,” said Yufeng Chen, Ph.D., a former graduate student and postdoctoral fellow at SEAS and first author of the paper. “However, many people in the field have been skeptical that they could be used for flying robots because the power density of those actuators simply hasn’t been high enough and they are notoriously difficult to control. Our actuator has high enough power density and controllability to achieve hovering flight.”
To solve the problem of power density, the researchers built upon the electrically-driven soft actuators developed in the lab of David Clarke, Ph.D., the Extended Tarr Family Professor of Materials at SEAS. These soft actuators are made using dielectric elastomers, soft materials with good insulating properties that deform when an electric field is applied.
By improving the electrode conductivity, the researchers were able to operate the actuator at 500 Hertz, on par with the rigid actuators used previously in similar robots.
Another challenge when dealing with soft actuators is that the system tends to buckle and become unstable. To solve this challenge, the researchers built a lightweight airframe with a piece of vertical constraining thread to prevent the actuator from buckling.
The soft actuators can be easily assembled and replaced in these small-scale robots. To demonstrate various flight capabilities, the researchers built several different models of the soft actuator-powered RoboBee. A two-wing model could take off from the ground but had no additional control. A four-wing, two-actuator model could fly in a cluttered environment, overcoming multiple collisions in a single flight.
“One advantage of small-scale, low-mass robots is their resilience to external impacts,” said Elizabeth Farrell Helbling, Ph.D., a former graduate student at SEAS and a coauthor on the paper. “The soft actuator provides an additional benefit because it can absorb impact better than traditional actuation strategies. This would come in handy in potential applications such as flying through rubble for search and rescue missions.”
An eight-wing, four-actuator model demonstrated controlled hovering flight, the first for a soft-actuator-powered flying microrobot.
Next, the researchers aim to increase the efficiency of the soft-powered robot, which still lags far behind more traditional flying robots.
“Soft actuators with muscle-like properties and electrical activation represent a grand challenge in robotics,” says Wyss Institute Core Faculty member Robert Wood, Ph.D., who also is the Charles River Professor of Engineering and Applied Sciences in SEAS and senior author of the paper. “If we could engineer high performance artificial muscles, the sky is the limit for what robots we could build.”
This paper was also co-authored by Huichan Zhao, Jie Mao, Pakpong Chirarattananon, Nak-seung, and Patrick Hyun. It supported in part by the National Science Foundation.
When learning to follow natural language instructions, neural networks tend to be very data hungry – they require a huge number of examples pairing language with actions in order to learn effectively. This post is about reducing those heavy data requirements by first watching actions in the environment before moving on to learning from language data. Inspired by the idea that it is easier to map language to meanings that have already been formed, we introduce a semi-supervised approach that aims to separate the formation of abstractions from the learning of language.
Empirically, we find that pre-learning of patterns in the environment can help us learn grounded language with much less data.
Before we dive into the details, let’s look at an example to see why neural networks struggle to learn from smaller amounts of data. For now, we’ll use examples from the SHRDLURN block stacking task, but later we’ll look at results on another environment.
Let’s put ourselves in the shoes of a model that is learning to follow instructions. Suppose we are given the single training example below, which pairs a language command with an action in the environment:
This example tells us that if we are in state (a) and are trying to follow the instruction (b), the correct output for our model is the state (c). Before learning, the model doesn’t know anything about language, so we must rely on examples like the one shown to figure out the meaning of the words. After learning, we will be given new environment states and new instructions, and the model’s job is to choose the correct output states from executing the instructions. First let’s consider a simple case where we get the exact same language, but the environment state is different, like the one shown here:
On this new state, the model has many different possible outputs that it could consider. Here are just a few:
Some of these outputs seem reasonable to a human, like stacking red blocks on orange blocks or stacking red blocks on the left, but others are kind of strange, like generating a completely unrelated configuration of blocks. To a neural network with no prior knowledge, however, all of these options look plausible.
