Matt Bilsky, founder and CEO of FLX Solutions, discusses the snake-like robot he invented called the FLX BOT. The FLX BOT consists of modular links, each with a joint that can extend and rotate to get into tight spaces. Each link includes sensors including inertial measurement units and a camera. The robot is used to navigate and work in challenging environments, such as above ceilings and within walls. Matt discusses the key innovations of his product as well as his academic and entrepreneurial journey that led him to the FLX BOT.
Matt Bilksy
Matt Bilsky, PhD, PE is the inventor of the FLX BOT, a licensed Professional Engineer, a Mechanical Engineering professor at Lehigh University, and a former repair/maintenance contractor. In 2017, he was awarded with the Lehigh University Entrepreneurship Educator of the Year. Matt has a Mechanical Engineering Ph.D. from Lehigh University focused on smart product design, Technical Entrepreneurship, and mechatronics. He holds two additional Lehigh degrees: a BS in Mechanical Engineering with an Electrical Engineering minor and a Master of Engineering degree also in Mechanical Engineering. Since he was a child Matt has been an innovator. In his basement shop he designed and built numerous electronic gadgets. In 2003 he started his first company, Mattcomp Services LLC, offering computer repair, networking, home theater, and handyman services. He also created a web hosting company in 2005, Mattcomp Hosting, including all necessary back-end components on dedicated servers.
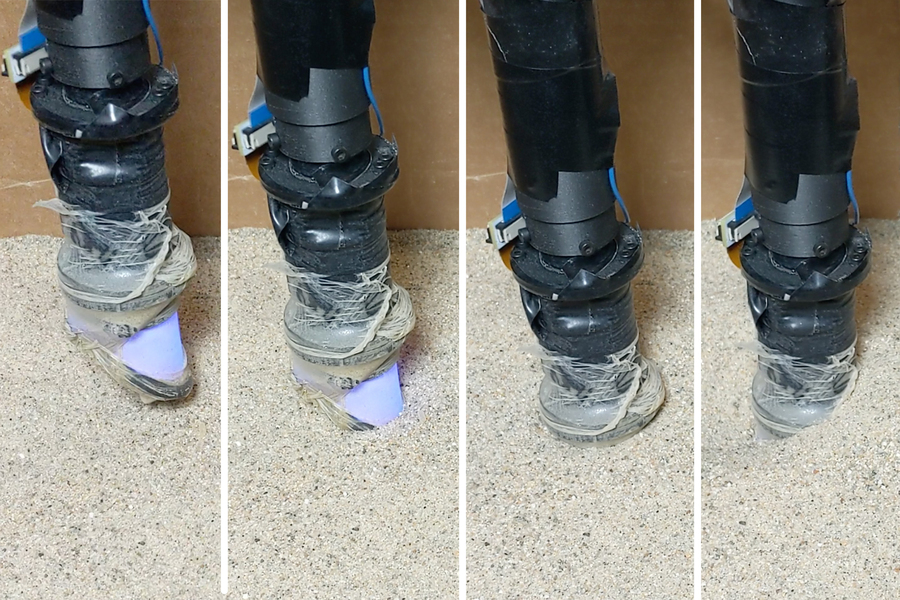
MIT researchers developed a “Digger Finger” robot that digs through granular material, like sand and gravel, and senses the shapes of buried objects. The technology could aid in disarming buried bombs or inspecting underground cables. Image courtesy of the researchers.
By Daniel Ackerman
Over the years, robots have gotten quite good at identifying objects — as long as they’re out in the open.
Discerning buried items in granular material like sand is a taller order. To do that, a robot would need fingers that were slender enough to penetrate the sand, mobile enough to wriggle free when sand grains jam, and sensitive enough to feel the detailed shape of the buried object.
MIT researchers have now designed a sharp-tipped robot finger equipped with tactile sensing to meet the challenge of identifying buried objects. In experiments, the aptly named Digger Finger was able to dig through granular media such as sand and rice, and it correctly sensed the shapes of submerged items it encountered. The researchers say the robot might one day perform various subterranean duties, such as finding buried cables or disarming buried bombs.
The research will be presented at the next International Symposium on Experimental Robotics. The study’s lead author is Radhen Patel, a postdoc in MIT’s Computer Science and Artificial Intelligence Laboratory (CSAIL). Co-authors include CSAIL PhD student Branden Romero, Harvard University PhD student Nancy Ouyang, and Edward Adelson, the John and Dorothy Wilson Professor of Vision Science in CSAIL and the Department of Brain and Cognitive Sciences.
Seeking to identify objects buried in granular material — sand, gravel, and other types of loosely packed particles — isn’t a brand new quest. Previously, researchers have used technologies that sense the subterranean from above, such as Ground Penetrating Radar or ultrasonic vibrations. But these techniques provide only a hazy view of submerged objects. They might struggle to differentiate rock from bone, for example.
“So, the idea is to make a finger that has a good sense of touch and can distinguish between the various things it’s feeling,” says Adelson. “That would be helpful if you’re trying to find and disable buried bombs, for example.” Making that idea a reality meant clearing a number of hurdles.
The team’s first challenge was a matter of form: The robotic finger had to be slender and sharp-tipped.
