Computer scientists at the University of California San Diego have developed a more accurate navigation system that will allow robots to better negotiate busy clinical environments in general and emergency departments more specifically. The researchers have also developed a dataset of open source videos to help train robotic navigation systems in the future.
Robots and machines are getting smarter with the advancement of artificial intelligence, but they still lack the ability to touch and feel their subtle and complex surroundings like human beings. Now, researchers from the National University of Singapore (NUS) have invented a smart foam that can give machines more than a human touch.
Valet Market is a new way for consumers to shop for everyday items. They simply download the app and use their phone to check in to the store. Once inside, shoppers can select desired items and walk out without having to wait in line to check out.
Where there is e-commerce, there is inevitably logistics management. After all, what could be more efficient than a network-connected fleet of AGVs to travel around huge warehouses and find the required product in record time?
A small study found that people who were touched by a humanoid robot while conversing with it subsequently reported a better emotional state and were more likely to comply with a request from the robot. Laura Hoffmann of Ruhr University Bochum, Germany, and Nicole C. Krämer of the University of Duisburg-Essen, Germany, present these findings in the open-access journal PLOS ONE on May 5, 2021.
Reflexes protect our bodies—for example when we pull our hand back from a hot stove. These protective mechanisms could also be useful for robots. In this interview, Prof. Sami Haddadin and Johannes Kühn of the Munich School of Robotics and Machine Intelligence (MSRM) of the Technical University of Munich (TUM) explain why giving test subjects a 'slap on the hand' could lay the foundations for the robots of the future.
The Boxed Bot is extremely flexible, allowing an operator to design and produce exact pallet patterns quickly and easily from bags to boxes and other product types, and does so with a small footprint starting at just 8’x10’.
The deepest regions of the oceans still remain one of the least explored areas on Earth, despite their considerable scientific interest and the richness of lifeforms inhabiting them.
Two reasons for this are the low temperatures and enormous pressures exerted at such depths, which require the exploration equipment be carefully shielded inside high-strength metal or ceramic chambers to withstand them. This makes deep-sea exploration vessels bulky, expensive and unwieldy, as well as difficult to design, manufacture and transport.
But a new small self-powered underwater robotic fish appears to offer an alternative. According to a recent paper, the robot was able to reach the deepest part of the Pacific Ocean – the Mariana Trench – at a depth of almost 11 km (6.8 miles).
The pressure there is more than a thousand times that on the surface of the sea. Yet various animals, including fish, are able to withstand this staggering pressure and have adapted to life in such adverse conditions. The morphology and skull structure of one of these marine organisms, the hadal snailfish, reportedly inspired the design of this remarkable robot swimmer.
The main breakthrough that enabled this significant achievement was a specially-designed compliant polymer body which deforms, without breaking, under high pressure. The team of researchers from Hangzhou in China were able to embed the delicate electronic components required for power, movement and control in a protective silicone matrix.
The electronic components were separated from each other, instead of being tightly packed together as is the usual practice, to make them more resilient to the pressure, similar to the skull bones of the snailfish.
The robot also looks like the snailfish, with an elongated body and tail, as well as two large side fins made of thin silicone. The fins flap to propel the small robot, which measures only 22cm (8.7 inches) in length with a wingspan of 28cm.
The fins are not operated by rigid motors, but by soft artificial muscles. The muscles contain dielectric elastomers – a class of smart materials which contract when electrical voltage is applied to create large movements.
Disk-shaped dielectric elastomer elements create the fin flapping motion that propels the robot, reaching speeds of up to about half a body-length per second (around 0.2 km/h), even at significant depths.
However, this type of actuators – the parts that make a machine move – requires very high voltage. A compact high-voltage amplifier multiplies the lithium-ion battery voltage more than a thousand times to meet this requirement, while an infrared receiver allows remote control of the robot. The soft fins and soft actuators were carefully designed to survive and perform well at the low temperatures and high pressures of the deep-sea environment.
Free swimming in the deep lake.
The team performed extensive computational studies and laboratory testing of the propulsion methodology and of how the electronics cope under extreme pressures. Then, they conducted free-swimming field tests, first in a deep lake, then at the South China Sea at depths of more than 3km, before deploying it in the Mariana Trench.
In the Mariana field tests, the robot was mounted on a deep-sea lander, so wasn’t allowed to swim freely. But, it was able to maintain its flapping motion, as recorded by the cameras of the lander, for 45 minutes at a depth of 10,900 metres.
Soft robots
This deep-sea swimmer is an example of a new generation of robots inspired by living organisms, both animals and plants. They are built exploiting the advantages of compliant materials like silicone and other polymers, gels or even textiles.
