As both an industry and an entire class of technology, robotics changes and advances rapidly. Whether as a hobbyist or seasoned robotics engineer, you need to know each component inside and out. You should also know how to choose between several different variations.
The fourth Industrial Revolution, Industry 4.0, has seen telematics and automation come together. Here’s a closer look at the intersection of these two innovations.
Robopets are artificially intelligent machines created to look like an animal (usually a cat or dog, but they can be any animal). There are numerous robopets on the market right now, being sold to consumers as "pets" or companions. There is an especially fervent effort being made to set caregivers' minds at ease by buying these robopets for older adults to replace their deceased or surrendered companion animals.
Robopets are artificially intelligent machines created to look like an animal (usually a cat or dog, but they can be any animal). There are numerous robopets on the market right now, being sold to consumers as "pets" or companions. There is an especially fervent effort being made to set caregivers' minds at ease by buying these robopets for older adults to replace their deceased or surrendered companion animals.
Engineers at UC Riverside have unveiled an air-powered computer memory that can be used to control soft robots. The innovation overcomes one of the biggest obstacles to advancing soft robotics: the fundamental mismatch between pneumatics and electronics. The work is published in the open-access journal, PLOS One.
A team of researchers from the University of Maryland has 3D printed a soft robotic hand that is agile enough to play Nintendo's Super Mario Bros. - and win!
Amazon Inc. has applied for a patent on a package delivery system that involves a primary vehicle for carrying packages destined for multiple drop-off points, and a secondary, much smaller, delivery vehicle that carries packages from the primary vehicle to the end-point destination.
Neuro-evolutionary robotics is an attractive approach to realize collective behaviors for swarms of robots. Despite the large number of studies that have been devoted to it and although many methods and ideas have been proposed, empirical evaluations and comparative analyses are rare.
On July 1st Zebra Technologies announced that it would be acquiring Fetch Robotics. It will be paying $290 million to acquire the 95% of the company that it does not already own, in a deal that values Fetch Robotics at $305 million.
The opportunities, conditions and business advantages offered by properly functioning collaborative automation solutions have never been more attractive, while the technology is also more accessible than ever.
Tiny drones are ideal candidates for fully autonomous jobs that are too dangerous or time-consuming for humans. A commonly shared dream by engineers and fire & rescue services, would be to have swarms of such drones help in search-and-rescue scenarios [1], for instance to localize gas leaks without endangering human lives. Tiny drones are ideal for such tasks, since they are small enough to navigate in narrow spaces, safe, agile, and very inexpensive. However, their small footprint also makes the design of an autonomous swarm extremely challenging, both from a software and hardware perspective.
From a software perspective, it is really challenging to come up with an algorithm capable of autonomous and collaborative navigation within such tight resource constraints. State-of-the-art solutions like Simultaneous Localization and Mapping (SLAM) require too much memory and processing power. A promising line of work is to use bug algorithms [2], which can be implemented as computationally efficient finite state machines (FSMs), and can navigate around obstacles without requiring a map.
A downside of using FSMs is that the resulting behavior can be very sensitive to their hyperparameters, and therefore may not generalize outside of the tested environments. This is especially true for the problem of gas source localization (GSL), as wind conditions and obstacle configurations drastically change the problem. In this article, we show how we tackled the complex problem of swarm GSL in cluttered environments by using a simple bug algorithm with evolved parameters, and then tested it onboard a fully autonomous swarm of tiny drones. We will focus on the problems that were encountered along the way, and the design choices we made as a result. At the end of this post, we will also add a short discussion about the future of tiny drones.
Why gas source localization?
Overall we are interested in finding novel ways to enable autonomy on constrained devices, like tiny drones. Two years ago, we showed that a swarm of tiny drones was able to explore unknown, cluttered environments and come back to the base station. Since then, we have been working on an even more complex task: using such a swarm for Gas Source Localization (GSL).
There has been a lot of research focussing on autonomous GSL in robotics, since it is an important but very hard problem [3]. The difficulty of the task comes from the complexity of how odor can spread in an environment. In an empty room without wind, a gas will slowly diffuse from the source. This allows a robot to find the source by simply moving in the direction that makes the gas concentration go up, just like small bacteria like E. Coli do to find nutrients. However, if the environment becomes larger with many obstacles and walls, and wind comes into play, the spreading of gas is much less regular. Large parts of the environment may have no gas or wind at all, while at the same time there may be pockets of gas away from the source. Moreover, chemical sensors for robots are much less capable than the smelling organs of animals. Available chemical sensors for robots are typically less sensitive, noisier, and much slower.
