
MIT engineers are hoping to help doctors tailor treatments to patients’ specific heart form and function, with a custom robotic heart. The team has developed a procedure to 3D print a soft and flexible replica of a patient’s heart. Image: Melanie Gonick, MIT
By Jennifer Chu | MIT News Office
No two hearts beat alike. The size and shape of the the heart can vary from one person to the next. These differences can be particularly pronounced for people living with heart disease, as their hearts and major vessels work harder to overcome any compromised function.
MIT engineers are hoping to help doctors tailor treatments to patients’ specific heart form and function, with a custom robotic heart. The team has developed a procedure to 3D print a soft and flexible replica of a patient’s heart. They can then control the replica’s action to mimic that patient’s blood-pumping ability.
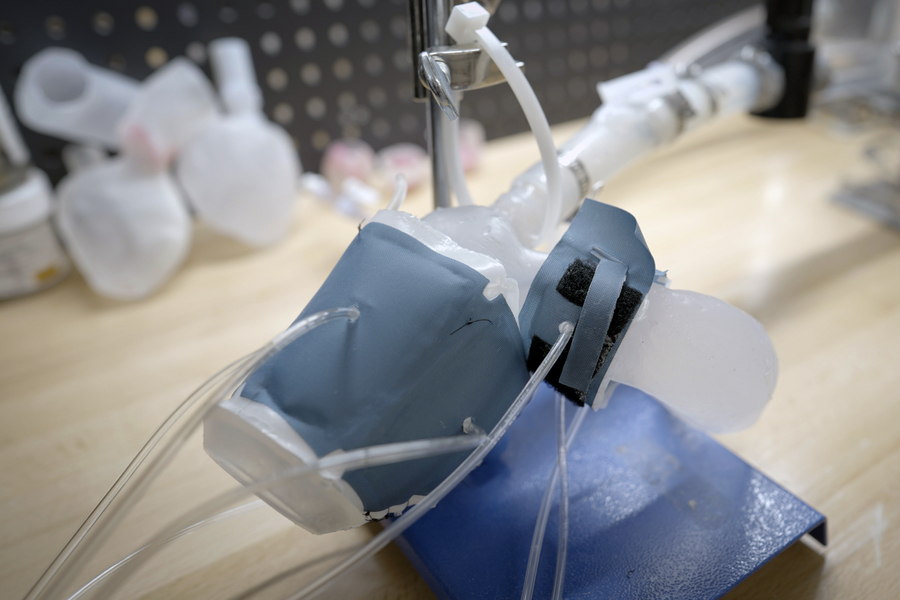
The procedure involves first converting medical images of a patient’s heart into a three-dimensional computer model, which the researchers can then 3D print using a polymer-based ink. The result is a soft, flexible shell in the exact shape of the patient’s own heart. The team can also use this approach to print a patient’s aorta — the major artery that carries blood out of the heart to the rest of the body.
To mimic the heart’s pumping action, the team has fabricated sleeves similar to blood pressure cuffs that wrap around a printed heart and aorta. The underside of each sleeve resembles precisely patterned bubble wrap. When the sleeve is connected to a pneumatic system, researchers can tune the outflowing air to rhythmically inflate the sleeve’s bubbles and contract the heart, mimicking its pumping action.
The researchers can also inflate a separate sleeve surrounding a printed aorta to constrict the vessel. This constriction, they say, can be tuned to mimic aortic stenosis — a condition in which the aortic valve narrows, causing the heart to work harder to force blood through the body.
Doctors commonly treat aortic stenosis by surgically implanting a synthetic valve designed to widen the aorta’s natural valve. In the future, the team says that doctors could potentially use their new procedure to first print a patient’s heart and aorta, then implant a variety of valves into the printed model to see which design results in the best function and fit for that particular patient. The heart replicas could also be used by research labs and the medical device industry as realistic platforms for testing therapies for various types of heart disease.
“All hearts are different,” says Luca Rosalia, a graduate student in the MIT-Harvard Program in Health Sciences and Technology. “There are massive variations, especially when patients are sick. The advantage of our system is that we can recreate not just the form of a patient’s heart, but also its function in both physiology and disease.”