These robots can bend, yield and adapt in response to forces from their environment, so are inherently safer to work next to humans compared to the typical rigid industrial robots. On the other hand, their design, actuation, sensing and control can pose significant challenges, which lie at the core of their scientific and technological interest.
Flapping in the Mariana trench.
There is currently intense interdisciplinary research activity in this new area, called soft robotics, leading to exciting innovative advances for a host of related applications, ranging from agriculture to medicine and space. The Harvard Octobot is an example of this class of robots, which appears to have been, among others, a source of inspiration for the design and the technologies employed in this deep-sea robot.
The current version of the deep-sea swimmer appears to be relatively slow, not very easy to manoeuvre, and possibly not able to withstand the strong underwater currents which would disturb its course while attempting to follow a desired path. However, its designers already seem to have plans for further improvements that will make it more manoeuvrable, more efficient and smarter.
Despite any shortcomings, we should not underestimate the robotic design principles and technological advances that led to such a dramatic demonstration.
Dimitris Tsakiris has received funding from HEFCW, CRUK, and EC/EU.
Choosing a robot integrator is like choosing a business partner. You must find one with the capabilities you need to be successful; one who understands your business and your integration goals.
With rapidly growing demands on health care systems, nurses typically spend 18 to 40 percent of their time performing direct patient care tasks, oftentimes for many patients and with little time to spare. Personal care robots that brush your hair could provide substantial help and relief.
With rapidly growing demands on health care systems, nurses typically spend 18 to 40 percent of their time performing direct patient care tasks, oftentimes for many patients and with little time to spare. Personal care robots that brush your hair could provide substantial help and relief.
When it comes to dancing, pulling a sled, climbing stairs or doing tricks, "Spot" is definitely a good dog. It can navigate the built environment and perform a range of tasks, clearly demonstrating its flexibility as a software and hardware platform for commercial use.
The disinfection robot BALTO—named after a sled dog who carried urgently needed vaccines to a highly inaccessible region of Alaska a hundred years ago—is capable of disinfecting door knobs and similar objects. It does this autonomously, reacting to human beings in the surrounding area at the same time. An interface with the Building Information Modeling (BIM) process makes this possible.
The manufacturer of the robot processing cell is the Zimmer Group from Rheinau in Germany. On its way towards Industry 4.0, the Zimmer Group has evolved from a classic component supplier to a system provider and has thus produced an entire robotic cell at once.
The double helix of DNA is one of the most iconic symbols in science. By imitating the structure of this complex genetic molecule we have found a way to make artificial muscle fibres far more powerful than those found in nature, with potential applications in many kinds of miniature machinery such as prosthetic hands and dextrous robotic devices.
The power of the helix
DNA is not the only helix in nature. Flip through any biology textbook and you’ll see helices everywhere from the alpha-helix shapes of individual proteins to the “coiled coil” helices of fibrous protein assemblies like keratin in hair.
Some bacteria, such as spirochetes, adopt helical shapes. Even the cell walls of plants can contain helically arranged cellulose fibres.
Muscle tissue too is composed of helically wrapped proteins that form thin filaments. And there are many other examples, which poses the question of whether the helix endows a particular evolutionary advantage.
Many of these naturally occurring helical structures are involved in making things move, like the opening of seed pods and the twisting of trunks, tongues and tentacles. These systems share a common structure: helically oriented fibres embedded in a squishy matrix which allows complex mechanical actions like bending, twisting, lengthening and shortening, or coiling.
This versatility in achieving complex shapeshifting may hint at the reason for the prevalence of helices in nature.
Fibres in a twist
Ten years ago my work on artificial muscles brought me to think a lot about helices. My colleagues and I discovered a simple way to make powerful rotating artificial muscle fibres by simply twisting synthetic yarns.
These yarn fibres could rotate by untwisting when we expanded the volume of the yarn by heating it, making it absorb small molecules, or by charging it like a battery. Shrinking the fibre caused the fibres to re-twist.
We demonstrated that these fibres could spin a rotor at speeds of up to 11,500 revolutions per minute. While the fibres were small, we showed they could produce about as much torque per kilogram as large electric motors.
The key was to make sure the helically arranged filaments in the yarn were quite stiff. To accommodate an overall volume increase in the yarn, the individual filaments must either stretch in length or untwist. When the filaments are too stiff to stretch, the result is untwisting of the yarn.
Learning from DNA
More recently, I realised DNA molecules behave like our untwisting yarns. Biologists studying single DNA molecules showed that double-stranded DNA unwinds when treated with small molecules that insert themselves inside the double helix structure.