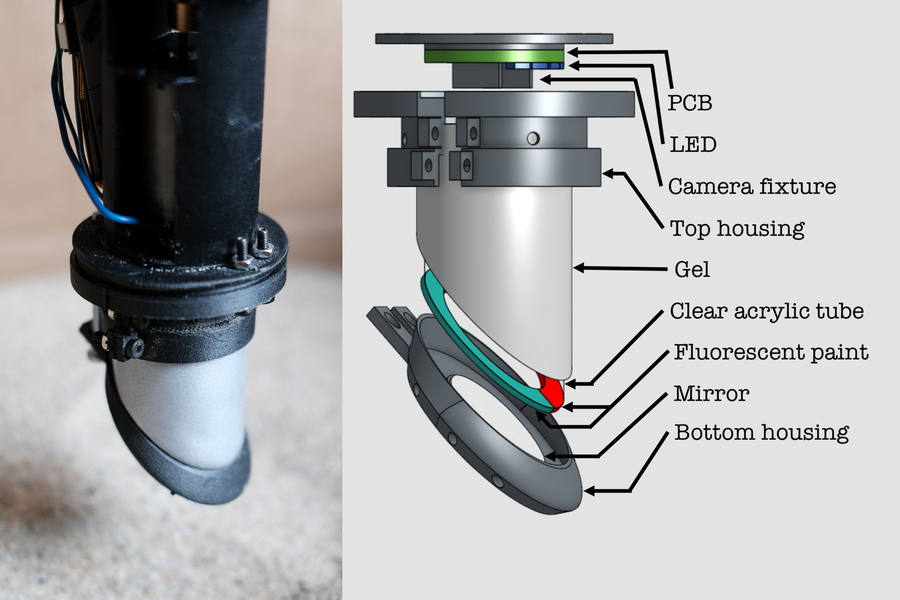
In prior work, the researchers had used a tactile sensor called GelSight. The sensor consisted of a clear gel covered with a reflective membrane that deformed when objects pressed against it. Behind the membrane were three colors of LED lights and a camera. The lights shone through the gel and onto the membrane, while the camera collected the membrane’s pattern of reflection. Computer vision algorithms then extracted the 3D shape of the contact area where the soft finger touched the object. The contraption provided an excellent sense of artificial touch, but it was inconveniently bulky.
A closeup photograph of the new robot and a diagram of its parts. Image courtesy of the researchers.
For the Digger Finger, the researchers slimmed down their GelSight sensor in two main ways. First, they changed the shape to be a slender cylinder with a beveled tip. Next, they ditched two-thirds of the LED lights, using a combination of blue LEDs and colored fluorescent paint. “That saved a lot of complexity and space,” says Ouyang. “That’s how we were able to get it into such a compact form.” The final product featured a device whose tactile sensing membrane was about 2 square centimeters, similar to the tip of a finger.
With size sorted out, the researchers turned their attention to motion, mounting the finger on a robot arm and digging through fine-grained sand and coarse-grained rice. Granular media have a tendency to jam when numerous particles become locked in place. That makes it difficult to penetrate. So, the team added vibration to the Digger Finger’s capabilities and put it through a battery of tests.
“We wanted to see how mechanical vibrations aid in digging deeper and getting through jams,” says Patel. “We ran the vibrating motor at different operating voltages, which changes the amplitude and frequency of the vibrations.” They found that rapid vibrations helped “fluidize” the media, clearing jams and allowing for deeper burrowing — though this fluidizing effect was harder to achieve in sand than in rice.
Top row: 3D printed objects used for the object identification experiment. Middle row: Example image data when the Digger Finger directly touches a 3d printed object. Bottom row: Example image data when the Digger Finger touches a 3d printed object that is buried in sand. Image courtesy of the researchers.
They also tested various twisting motions in both the rice and sand. Sometimes, grains of each type of media would get stuck between the Digger-Finger’s tactile membrane and the buried object it was trying to sense. When this happened with rice, the trapped grains were large enough to completely obscure the shape of the object, though the occlusion could usually be cleared with a little robotic wiggling. Trapped sand was harder to clear, though the grains’ small size meant the Digger Finger could still sense the general contours of target object.
Patel says that operators will have to adjust the Digger Finger’s motion pattern for different settings “depending on the type of media and on the size and shape of the grains.” The team plans to keep exploring new motions to optimize the Digger Finger’s ability to navigate various media.
Adelson says the Digger Finger is part of a program extending the domains in which robotic touch can be used. Humans use their fingers amidst complex environments, whether fishing for a key in a pants pocket or feeling for a tumor during surgery. “As we get better at artificial touch, we want to be able to use it in situations when you’re surrounded by all kinds of distracting information,” says Adelson. “We want to be able to distinguish between the stuff that’s important and the stuff that’s not.”
Funding for this research was provided, in part, by the Toyota Research Institute through the Toyota-CSAIL Joint Research Center; the Office of Naval Research; and the Norwegian Research Council.
“Robotics-as-a-service” is a model in which customers purchase automation on an “as-needed” basis. This could be monthly pricing or usage-based pricing. Upfront costs are typically negligible or non-existent.