Due to these difficulties, most work in the GSL field has focused on a single robot that has to find a gas source in environments that are relatively small and without obstacles. Relatively recently, there have been studies in which groups of robots solve this task in a collaborative fashion, for example with Particle Swarm Optimization (PSO). PSO was first invented as a way to model the social behavior of foraging birds, in which the birds communicate with each other how good the food at their location is. The birds then follow a direction that is determined both by their own observations and the best observed location of the swarm. PSO turned out to be a great optimization algorithm for many different real-world problems. Thanks to the different particles in the swarm, it can escape local optima. In the case of GSL, PSO allows a swarm of robots to collaboratively seek a gas source, while ignoring pockets of gas away from the gas source. Until now this concept has been shown in simulation [4] and on large outdoor drones equipped with LiDAR and GPS [5], but never before on tiny drones in complex, GPS-denied, indoor environments.
Required Infrastructure
In our project, we introduce a new bug algorithm, Sniffy Bug, which uses PSO for gas source localization. In order to tune the FSM of Sniffy Bug, we used an evolutionary algorithm. This type of algorithm mimics the survival of the fittest in natural evolution, but now with “fitness” defined as being able to localize a gas source as efficiently as possible. The evolution starts out with random controllers for the swarm of robots, evaluates them in simulation, and selects the fittest controllers for reproduction. Over the generations, the controllers become increasingly good at the task. After evolution, the best controller is transferred to the real robots in the swarm.
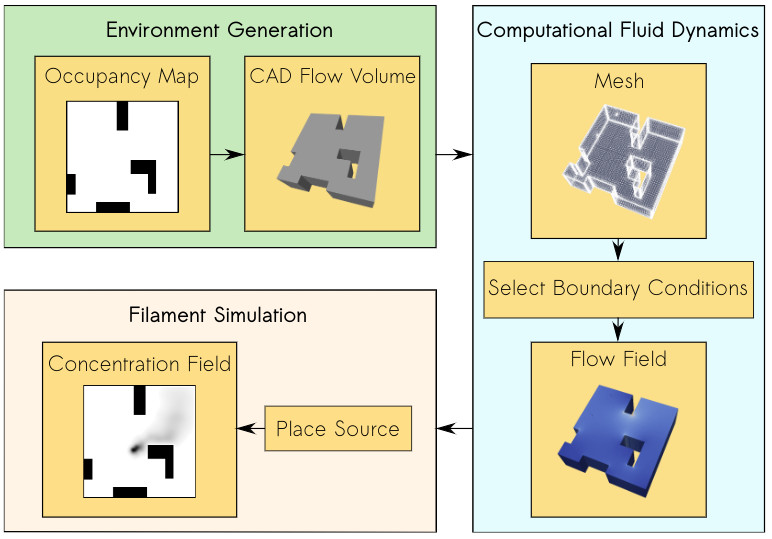
Of course, for this evolution to work well, we need a good simulation of how gas spreads in a complex, indoor environment. However, early in the project, we realized that this would be a challenge, as no end-to-end gas modeling pipeline existed yet. It is important to have an easy-to-use pipeline that does not require any aerodynamics domain knowledge, such that as many researchers as possible can generate environments to test their algorithms. It would also make it easier to compare contributions and to better understand in which conditions certain algorithms work or don’t work. The GADEN ROS package [6] is a great open source tool for modelling gas distribution when you have an environment and flow field, but for our objective, we needed a fully automated tool that could generate a great variety of random environments on-demand with just a few parameters. Below is an overview of our simulation pipeline: AutoGDM.
AutoGDM, a fully automated gas dispersion modeling (GDM) simulation pipeline.
First, we use a procedural environment generator proposed in [7] to generate random walls and obstacles inside of the environment. Then, gas dispersion modeling (GDM) is done by first modeling a 3D flow field, i.e., the direction and magnitude of wind velocity at every point in space. Next, a gas source location is chosen. Then, at the source, gas filaments are released in the flow field and randomly expanded over time. This results in a time-varying gas concentration field. The 3D flow field is heavily impacted by something referred to as “boundary conditions”: the conditions at the walls in the environment that we feed into the computational fluid dynamics (CFD) solver. In our case, this means for some walls we tell the CFD to force a wind velocity of 0 m/s, while for others we may tell it to model an inlet or an outlet of air, like an open window. Determining the boundary conditions is done automatically by AutoGDM.