The backbone of DNA is a stiff chain of molecules called sugar phosphates, so when the small inserted molecules push the two strands of DNA apart the double helix unwinds. Experiments also showed that, if the ends of the DNA are tethered to stop them rotating, the untwisting leads to “supercoiling”: the DNA molecule forms a loop that wraps around itself.
In fact, special proteins induce coordinated supercoiling in our cells to pack DNA molecules into the tiny nucleus.
We also see supercoiling in everyday life, for example when a garden hose becomes tangled. Twisting any long fibre can produce supercoiling, which is known as “snarling” in textiles processing or “hockling” when cables become snagged.
Supercoiling for stronger ‘artificial muscles’
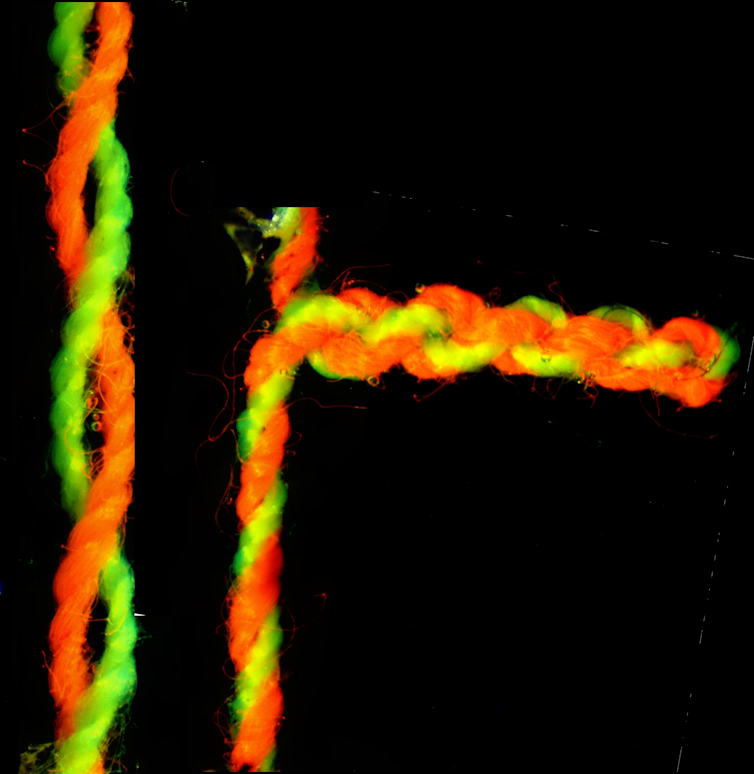
Our latest results show DNA-like supercoiling can be induced by swelling pre-twisted textile fibres. We made composite fibres with two polyester sewing threads, each coated in a hydrogel that swells up when it gets wet and then the pair twisted together.
Swelling the hydrogel by immersing it in water caused the composite fibre to untwist. But if the fibre ends were clamped to stop untwisting, the fibre began to supercoil instead.
An untwisted fibre (left) and the supercoiled version (right). Geoff Spinks, Author provided
As a result, the fibre shrank by up to 90% of its original length. In the process of shrinking, it did mechanical work equivalent to putting out 1 joule of energy per gram of dry fibre.
For comparison, the muscle fibres of mammals like us only shrink by about 20% of their original length and produce a work output of 0.03 joules per gram. This means that the same lifting effort can be achieved in a supercoiling fibre that is 30 times smaller in diameter compared with our own muscles.
Why artificial muscles?
Artificial muscle materials are especially useful in applications where space is limited. For example, the latest motor-driven prosthetic hands are impressive, but they do not currently match the dexterity of a human hand. More actuators are needed to replicate the full range of motion, grip types and strength of a healthy human.
Electric motors become much less powerful as their size is reduced, which makes them less useful in prosthetics and other miniature machines. However, artificial muscles maintain a high work and power output at small scales.
To demonstrate their potential applications, we used our supercoiling muscle fibres to open and close miniature tweezers. Such tools may be part of the next generation of non-invasive surgery or robotic surgical systems.
Many new types of artificial muscles have been introduced by researchers over the past decade. This is a very active area of research driven by the need for miniaturised mechanical devices. While great progress has been made, we still do not have an artificial muscle that completely matches the performance of natural muscle: large contractions, high speed, efficiency, long operating life, silent operation and safe for use in contact with humans.
The new supercoiling muscles take us one step closer to this goal by introducing a new mechanism for generating very large contractions. Currently our fibres operate slowly, but we see avenues for greatly increasing the speed of response and this will be the focus for ongoing research.
Geoff Spinks does not work for, consult, own shares in or receive funding from any company or organisation that would benefit from this article, and has disclosed no relevant affiliations beyond their academic appointment.