Discover what is regularization, why it is necessary in deep neural networks and explore the most frequently used strategies: L1, L2, dropout, stohastic depth, early stopping and more
When you sell a robot, the amount of additional required pneumatic components, sensing products, vision inspection systems and machine safety products can cost as much or more than the robot itself. Every robot sold has an exponential economic ripple effect.
Ultrasonic uses energy from microscopic vibrations of a blade to pass easily through the material and offers a more effective solution for cutting cheese and other food products. When paired with automation, ultrasonic technology can deliver precise and accurate cutting.
Creating robots that can perform acrobatic movements such as flips or spinning jumps can be highly challenging. Typically, in fact, these robots require sophisticated hardware designs, motion planners and control algorithms.
The 2020 Honeywell Intelligrated Automation Investment Study revealed that e-commerce (66 per cent) grocery, food and beverage (59 per cent) and logistics (55 per cent) industries are most willing to invest more in automation.
To celebrate Women’s Day 2021 and the 50th anniversary of women’s right to vote in Switzerland, the Swiss NCCRs (National Centres of Competence in Research) wanted to show you who our women researchers are and what a day in their job looks like. The videos are targeted at women and girls of school and undergraduate age to show what day to day life as a scientist is like and make it more accessible. Each NCCR hosted a week where they published several videos covering multiple scientific disciplines, and here we are bringing you what was produced by NCCR Digital Fabrication.
The videos cover a wide range of subjects, including (but not limited to) maths, physics, microbiology, psychology and planetary science, but here we have two women who work with robots.
Maria Vittoria Minniti is a robotics engineer and PhD student, she enhances mobile manipulation capabilities in under-actuated robots.
Inés Ariza is an architect, she uses a robot to 3D print custom metal joints for complex structures.
Head over to YouTube or Instagram (English, German or French) to see the women featured in the #NCCRWomen campaign.
As robot swarms leave the lab and enter our daily lives, it is important that we find ways by which we can effectively communicate with robot swarms, especially ones that contain a high number of robots. In our lab, we are thinking of ways to make swarms for people that are easy and intuitive to interact with. By making robots expressive, we will be able to understand their state and therefore, we will be able to make decisions accordingly. To that extent, we have created a system where humans can build a canvas with robots and create shapes with up to 300 real robots and up to 1000 simulated robots.
Painting with robots
In a system we created called Robotic Canvas, we project an image onto a robot swarm via an overhead projector, and the swarm replicates the image using their LEDs by sensing the colour of light projected. Each robot, therefore, acts as a pixel on the canvas. The humans can then interact with the robot pixels by copying/pasting pixels (LED colour) onto different parts on the canvas, erasing them (turning off LEDs), changing their colour, or saving/retrieving paintings (by saving/retrieving the state of the LED). If a GIF or a video is projected onto the robots, the robots appear to be showing a video. The robots are also decentralised, which means they have no central controller telling them what to do, avoiding a single point of failure of the system. This enables the system to carry on if one robot fails, enabling humans to still interact and create paintings with the rest of the robots. The robots have to resort to talking to their neighbours and sensing their environment in order to obtain information on how to act next. Consequently, robot pixels use only local interactions (i.e. communications with their neighbouring robots) and environmental interactions (i.e. sensing the colour of light and shadows) to be able to tell which interaction is taking place. Here are some images showing the robots recreating images projected onto them.
Here is a performance we did with the robots. This is a story of day and night; the sun sets on the ocean permitting night to arrive. Then, start begin to show in the night sky, and clouds form as well. Finally, the sun rises again.
Creating shapes with robots
In Robotic Canvas, the robots were stationary, and they needed to fill out the whole shape to be able to represent the image projected onto them properly. However, we were able to reduce the number of robots used by enabling them to move and aggregate around edges of images projected onto them. This way, a smaller number of robots can be used to represent an image while still preserving clear image representation. We were also able to produce videos with the robots by projecting a video onto them. We used up to 300 real robots (as can be seen from the line, circle and arrow shapes below) and up to 1000 simulated robots (as can be seen in the letters F, T and the blinking eye video).
The way the robots are able to aggregate around edges is again done only through local and environmental interactions. Robots share with their neighbours the light colour they sense. They then combine their neighbours’ opinions with their own to reach a final decision on what colour is being projected. Robots move randomly as long as their opinions match their neighbours’ opinions. If there is a high conflict of opinions, that means robots are standing on an edge, and they stop moving. They then broadcast a message to their neighbours to aggregate around them to represent the edge. We can increase the distance by which neighbours respond to the edge robots, giving us the ability to have thicker or thinner lines of robots on the edges.
The robots do not need to have the image the user wishes for them to represent stored in their memory. That gives the system an important feature: adaptability. The user can change the image projected at any time and the robots will re-configure themselves to represent the new image.
The inspiration behind robot expressivity
Our research was inspired by the fact that robot swarms and human-swarm interaction are exciting hot topics in today’s world of robotics. Searching for ways by which to interact with swarm robots that neither break their decentralisation nature of not needing a central controller, nor humans needing to interact with each robot separately (as there could potentially be thousands of robots and hence would be unfeasible to update them separately) is an interesting and challenging problem to solve. Therefore, we created the Robotic Canvas to experiment with methods by which a user can relay messages to, and influence the behaviour of, 100’s of robots without needing to communicate with each separately. We researched how we can do such a task only using environmental and/or local interactions only. Furthermore, we decided to add mobility to the robots, which results in using a smaller number of robots for image representation.