Since a hard requirement for us was that AutoGDM needed to be free to use, we chose to use the open-source CFD tool OpenFOAM. It’s used for cutting-edge aerodynamics research, and also the tool suggested by the authors of GADEN. Without AutoGDM, using OpenFOAM isn’t trivial, as a large number of parameters that require field expertise need to be selected, resulting in a complicated process. GADEN was used to take the environment definition (CAD files) and the flow field from OpenFOAM to generate the gas concentration field over time.
After we built this pipeline, we still needed a robot simulator. Since we weren’t planning on using a camera, our main requirement was for the simulator to be efficient (preferably in 2D) so that evolutions would take relatively little time. We decided to use Swarmulator [8], a computationally efficient C++ robot simulator designed for swarming and we plugged in our gas data.
Algorithm Design
Roughly speaking, we considered two categories of algorithms for controlling the drones: 1) a neural network, and 2) an FSM that included PSO, with evolved parameters. We first evolved neural networks in simulation. One of the first experiments is shown below.
A single agent in simulation seeking a gas source using a tiny neural network.
While it worked pretty well in simple environments with few obstacles, it seemed challenging to make this work in real life with complex obstacles and multiple agents that need to collaborate. Given the time constraints of the project, we opted for evolving the FSM. This also facilitated crossing the reality gap (i.e., the difference between simulation and real-world behaviour), as the simulated evolution could build on basic behaviors that we developed and validated on the real platform, including obstacle avoidance with four tiny laser rangers, while communicating with and avoiding other drones. An additional advantage of PSO with respect to the reality gap is that it only needs gas concentration and no gradient of the gas concentration or wind direction (which many algorithms in literature use). On a real robot at this scale, estimating the gas concentration gradient or the direction of a light breeze is hard if not impossible.
Hardware
We deploy a 37.5g Bitcraze CrazyFlie nano drone that is capable of avoiding obstacles, executing velocity commands, sensing gas, and estimating the other agent’s position in its own frame. For navigation we added a down-facing optic flow sensor and four laser rangers, whereas for gas sensing we used a TGS8100 gas sensor that was used on a CrazyFlie before in previous work [9]. The sensor is lightweight and inexpensive, but accurately estimating gas concentrations can be difficult because of its size. It tends to drift and needs time to recover after a spike in concentration is observed. Another thing we noticed is that it is possible to break them, a crash can definitely destroy the sensor.
To estimate the relative position between agents, we use a Decawave Ultra-Wideband (UWB) module and communicate states, as proposed in [10]. We also use the UWB module to communicate gas information between agents and collaboratively seek the source. The complete configuration is visible below.
A 37.5 g nano quadcopter, capable of fully autonomous waypoint tracking, obstacle avoidance, relative localization, communication and gas sensing.
Evaluation in Simulation
After we optimized the parameters of our model using Swarmulator and AutoGDM, and of course trying many different versions of our algorithm, we ended up with the final Sniffy Bug algorithm. Below is a video that shows evolved Sniffy Bug evaluated in six different environments.
The red dots are an agent’s personal target waypoint, whereas the yellow dot is the best-known position for the swarm. Simulation shows that Sniffy Bug is effective at locating the gas source in randomly generated environments. The drones successfully collaborate by means of PSO.
Real Flight Testing
After observing Sniffy Bug in simulation we were optimistic, but unsure about performance in real life. First, inspired by previous works, we dispersed alcohol through the air by placing liquid alcohol into a can which was then dispersed using a computer fan.
Dispersion of liquid alcohol in flight tests.
We tested Sniffy Bug in our flight arena of size 10 x 10 meters with large obstacles that were shaped like walls and orange poles. The image below shows four flight tests of Sniffy Bug in cluttered environments, flying fully autonomously, i.e., without the help from any external infrastructure.
Time-lapse images of real-world experiments in our flight arena. Sniffy was evaluated on four distinct environments, 10 x 10 meters in size, seeking a real isopropyl alcohol source. The trajectories of the nano quadcopters are clearly visible due to their blue lights.
