Search “best agentic AI platform,” and you’ll drown in a sea of vendor comparisons, feature matrices, and tool catalogs. The real enemy isn’t picking the wrong vendor, though. Building your own AI solution can kill your ambitions before they even get off the ground.
In most enterprises, teams are cobbling together their own mix-and-match stack of open-source tools, cloud services, and point solutions. Marketing has its chatbot builder, IT is experimenting with some hyperscaler’s agent framework, and data science is spinning up vector databases on whatever cloud credits they can scrounge up.
That’s shadow AI in a nutshell, with governance gaps that no compliance audit can easily untangle.
Everyone loves talking about building agents. That’s the easy part.
The part nobody wants to admit is that most of those agents will never make it out of a demo. Siloed teams don’t have a unified way to run them, govern them, or keep them from stepping on each other’s toes.
Enterprises don’t need more pet projects. They need a governed agent workforce: AI that works across teams, clouds, and business systems without falling apart at the slightest disruption.
Key takeaways
- Fragmented AI stacks slow enterprises down. Tool sprawl and shadow AI make agents brittle, hard to govern, and difficult to scale.
- End-to-end means unifying build, deploy, and govern. A single control plane eliminates handoff failures and gets agents into production faster.
- The blank-slate problem is real. Reference architectures, agent templates, and pre-built starter patterns help teams deliver value quickly instead of rebuilding from zero.
- Openness only works with governance. Supporting any tool or model means nothing without consistent security, lineage, and policy controls traveling with every agent.
- Structural partnerships accelerate enterprise readiness. Co-engineered integrations with infrastructure and application providers give teams production-grade agentic workflows without months of manual setup.
Why fragmentation is the real enemy to enterprise AI
Walk into any enterprise today and ask how many different AI tools are running across the organization. The honest answer is usually, “We have no idea.” That’s not incompetence. It’s the natural result of teams trying to perform their jobs as quickly and accurately as possible.
Shadow AI, duplicated efforts, and niche point solutions are all part of the problem.
This leads to two common failure modes that kill more AI initiatives than any vendor selection mistake ever could:
- Tool sprawl and “LEGO block” architectures: Somewhere along the way, “shipping an AI use case” turned into a scavenger hunt. Teams are stitching together 10–14 tools, like vector stores, orchestrators, log aggregators, and governance band-aids, just to get a single agent out the door. Each API and integration point is just another output away from failure, security exposure, or a performance meltdown. A project that should take weeks dissolves into a multi-month integration saga nobody signed up for.
- Siloed, cloud-specific stacks that don’t interoperate: Speed over flexibility is how most teams end up locked into a hyperscaler ecosystem. It’s smooth sailing until you try to plug into a system you don’t control, deploy in a regulated environment, or collaborate with a partner on a different platform. Then you end up choosing between two painful paths: move fast and lose control, or keep control and fall behind.
Any serious conversation about agentic AI platforms has to start with eliminating this fragmentation. Everything else is secondary.
What “end-to-end” actually means for agentic AI
“End-to-end” gets thrown around by nearly every vendor in the space. But in an enterprise context, it has a specific meaning that most tool collections fail to meet.
Real end-to-end coverage spans three critical stages, each with specific requirements that fragmented tool chains struggle to address:
- Build: Teams shouldn’t start from scratch every time they need an agent. That means reference architectures, reusable patterns, and starter kits aligned with real enterprise workflows.
- Operate: Single agents are proofs of concept. Production systems need dozens or hundreds of agents coordinating across systems, sharing memory, handling errors gracefully, and optimizing for cost and latency. That requires sophisticated orchestration, continuous evaluation, and the ability to adjust behavior based on real-world performance.
- Govern: Lineage, access control, policy enforcement, and auditability are needed the moment agents start making decisions and interacting with real business systems. Governance isn’t a checklist. It’s the operating system.
Stitching together separate tools for each stage creates drift, governance gaps, and extended time-to-production. Teams spend more time on integration than innovation, and by the time they’re ready to deploy, the business requirements have already moved on.
From building agents to running an agent workforce
Most platform conversations go off the rails by focusing on building individual agents instead of running a workforce of agents at scale.
That shift changes everything. Running a workforce means you need:
- Shared memory so agents can learn from each other’s interactions
- Consistent reasoning behavior so agents don’t make contradictory decisions
- Centralized policies that update across the entire workforce without redeploying everything
- Unified observability so you can debug multi-agent workflows without chasing logs across a dozen different systems
Most importantly, you need agent lifecycle management at the workforce level. New agents should automatically inherit organizational knowledge and policies. Updates should roll out consistently across related agents to prevent coordination failures.
Building individual agents is a development problem. Running an agent workforce is an operational challenge that requires platform-level thinking. The two require fundamentally different approaches.
How to solve the blank slate problem
The industry loves to offer infinite flexibility, as if giving teams a blank canvas is a gift. It isn’t. Without a starting point, teams spend months making foundational decisions that have already been solved elsewhere, time-to-value slipping straight into the next fiscal year.