Challenges along the way
While creating paintings and shapes look interesting and fun, the road to creating this system was not without obstacles! Going from working in simulation to working with real-life robots deemed challenging. This was due to noise from robot motion in real robots and also errors in sensor readings. Using a circular arena helped with preventing robots getting stuck at the boundaries of the arena. As for sensing errors, filtering noisy readings before broadcasting opinions to neighbours helped with reducing error in edge detection.
Limitations of our system
The size of the robots is directly proportional to the resolution of the image, similar to how pixels work. The smaller the robots (and their LEDs), the clearer the picture representation will be. Therefore, there is a limitation on how clearly very complex images could be represented with the current robots used (the Kilobots).
Beyond painting
The emergent shape-formation behaviour of robot swarms has many potential applications in the real world. Its expressive nature serves it well as an artistic and interactive visual display. Also, the robots could be used as functional materials which respond to light projections by depositing themselves onto image edges, which could have applications in architecture and electronics. The system could also have applications in ocean clean-ups, where robot swarms could detect and surround pollutants in oceans such as oil spills.
Robotics is both an exciting and intimidating field because it takes so many different capabilities and disciplines to spin up a robot. This goes all the way from mechatronic design and hardware engineering to some of the more philosophical parts of software engineering.
Those who know me also know I’m a total “high-level guy”. I’m fascinated by how complex a modern robotic system is and how all the pieces come together to make something that’s truly impressive. I don’t have particularly deep knowledge in any specific area of robotics, but I appreciate the work of countless brilliant people that give folks like me the ability to piece things together.
In this post, I will go through what it takes to put together a robot that is highly capable by today’s standards. This is very much an opinion article that tries to slice robotic skills along various dimensions. I found it challenging to find a single “correct” taxonomy, so I look forward to hearing from you about anything you might disagree with or have done differently.
What defines a robot?
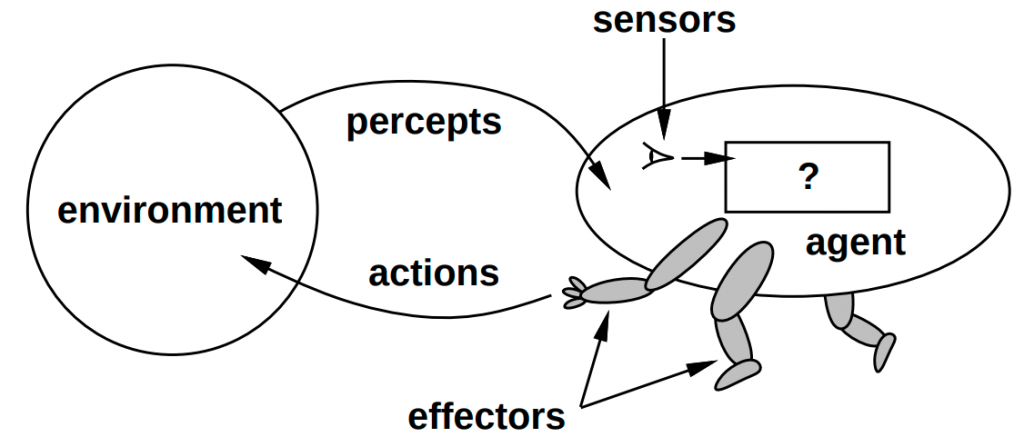
Roughly speaking, a robot is a machine with sensors, actuators, and some computing device that has been programmed to perform some level of autonomous behavior. Below is the essential “getting started” diagram that anyone in AI should recognize.
This opens up the ever present “robot vs. machine” debate that I don’t want to spent too much time on, but my personal distinction between a robot vs. a machine includes a couple of specifications.
A robot has at least one closed feedback loop between sensing and actuation that does not require human input. This discounts things like a remote-controlled car, or a machine that constantly executes a repetitive motion but will never recover if you nudge it slightly — think, for example, Theo Jansen’s kinetic sculptures.
A robot is an embodied agent that operates in the physical world. This discounts things like chatbots, or even smart speakers which — while awesome displays of artificial intelligence — I wouldn’t consider them to be robots… yet.
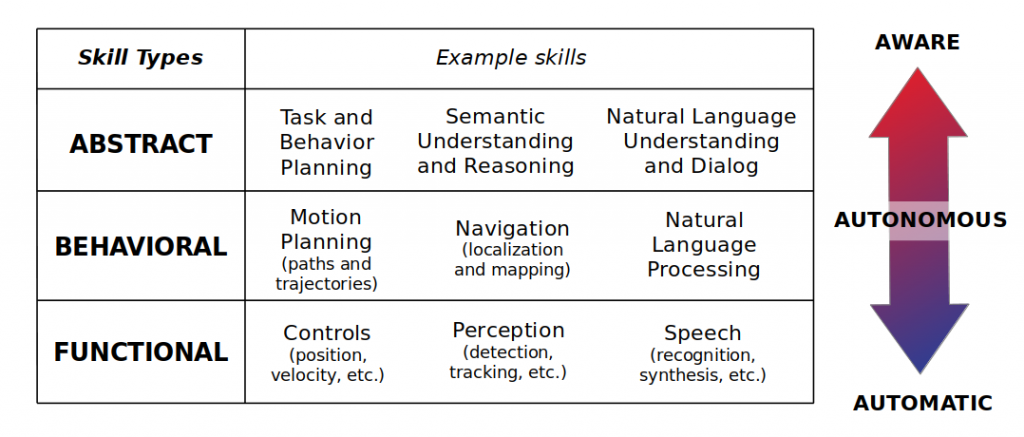
The big picture: Automatic, Autonomous, and Aware
Robots are not created equal. Not to say that simpler robots don’t have their purpose — knowing how simple or complex (technology- and budget-wise) to build a robot given the problem at hand is a true engineering challenge. To say it a different way: overengineering is not always necessary.