A human learning a new language might approach this task by reasoning about possible meanings of the language that are consistent with the given example and choosing states that correspond to those meanings. The set of possible meanings to consider comes from prior knowledge about what types of things might happen in an environment and how we can talk about them. In this context, a meaning is an abstract transformation that we can apply to states to get new states. For example, if someone saw the training instance above paired with language they didn’t understand, they might focus on two possible meanings for the instruction: it could be telling us to stack red blocks on orange blocks, or it could be telling us to stack a red block on the leftmost position.
Although we don’t know which of these two options is correct – both are plausible given the evidence – we now have many fewer options and might easily distinguish between them with just one or two more related examples. Having a set of pre-formed meanings makes learning easier because the meanings constrain the space of possible outputs that must be considered.
In fact, pre-formed meanings do even more than just restricting the number of choices, because once we have chosen a meaning to pair with the language, it specifies the correct way to generalize across a wide variety of different initial environment states. For example, consider the following transitions:
If we know in advance that all of these transitions belong together in a single semantic group (adding a red block on the left), learning language becomes easier because we can map to the group instead of the individual transitions. An end-to-end network that doesn’t start with any grouping of transitions has a much harder time because it has to learn the correct way to generalize across initial states. One approach used by a long line of past work has been to provide the learner with a manually defined set of abstractions called logical forms. In contrast, we take a more data-driven approach where we learn abstractions from unsupervised (language-free) data instead.
In this work, we help a neural network learn language with fewer examples by first learning abstractions from language-free observations of actions in an environment. The idea here is that if the model sees lots of actions happening in an environment, perhaps it can pick up on patterns in what tends to be done, and these patterns might give hints at what abstractions are useful. Our pre-learned abstractions can make language learning easier by constraining the space of outputs we need to consider and guiding generalization across different environment states.
We break up learning into two phases: an environment learning phase where our agent builds abstractions from language-free observation of the environment, and a language learning phase where natural language instructions are mapped to the pre-learned abstractions. The motivation for this setup is that language-free observations of the environment are often easier to get than interactions paired with language, so we should use the cheaper unlabeled data to help us learn with less language data. For example, a virtual assistant could learn with data from regular smartphone use, or in the longer term robots might be able to learn by watching humans naturally interact with the world. In the environments we are using in this post, we don’t have a natural source of unlabeled observations, so we generate the environment data synthetically.
Method
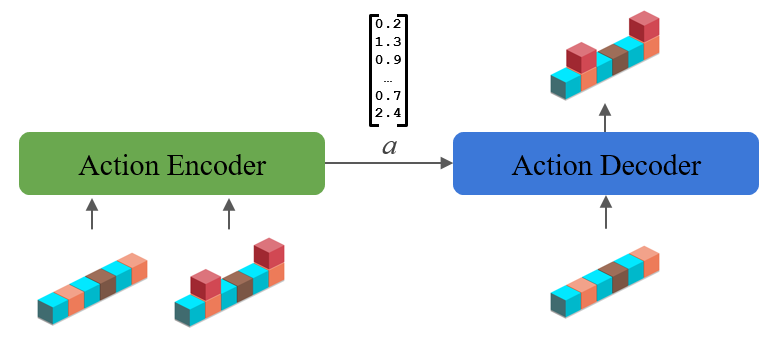
Now we’re ready to dive into our method. We’ll start with the environment learning phase, where we will learn abstractions by observing an agent, such as a human, acting in the environment. Our approach during this phase will be to create a type of autoencoder of the state transitions (actions) that we see, shown below:
The encoder takes in the states before and after the transition and computes a representation of the transition itself. The decoder takes that transition representation from the encoder and must use it to recreate the final state from the initial one. The encoder and decoder architectures will be task specific, but use generic components such as convolutions or LSTMs. For example, in the block stacking task states are represented as a grid and we use a convolutional architecture. We train using a standard cross-entropy loss on the decoder’s output state, and after training we will use the representation passed between the encoder and decoder as our learned abstraction.