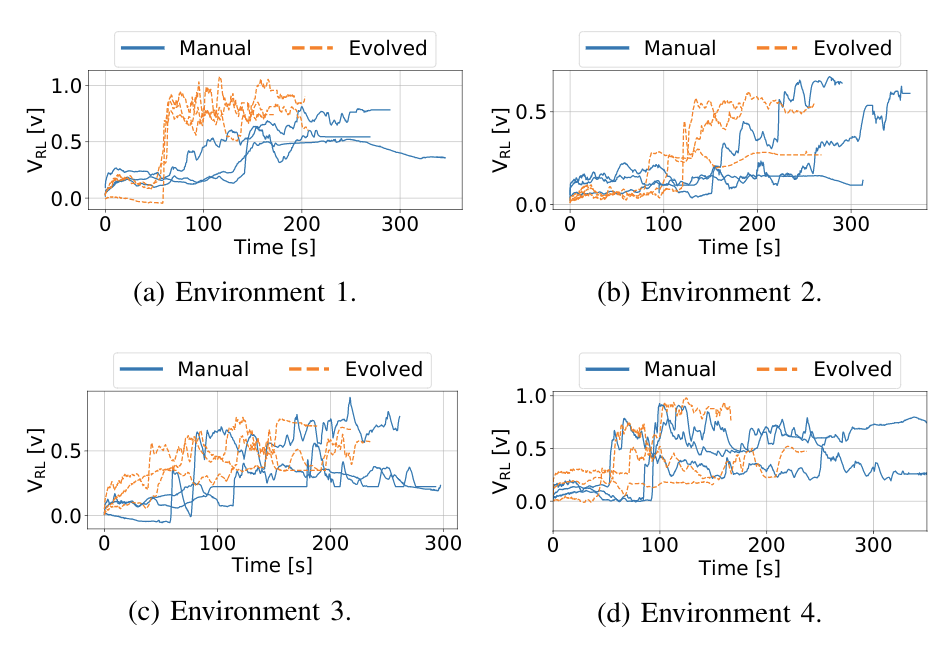
In the total of 24 runs we executed, we compared Sniffy Bug with manually selected and evolved parameters. The figure below shows that the evolved parameters are more efficient in locating the source as compared to the manual parameters.
Maximum recorded gas reading by the swarm, for each time step for each run.
This does not only show that our system can successfully locate a gas source in challenging environments, but it also demonstrates the usefulness of the simulation pipeline. The parameters that were learned in simulation yield a high-performance model, validating the environment generation, randomization, and gas modeling parts of our pipeline.
Conclusion and Discussion
With this work, we believe we have made an important step towards swarms of gas-seeking drones. The proposed solution has been shown to work in real flight tests with obstacles, and without any external systems to help in localization or communication. We believe this methodology can be extended to larger environments or even to 3 dimensions, since PSO is a robust, multi-dimensional heuristic search method. Moreover, we hope that AutoGDM will help the community to better compare gas seeking algorithms, and to more easily learn parameters or models in simulation, and deploy them in the real world.
To improve Sniffy Bug’s performance, adding more laser rangers will definitely help. When working with only four laser rangers you realize how little information they actually provide. If one of the rangers senses a low value, it is unclear if a slim pole or a massive wall is detected, adding inefficiency to the algorithm. Adding more laser rangers or using other sensor modalities like vision will help to avoid also more complex obstacles than walls and poles in a reliable manner.
Another interesting discussion can be held on the hardware required for real deployment. When working with 40 grams of maximum take-off weight, the sensors and actuators that can be selected are limited. For example, the low-power and lightweight flow deck works great but fails in low-light scenarios or with smoke. Future work exploring novel sensors for highly constrained nano robots could really help increase the Technological Readiness Level (TRL) of these systems.
Finally, this has been a really fun project to work on for us and we can’t wait to hear your thoughts on Sniffy Bug!
When there is a gas leak in a large building or at an industrial site, human firefighters currently need to go in with gas sensing instruments. Finding the gas leak may take considerable time, while they are risking their lives. Researchers from TU Delft (the Netherlands), University of Barcelona, and Harvard University have now developed the first swarm of tiny—and hence very safe—drones that can autonomously detect and localize gas sources in cluttered indoor environments.
When researching the best PC for smart warehousing and logistics, you might have a specific spec you’re trying to meet or processing capability you’re looking to achieve. You’re also likely looking for a computer that is better, faster and more reliable.
Explore the most popular deep learning architecture to perform automatic speech recognition (ASR). From recurrent neural networks to convolutional and transformers.
Basic safety needs in the paleolithic era have largely evolved with the onset of the industrial and cognitive revolutions. We interact a little less with raw materials, and interface a little more with machines.