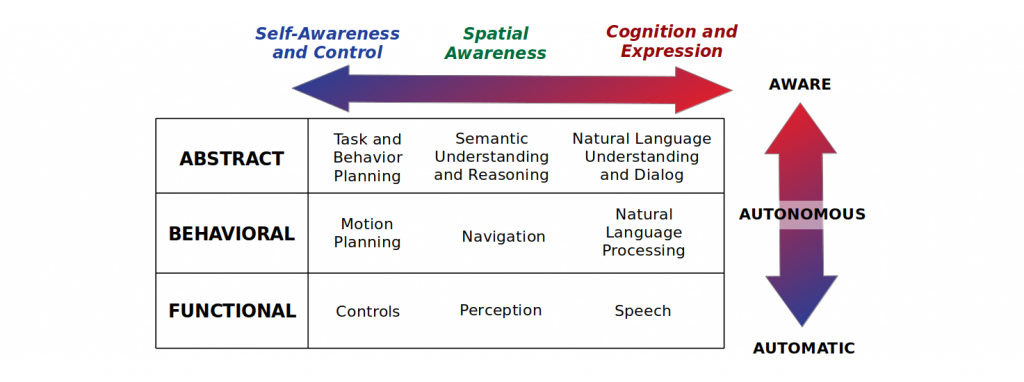
I will now categorize the capabilities of a robot into three bins: Automatic, Autonomous, and Aware. This roughly corresponds to how low- or high-level a robot’s skills have been developed, but it’s not an exact mapping as you will see.
Don’t worry too much about the details in the table as we will cover them throughout the post.
Automatic: The robot is controllable and it can execute motion commands provided by a human in a constrained environment. Think, for example, of industrial robots in an assembly line. You don’t need to program very complicated intelligence for a robot to put together a piece of an airplane from a fixed set of instructions. What you need is fast, reliable, and sustained operation. The motion trajectories of these robots are often trained and calibrated by a technician for a very specific task, and the surroundings are tailored for robots and humans to work with minimal or no conflict.
Autonomous: The robot can now execute tasks in an uncertain environment with minimal human supervision. One of the most pervasive example of this is self-driving cars (which I absolutely label as robots). Today’s autonomous vehicles can detect and avoid other cars and pedestrians, perform lane-change maneuvers, and navigate the rules of traffic with fairly high success rates despite the negative media coverage they may get for not being 100% perfect.
Aware: This gets a little bit into the “sci-fi” camp of robots, but rest assured that research is bringing this closer to reality day by day. You could tag a robot as aware when it can establish two-way communication with humans. An aware robot, unlike the previous two categories, is not only a tool that receives commands and makes mundane tasks easier, but one that is perhaps more collaborative. In theory, aware robots can understand the world at a higher level of abstraction than their more primitive counterparts, and process humans’ intentions from verbal or nonverbal cues, still under the general goal of solving a real-life problem.
A good example is a robot that can help humans assemble furniture. It operates in the same physical and task space as us humans, so it should adapt to where we choose to position ourselves or what part of the furniture we are working on without getting in the way. It can listen to our commands or requests, learn from our demonstrations, and tell us what it sees or what it might do next in language we understand so we can also take an active part in ensuring the robot is being used effectively.