One thing that this autoencoder will learn is which type of transitions tend to happen, because the model will learn to only output transitions like the ones it sees during training. In addition, this model will learn to group different transitions. This grouping happens because the representation between the encoder and decoder acts as an information bottleneck, and its limited capacity forces the model to reuse the same representation vector for multiple different transitions. We find that often the groupings it chooses tend to be semantically meaningful because representations that align with the semantics of the environment tend to be the most compact.
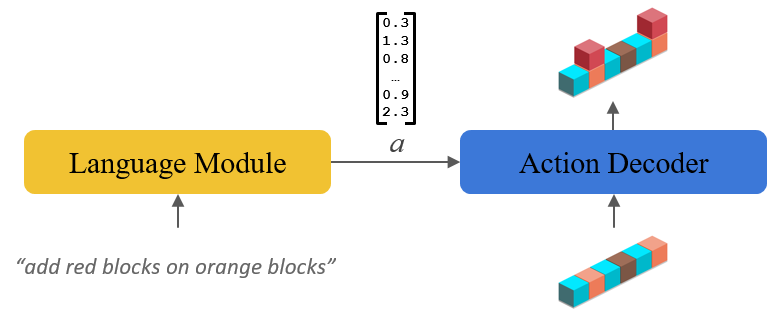
After environment learning pre-training, we are ready to move on to learning language. For the language learning phase, we will start with the decoder that we pre-trained during environment learning (“action decoder” in the figures above and below). The decoder maps from our learned representation space to particular state outputs. To learn language, we now just need to introduce a language encoder module that maps from language into the representation space and train it by backpropagating through the decoder. The model structure is shown in the figure below.
The model in this phase looks a lot like other encoder-decoder models used previously for instruction following tasks, but now the pre-trained decoder can constrain the output and help control generalization.
Results
Now let’s look at some results. We’ll compare our method to an end-to-end neural model, which has an identical neural architecture to our ultimate language learning model but without any environment learning pre-training of the decoder. First we test on the SHURDLURN block stacking task, a task that is especially challenging for neural models because it requires learning with just tens of examples. A baseline neural model gets an accuracy of 18% on the task, but with our environment learning pre-training, the model reaches 28%, an improvement of ten absolute percentage points.
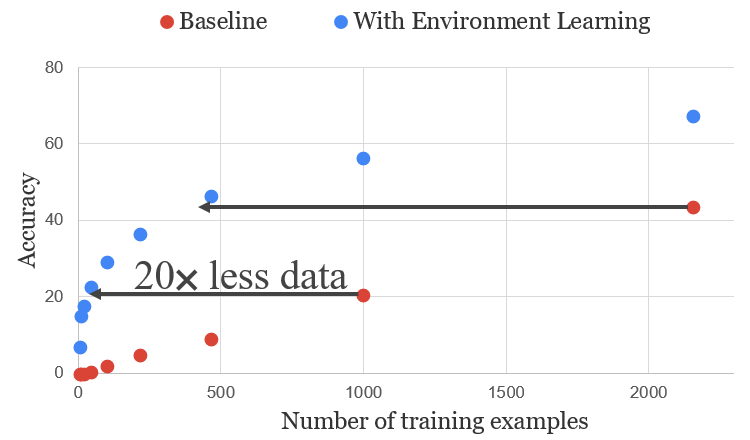
We also tested our method on a string manipulation task where we learn to execute instructions like “insert the letters vw after every vowel” on a string of characters. The chart below shows accuracy as we vary the amount of data for both the baseline end-to-end model and the model with our pre-training procedure.
As shown above, using our pre-training method leads to much more data-efficient language learning compared to learning from scratch. By pre-learning abstractions from the environment, our method increases data efficiency by more than an order of magnitude. To learn more about our method, including some additional performance-improving tricks and an analysis of what pre-training learns, check out our paper from ACL 2019: https://arxiv.org/abs/1907.09671.