Rosalia and his colleagues report their results in a study appearing in Science Robotics. MIT co-authors include Caglar Ozturk, Debkalpa Goswami, Jean Bonnemain, Sophie Wang, and Ellen Roche, along with Benjamin Bonner of Massachusetts General Hospital, James Weaver of Harvard University, and Christopher Nguyen, Rishi Puri, and Samir Kapadia at the Cleveland Clinic in Ohio.
Print and pump
In January 2020, team members, led by mechanical engineering professor Ellen Roche, developed a “biorobotic hybrid heart” — a general replica of a heart, made from synthetic muscle containing small, inflatable cylinders, which they could control to mimic the contractions of a real beating heart.
Shortly after those efforts, the Covid-19 pandemic forced Roche’s lab, along with most others on campus, to temporarily close. Undeterred, Rosalia continued tweaking the heart-pumping design at home.
“I recreated the whole system in my dorm room that March,” Rosalia recalls.
Months later, the lab reopened, and the team continued where it left off, working to improve the control of the heart-pumping sleeve, which they tested in animal and computational models. They then expanded their approach to develop sleeves and heart replicas that are specific to individual patients. For this, they turned to 3D printing.
“There is a lot of interest in the medical field in using 3D printing technology to accurately recreate patient anatomy for use in preprocedural planning and training,” notes Wang, who is a vascular surgery resident at Beth Israel Deaconess Medical Center in Boston.
An inclusive design
In the new study, the team took advantage of 3D printing to produce custom replicas of actual patients’ hearts. They used a polymer-based ink that, once printed and cured, can squeeze and stretch, similarly to a real beating heart.
As their source material, the researchers used medical scans of 15 patients diagnosed with aortic stenosis. The team converted each patient’s images into a three-dimensional computer model of the patient’s left ventricle (the main pumping chamber of the heart) and aorta. They fed this model into a 3D printer to generate a soft, anatomically accurate shell of both the ventricle and vessel.
The action of the soft, robotic models can be controlled to mimic the patient’s blood-pumping ability. Image: Melanie Gonick, MIT
The team also fabricated sleeves to wrap around the printed forms. They tailored each sleeve’s pockets such that, when wrapped around their respective forms and connected to a small air pumping system, the sleeves could be tuned separately to realistically contract and constrict the printed models.
The researchers showed that for each model heart, they could accurately recreate the same heart-pumping pressures and flows that were previously measured in each respective patient.
“Being able to match the patients’ flows and pressures was very encouraging,” Roche says. “We’re not only printing the heart’s anatomy, but also replicating its mechanics and physiology. That’s the part that we get excited about.”
Going a step further, the team aimed to replicate some of the interventions that a handful of the patients underwent, to see whether the printed heart and vessel responded in the same way. Some patients had received valve implants designed to widen the aorta. Roche and her colleagues implanted similar valves in the printed aortas modeled after each patient. When they activated the printed heart to pump, they observed that the implanted valve produced similarly improved flows as in actual patients following their surgical implants.
Finally, the team used an actuated printed heart to compare implants of different sizes, to see which would result in the best fit and flow — something they envision clinicians could potentially do for their patients in the future.
“Patients would get their imaging done, which they do anyway, and we would use that to make this system, ideally within the day,” says co-author Nguyen. “Once it’s up and running, clinicians could test different valve types and sizes and see which works best, then use that to implant.”
Ultimately, Roche says the patient-specific replicas could help develop and identify ideal treatments for individuals with unique and challenging cardiac geometries.
“Designing inclusively for a large range of anatomies, and testing interventions across this range, may increase the addressable target population for minimally invasive procedures,” Roche says.
This research was supported, in part, by the National Science Foundation, the National Institutes of Health, and the National Heart Lung Blood Institute.
- PAPER – Soft robotic patient-specific hydrodynamic model of aortic stenosis and ventricular remodeling. Luca Rosalia, Caglar Ozturk, Debkalpa Goswami, Jean Bonnemain, Sophie X. Wang, Benjamin Bonner, James C. Weaver, Rishi Puri, Samir Kapadia, Christopher T. Nguyen, and Ellen T. Roche. Science Robotics, 8 (75).