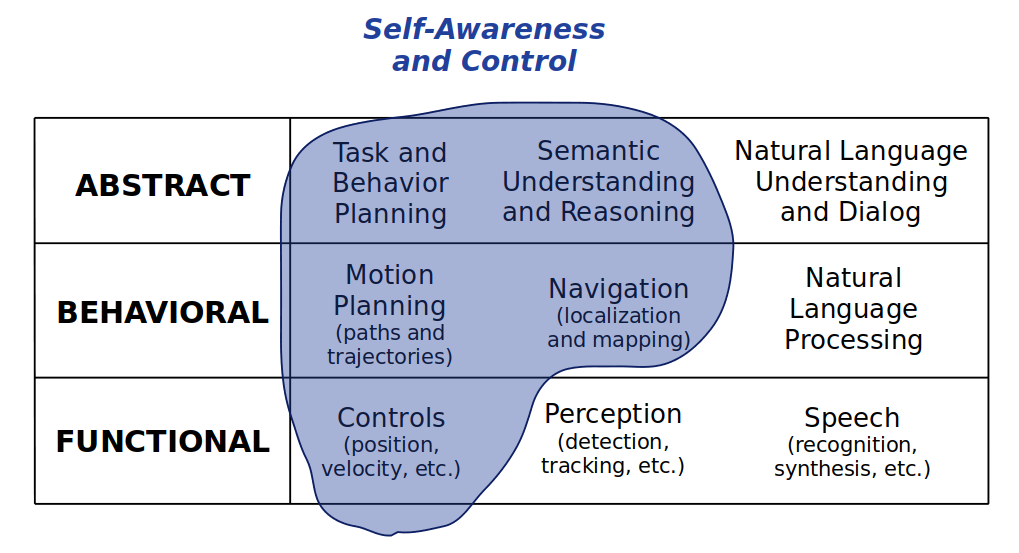
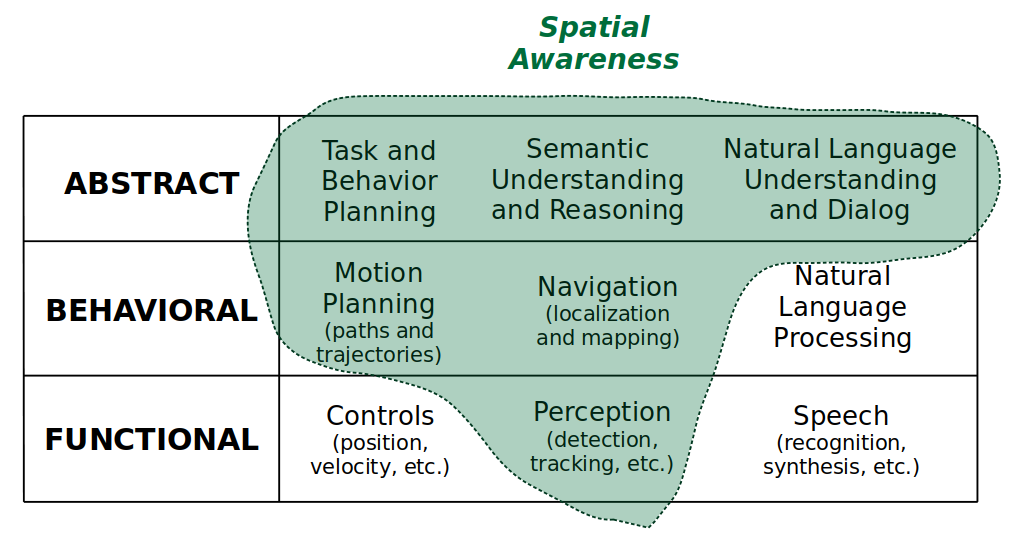
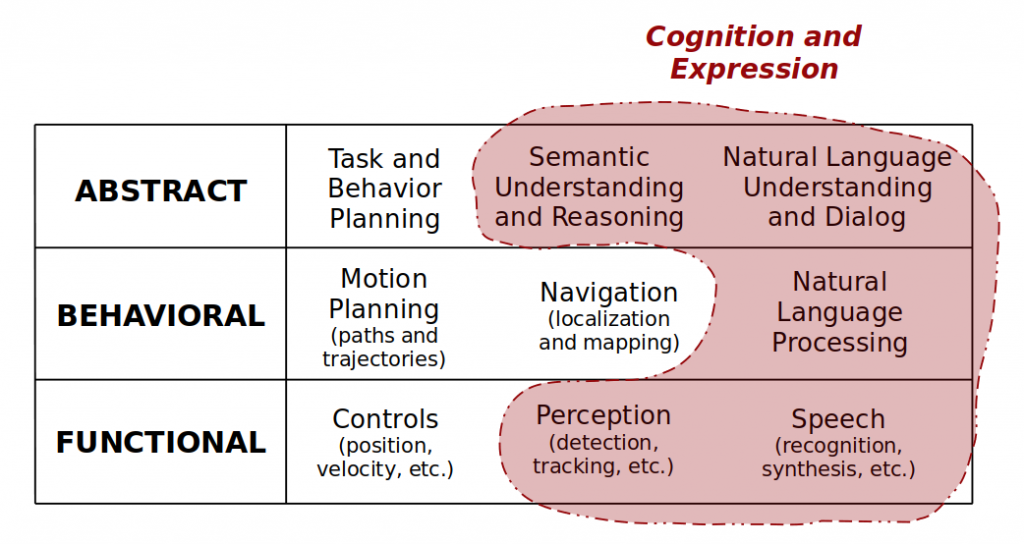
Self-awareness and control: How much does the robot know about itself?Spatial awareness: How much does the robot know about the environment and its own relationship to the environment?Cognition and expression: How capable is the robot about reasoning about the state of the world and expressing its beliefs and intentions to humans or other autonomous agents?
Above you can see a perpendicular axis of categorizing robot awareness. Each highlighted area represents the subset of skills it may require for a robot to achieve awareness on that particular dimension. Notice how forming abstractions — i.e., semantic understanding and reasoning — is crucial for all forms of awareness. That is no coincidence.
The most important takeaway as we move from automatic to aware is the increasing ability for robots to operate “in the wild”. Whereas an industrial robot may be designed to perform repetitive tasks with superhuman speed and strength, a home service robot will often sacrifice this kind of task-specific performance with more generalized skills needed for human interaction and navigating uncertain and/or unknown environments.