This article was initially published on the BAIR blog, and appears here with the authors’ permission.
Joao Ramos (center), co-inventor of HERMES (left), and Little HERMES (right) Photo: Tony Pulsone By Jennifer Chu
Rescuing victims from a burning building, a chemical spill, or any disaster that is inaccessible to human responders could one day be a mission for resilient, adaptable robots. Imagine, for instance, rescue-bots that can bound through rubble on all fours, then rise up on two legs to push aside a heavy obstacle or break through a locked door.
Engineers are making strides on the design of four-legged robots and their ability to run, jump and even do backflips. But getting two-legged, humanoid robots to exert force or push against something without falling has been a significant stumbling block.
Now engineers at MIT and the University of Illinois at Urbana-Champaign have developed a method to control balance in a two-legged, teleoperated robot — an essential step toward enabling a humanoid to carry out high-impact tasks in challenging environments.
The team’s robot, physically resembling a machined torso and two legs, is controlled remotely by a human operator wearing a vest that transmits information about the human’s motion and ground reaction forces to the robot.
Through the vest, the human operator can both direct the robot’s locomotion and feel the robot’s motions. If the robot is starting to tip over, the human feels a corresponding pull on the vest and can adjust in a way to rebalance both herself and, synchronously, the robot.
In experiments with the robot to test this new “balance feedback” approach, the researchers were able to remotely maintain the robot’s balance as it jumped and walked in place in sync with its human operator.
“It’s like running with a heavy backpack — you can feel how the dynamics of the backpack move around you, and you can compensate properly,” says Joao Ramos, who developed the approach as an MIT postdoc. “Now if you want to open a heavy door, the human can command the robot to throw its body at the door and push it open, without losing balance.”
Ramos, who is now an assistant professor at the University of Illinois at Urbana-Champaign, has detailed the approach in a study appearing today in Science Robotics. His co-author on the study is Sangbae Kim, associate professor of mechanical engineering at MIT.
More than motion
Previously, Kim and Ramos built the two-legged robot HERMES (for Highly Efficient Robotic Mechanisms and Electromechanical System) and developed methods for it to mimic the motions of an operator via teleoperation, an approach that the researchers say comes with certain humanistic advantages.
“Because you have a person who can learn and adapt on the fly, a robot can perform motions that it’s never practiced before [via teleoperation],” Ramos says.
In demonstrations, HERMES has poured coffee into a cup, wielded an ax to chop wood, and handled an extinguisher to put out a fire.
All these tasks have involved the robot’s upper body and algorithms to match the robot’s limb positioning with that of its operator’s. HERMES was able to carry out high-impact motions because the robot was rooted in place. Balance, in these cases, was much simpler to maintain. If the robot were required to take any steps, however, it would have likely tipped over in attempting to mimic the operator’s motions.
“We realized in order to generate high forces or move heavy objects, just copying motions wouldn’t be enough, because the robot would fall easily,” Kim says. “We needed to copy the operator’s dynamic balance.”
Enter Little HERMES, a miniature version of HERMES that is about a third the size of an average human adult. The team engineered the robot as simply a torso and two legs, and designed the system specifically to test lower-body tasks, such as locomotion and balance. As with its full-body counterpart, Little HERMES is designed for teleoperation, with an operator suited up in a vest to control the robot’s actions.
For the robot to copy the operator’s balance rather than just their motions, the team had to first find a simple way to represent balance. Ramos eventually realized that balance could be stripped down to two main ingredients: a person’s center of mass and their center of pressure — basically, a point on the ground where a force equivalent to all supporting forces is exerted.
The location of the center of mass in relation to the center of pressure, Ramos found, relates directly to how balanced a person is at any given time. He also found that the position of these two ingredients could be physically represented as an inverted pendulum. Imagine swaying from side to side while staying rooted to the same spot. The effect is similar to the swaying of an upside-down pendulum, the top end representing a human’s center of mass (usually in the torso) and the bottom representing their center of pressure on the ground.