A Deeper Dive Into Robot Skills
Spinning up a robot requires a combination of skills at different levels of abstraction. These skills are all important aspects of a robot’s software stack and require vastly different areas of expertise. This goes back to the central point of this blog post: it’s not easy to build a highly capable robot, and it’s certainly not easy to do it alone!
Functional Skills
This denotes the low-level foundational skills of a robot. Without a robust set of functional skills, you would have a hard time getting your robot to be successful at anything else higher up the skill chain.
Being at the lowest level of abstraction, functional skills are closely tied to direct interaction with the actuators and sensor of the robot. Indeed, these skills can be discussed along the acting and sensing modalities.
Acting
Controls is all about ensuring the robot can reliably execute physical commands — whether this is a wheeled robot, flying robot, manipulator, legged robot, soft robot (… you get the point …) it needs to respond to inputs in a predictable way if it is to interact with the world. It’s a simple concept, but a challenging task that ranges from controlling electrical current/fluid pressure/etc. to multi-actuator coordination towards executing a full motion trajectory.
Speech synthesis acts on the physical world in a different way — this is more on the human-robot interaction (HRI) side of things. You can think of these capabilities as the robot’s ability to express its state, beliefs, and intentions in a way that is interpretable by humans. Imagine speech synthesis as more than speaking in a monotone robotic voice, but maybe simulating emotion or emphasis to help get information across to the human. This is not limited to speech. Many social robots will also employ visual cues like facial expressions, lights and colors, or movements — for example, look at MIT’s Leonardo.
Sensing
Controls requires some level of proprioceptive (self) sensing. To regulate the state of a robot, we need to employ sensors like encoders, inertial measurement units, and so on.
Perception, on the other hand, deals with exteroceptive (environmental) sensing. This mainly deals with line-of-sight sensors like sonar, radar, and lidar, as well as cameras. Perception algorithms require significant processing to make sense of a bunch of noisy pixels and/or distance/range readings. The act of abstracting this data to recognize and locate objects, track them over space and time, and use them for higher-level planning is what makes it exciting and challenging. Finally, back on the social robotics topic, vision can also enable robots to infer the state of humans for nonverbal communication.
Speech recognition is another form of exteroceptive sensing. Getting from raw audio to accurate enough text that the robot can process is not trivial, despite how easy smart assistants like Google Assistant, Siri, and Alexa have made it look. This field of work is officially known as automatic speech recognition (ASR).
Behavioral Skills
Behavioral skills are a step above the more “raw” sensor-to-actuator processing loops that we explored in the Functional Skills section. Creating a solid set of behavioral skills simplifies our interactions with robots both as users and programmers.
At the functional level, we have perhaps demonstrated capabilities for the robot to respond to very concrete, mathematical goals. For example,
Robot arm: “Move the elbow joint to 45 degrees and the shoulder joint to 90 degrees in less than 2.5 seconds with less than 10% overshoot. Then, apply a force of 2 N on the gripper.”
Autonomous car: “Speed up to 40 miles per hour without exceeding acceleration limit of 0.1 g and turn the steering wheel to attain a turning rate of 10 m.”
At the behavioral level, commands may take the form of:
Robot arm: “Grab the door handle.”
Autonomous car: “Turn left at the next intersection while following the rules of traffic and passenger ride comfort limits.”
Abstracting away these motion planning and navigation tasks requires a combination of models of the robot and/or world, and of course, our set of functional skills like perception and control.
Motion planning seeks to coordinate multiple actuators in a robot to execute higher-level tasks. Instead of moving individual joints to setpoints, we now employ kinematic and dynamic models of our robot to operate in the task space — for example, the pose of a manipulator’s end effector or the traffic lane a car occupies in a large highway. Additionally, to go from a start to a goal configuration requires path planning and a trajectory that dictates how to execute the planned path over time. I like this set of slides as a quick intro to motion planning.
Navigation seeks to build a representation of the environment (mapping) and knowledge of the robot’s state within the environment (localization) to enable the robot to operate in the world. This representation could be in the form of simple primitives like polygonal walls and obstacles, an occupancy grid, a high-definition map of highways, etc.
If this hasn’t yet got across, behavioral skills and functional skills definitely do not work in isolation. Motion planning in a space with obstacles requires perception and navigation. Navigating in a world requires controls and motion planning.
On the language side, Natural Language Processing (NLP) is what takes us from raw text input — whether it came from speech or directly typed in — to something more actionable for the robot. For instance, if a robot is given the command “bring me a snack from the kitchen”, the NLP engine needs to interpret this at the appropriate level to perform the task. Putting it all together,
Going to the kitchen is a navigation problem that likely requires a map of the house.
Locating the snack and getting its 3D position relative to the robot is a perception problem.
Picking up the snack without knocking other things over is a motion planning problem.
Returning to wherever the human was when the command was issued is again a navigation problem. Perhaps someone closed a door along the way, or left something in the way, so the robot may have to replan based on these changes to the environment.
Abstract Skills
Simply put, abstract skills are the bridge between humans and robot behaviors. All the skills in the row above perform some transformation that lets humans more easily express their commands to robots, and similarly lets robots more easily express themselves to humans.