Heavy lifting
To define how center of mass relates to center of pressure, Ramos gathered human motion data, including measurements in the lab, where he swayed back and forth, walked in place, and jumped on a force plate that measured the forces he exerted on the ground, as the position of his feet and torso were recorded. He then condensed this data into measurements of the center of mass and the center of pressure, and developed a model to represent each in relation to the other, as an inverted pendulum.
He then developed a second model, similar to the model for human balance but scaled to the dimensions of the smaller, lighter robot, and he developed a control algorithm to link and enable feedback between the two models.
The researchers tested this balance feedback model, first on a simple inverted pendulum that they built in the lab, in the form of a beam about the same height as Little HERMES. They connected the beam to their teleoperation system, and it swayed back and forth along a track in response to an operator’s movements. As the operator swayed to one side, the beam did likewise — a movement that the operator could also feel through the vest. If the beam swayed too far, the operator, feeling the pull, could lean the other way to compensate, and keep the beam balanced.
The experiments showed that the new feedback model could work to maintain balance on the beam, so the researchers then tried the model on Little HERMES. They also developed an algorithm for the robot to automatically translate the simple model of balance to the forces that each of its feet would have to generate, to copy the operator’s feet.
In the lab, Ramos found that as he wore the vest, he could not only control the robot’s motions and balance, but he also could feel the robot’s movements. When the robot was struck with a hammer from various directions, Ramos felt the vest jerk in the direction the robot moved. Ramos instinctively resisted the tug, which the robot registered as a subtle shift in the center of mass in relation to center of pressure, which it in turn mimicked. The result was that the robot was able to keep from tipping over, even amidst repeated blows to its body.
Little HERMES also mimicked Ramos in other exercises, including running and jumping in place, and walking on uneven ground, all while maintaining its balance without the aid of tethers or supports.
“Balance feedback is a difficult thing to define because it’s something we do without thinking,” Kim says. “This is the first time balance feedback is properly defined for the dynamic actions. This will change how we control a teleoperated humanoid.”
Kim and Ramos will continue to work on developing a full-body humanoid with similar balance control, to one day be able to gallop through a disaster zone and rise up to push away barriers as part of rescue or salvage missions.
“Now we can do heavy door opening or lifting or throwing heavy objects, with proper balance communication,” Kim says.
This research was supported, in part, by Hon Hai Precision Industry Co. Ltd. and Naver Labs Corporation.
For last-mile delivery, robots of the future may use a new MIT algorithm to find the front door, using clues in their environment. Image: MIT News By Jennifer Chu
In the not too distant future, robots may be dispatched as last-mile delivery vehicles to drop your takeout order, package, or meal-kit subscription at your doorstep — if they can find the door.
Standard approaches for robotic navigation involve mapping an area ahead of time, then using algorithms to guide a robot toward a specific goal or GPS coordinate on the map. While this approach might make sense for exploring specific environments, such as the layout of a particular building or planned obstacle course, it can become unwieldy in the context of last-mile delivery.
Imagine, for instance, having to map in advance every single neighborhood within a robot’s delivery zone, including the configuration of each house within that neighborhood along with the specific coordinates of each house’s front door. Such a task can be difficult to scale to an entire city, particularly as the exteriors of houses often change with the seasons. Mapping every single house could also run into issues of security and privacy.
Now MIT engineers have developed a navigation method that doesn’t require mapping an area in advance. Instead, their approach enables a robot to use clues in its environment to plan out a route to its destination, which can be described in general semantic terms, such as “front door” or “garage,” rather than as coordinates on a map. For example, if a robot is instructed to deliver a package to someone’s front door, it might start on the road and see a driveway, which it has been trained to recognize as likely to lead toward a sidewalk, which in turn is likely to lead to the front door.
The new technique can greatly reduce the time a robot spends exploring a property before identifying its target, and it doesn’t rely on maps of specific residences.
“We wouldn’t want to have to make a map of every building that we’d need to visit,” says Michael Everett, a graduate student in MIT’s Department of Mechanical Engineering. “With this technique, we hope to drop a robot at the end of any driveway and have it find a door.”
Everett will present the group’s results this week at the International Conference on Intelligent Robots and Systems. The paper, which is co-authored by Jonathan How, professor of aeronautics and astronautics at MIT, and Justin Miller of the Ford Motor Company, is a finalist for “Best Paper for Cognitive Robots.”
“A sense of what things are”
In recent years, researchers have worked on introducing natural, semantic language to robotic systems, training robots to recognize objects by their semantic labels, so they can visually process a door as a door, for example, and not simply as a solid, rectangular obstacle.
“Now we have an ability to give robots a sense of what things are, in real-time,” Everett says.
Everett, How, and Miller are using similar semantic techniques as a springboard for their new navigation approach, which leverages pre-existing algorithms that extract features from visual data to generate a new map of the same scene, represented as semantic clues, or context.
In their case, the researchers used an algorithm to build up a map of the environment as the robot moved around, using the semantic labels of each object and a depth image. This algorithm is called semantic SLAM (Simultaneous Localization and Mapping).
While other semantic algorithms have enabled robots to recognize and map objects in their environment for what they are, they haven’t allowed a robot to make decisions in the moment while navigating a new environment, on the most efficient path to take to a semantic destination such as a “front door.”
“Before, exploring was just, plop a robot down and say ‘go,’ and it will move around and eventually get there, but it will be slow,” How says.
The cost to go
The researchers looked to speed up a robot’s path-planning through a semantic, context-colored world. They developed a new “cost-to-go estimator,” an algorithm that converts a semantic map created by preexisting SLAM algorithms into a second map, representing the likelihood of any given location being close to the goal.
“This was inspired by image-to-image translation, where you take a picture of a cat and make it look like a dog,” Everett says. “The same type of idea happens here where you take one image that looks like a map of the world, and turn it into this other image that looks like the map of the world but now is colored based on how close different points of the map are to the end goal.”
This cost-to-go map is colorized, in gray-scale, to represent darker regions as locations far from a goal, and lighter regions as areas that are close to the goal. For instance, the sidewalk, coded in yellow in a semantic map, might be translated by the cost-to-go algorithm as a darker region in the new map, compared with a driveway, which is progressively lighter as it approaches the front door — the lightest region in the new map.
The researchers trained this new algorithm on satellite images from Bing Maps containing 77 houses from one urban and three suburban neighborhoods. The system converted a semantic map into a cost-to-go map, and mapped out the most efficient path, following lighter regions in the map, to the end goal. For each satellite image, Everett assigned semantic labels and colors to context features in a typical front yard, such as grey for a front door, blue for a driveway, and green for a hedge.
During this training process, the team also applied masks to each image to mimic the partial view that a robot’s camera would likely have as it traverses a yard.
“Part of the trick to our approach was [giving the system] lots of partial images,” How explains. “So it really had to figure out how all this stuff was interrelated. That’s part of what makes this work robustly.”
The researchers then tested their approach in a simulation of an image of an entirely new house, outside of the training dataset, first using the preexisting SLAM algorithm to generate a semantic map, then applying their new cost-to-go estimator to generate a second map, and path to a goal, in this case, the front door.
The group’s new cost-to-go technique found the front door 189 percent faster than classical navigation algorithms, which do not take context or semantics into account, and instead spend excessive steps exploring areas that are unlikely to be near their goal.
Everett says the results illustrate how robots can use context to efficiently locate a goal, even in unfamiliar, unmapped environments.
“Even if a robot is delivering a package to an environment it’s never been to, there might be clues that will be the same as other places it’s seen,” Everett says. “So the world may be laid out a little differently, but there’s probably some things in common.”
This research is supported, in part, by the Ford Motor Company.