Task and Behavior Planning operates on the key principles of abstraction and composition. A command like “get me a snack from the kitchen” can be broken down into a set of fundamental behaviors (navigation, motion planning, perception, etc.) that can be parameterized and thus generalized to other types of commands such as “put the bottle of water in the garbage”. Having a common language like this makes it useful for programmers to add capabilities to robots, and for users to leverage their robot companions to solve a wider set of problems. Modeling tools such as finite-state machines and behavior trees have been integral in implementing such modular systems.
Semantic Understanding and Reasoning is bringing abstract knowledge to a robot’s internal model of the world. For example, in navigation we saw that a map can be represented as “occupied vs. unoccupied”. In reality, there are more semantics that can enrich the task space of the robot besides “move here, avoid there”. Does the environment have separate rooms? Is some of the “occupied space” movable if needed? Are there elements in the world where objects can be stored and retrieved? Where are certain objects typically found such that the robot can perform a more targeted search? This recent paper from Luca Carlone’s group is a neat exploration into maps with rich semantic information, and a huge portal of future work that could build on this.
Natural Language Understanding and Dialog is effectively two-way communication of semantic understanding between humans and robots. After all, the point of abstracting away our world model was so we humans could work with it more easily. Here are examples of both directions of communication:
Robot-to-human: If a robot failed to execute a plan or understand a command, can it actually tell the human why it failed? Maybe a door was locked on the way to the goal, or the robot did not know what a certain word meant and it can ask you to define it.
Human-to-robot: The goal here is to share knowledge with the robot to enrich its semantic understanding the world. Some examples might be teaching new skills (“if you ever see a mug, grab it by the handle”) or reducing uncertainty about the world (“the last time I saw my mug it was on the coffee table”).
This is all a bit of a pipe dream — Can a robot really be programmed to work with humans at such a high level of interaction? It’s not easy, but research tries to tackle problems like these every day. I believe a good measure of effective human-robot interaction is whether the human and robot jointly learn not to run into the same problem over and over, thus improving the user experience.
Conclusion
Thanks for reading, even if you just skimmed through the pictures. I hope this was a useful guide to navigating robotic systems that was somewhat worth its length. As I mentioned earlier, no categorization is perfect and I invite you to share your thoughts.
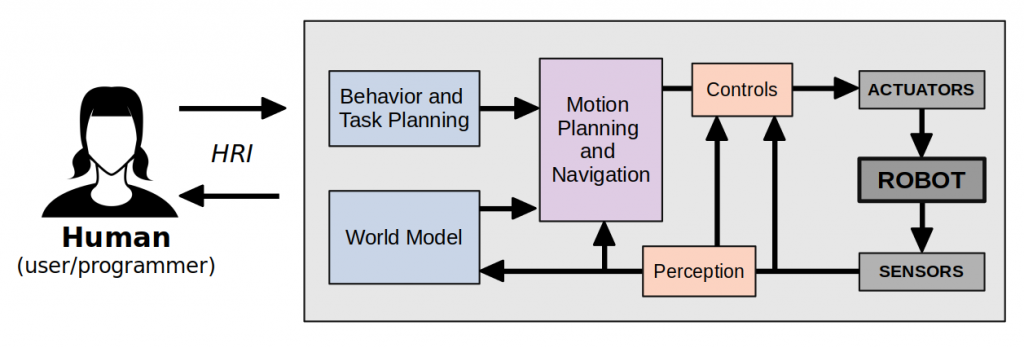
Going back to one of my specifications: A robot has at least one closed feedback loop between sensing and actuation that does not require human input. Let’s try put our taxonomy in an example set of feedback loops below. Note that I’ve condensed the natural language pipeline into the “HRI” arrows connecting to the human.
Example of a hierarchical robotic system architecture. Icons made by Freepik from www.flaticon.com
Because no post today can evade machine learning, I also want to take some time make readers aware of machine learning’s massive role in modern robotics.
Processing vision and audio data has been an active area of research for decades, but the rise of neural networks as function approximators for machine learning (i.e. “deep learning”) has made recent perception and ASR systems more capable than ever.
Additionally, learning has demonstrated its use at higher levels of abstraction. Text processing with neural networks has moved the needle on natural language processing and understanding. Similarly, neural networks have enabled end-to-end systems that can learn to produce motion, task, and/or behavior plans from complex observation sources like images and range sensors.
The truth is, our human knowledge is being outperformed by machine learning for processing such high-dimensional data. Always remember that machine learning shouldn’t be a crutch due to its biggest pitfall: We can’t (yet) explain why learned systems behave the way they do, which means we can’t (yet) formulate the kinds guarantees than we can with traditional methods. The hope is to eventually refine our collective scientific knowledge so we’re not relying on data-driven black-box approaches. After all, knowing how and why robots learn will only make them more capable in the future.
On that note, you have earned yourself a break from reading. Until next time!
Researchers of the Integrated Systems Engineering Group of the University of Malaga (UMA) have designed a telepresence robot that enables people suffering from COVID-19 to talk to their loved ones.
Spending on global offshore renewable energy infrastructure over the next ten years is expected to reach over US$16 billion (£11.3bn). This involves creating an extra 2.5 million kilometers of global submarine cables by 2030.
Retrofit machines can bring legacy devices into the Internet of Things. Sensors and digital controls provide valuable information and integrate older machines into new, intelligent factory management systems.