What teams actually need is momentum.
That means starting with fully formed agent templates and reference architectures shaped around real enterprise workflows. Not hypotheticals or academic examples, but real document pipelines, supply chain agents, and customer service automations with the hard edge cases already accounted for.
The best templates aren’t code samples polished for a conference demo. They’re production-ready patterns co-engineered with the infrastructure and application providers enterprises already run on, covering security, governance, error handling, and integrations from the start.
The difference in outcome is significant. Teams that start from proven patterns ship in weeks. Teams that start from scratch are still building foundations when the business requirements change.
When the question becomes “What has AI actually delivered?”, blank slates won’t have an answer. Proven patterns will.
Why a unified, vendor-neutral control plane matters
Enterprise AI teams face a structural tension: the tools and infrastructure they need to move fast are rarely the same ones IT needs to maintain control, security, and compliance.
That tension doesn’t resolve itself. It has to be designed around.
A unified control plane gives every team — AI developers, IT, security, and business owners — a single operating environment, without forcing them to abandon the tools they already use. Models, databases, frameworks, and deployment targets remain flexible. Governance, lineage, and policy enforcement travel with every agent, regardless of where it runs.
This matters most at the edges: sovereign cloud deployments, regulated industries, air-gapped environments, and hybrid infrastructure. These are precisely the situations where tool-by-tool governance breaks down, and where a single control plane proves its value.
Vendor neutrality isn’t a feature. It’s the prerequisite for enterprise AI that can scale beyond a single team, a single cloud, or a single use case. As AI becomes more deeply embedded in enterprise systems, the ability to govern across any environment becomes the only sustainable path forward.
What deep infrastructure partnerships actually enable
Not all technology partnerships are equal. Logo-level integrations add a name to a slide. Structural, co-engineered partnerships shape platform architecture and change what’s actually possible for enterprise teams.
The practical difference shows up in time and complexity. When infrastructure capabilities like inference microservices, reasoning models, guardrail frameworks, GPU optimizations, and decision engines are co-engineered into a platform rather than bolted on, teams get access to them without months of manual setup, validation, and tuning.
That acceleration unlocks use cases that require combining reasoning, simulation, and optimization together:
- Supply chain routing that considers real-time constraints and optimizes across multiple objectives
- Digital twins that simulate complex scenarios and recommend actions
- Clinical workflows that reason through patient data while maintaining strict privacy controls
Operational reliability matters as much as technical depth. Production-grade architectures need to be validated across cloud, on-premises, sovereign, and air-gapped environments. Co-engineered integrations carry that validation with them. Teams inherit it rather than having to build it themselves.
The technical and organizational impact of unifying build, deploy, and govern
The technical case for unifying build, deploy, and govern is well understood. The organizational impact is where the real breakthroughs happen.
Assumptions stay intact through every handoff. The entire multi-agent workflow is traceable in one place, so when something misbehaves, teams can diagnose and fix it without hunting through scattered logs across disconnected systems.
Organizationally, a unified platform creates shared clarity. AI teams, IT, security, compliance, and business owners operate from the same source of truth. Governance stops being a bureaucratic burden passed between teams and becomes a shared operating language built into the platform itself.
That shift has a direct effect on shadow AI. When the official platform is easier to use than rogue alternatives, teams stop building around it. Fragmentation recedes, not because it was mandated away, but because the better path became obvious.
What multi-agent orchestration actually requires
Single-agent demos make AI look straightforward. Multi-agent systems reveal the real complexity.
The moment you move beyond one agent, the gaps in most toolchains become obvious. Shared memory, consistent governance, workflow supervision, and unified debugging aren’t optional features. They’re the foundation that keeps multi-agent systems from becoming unmanageable.
Effective multi-agent orchestration requires several capabilities working together: dependency management and retries to handle failures gracefully, dynamic workload optimization to balance cost and performance across agents, and consistent safety and reasoning guardrails applied uniformly across the entire system.
Without these, multi-agent workflows create more operational risk than they eliminate. With them, a coordinated agent workforce becomes possible: one where agents share context, operate under consistent policies, and escalate appropriately when they reach the boundaries of their autonomy.
The workforce analogy holds here. A functioning workforce, human or AI, needs coordination, shared knowledge, guardrails, and clear escalation paths. Orchestration is what makes that possible at scale.
At some point, the architecture discussion has to give way to outcomes. Here’s what enterprises consistently see when the AI lifecycle is properly unified:
- Production timelines collapse. Teams that used to spend 12–18 months on build cycles ship in weeks when they’re not rebuilding foundational infrastructure from scratch. The difference isn’t effort — it’s starting position.
- Inference costs stay manageable. Multi-agent systems can burn through budgets faster than they generate insights. Real-time workload optimization and GPU-aware scheduling keep performance high and costs predictable.
- Resilience increases. When orchestration, retries, and error handling are handled at the platform level, a single failure can’t topple an entire workflow. Issues surface before they become customer-visible outages.
- Governance risk shrinks. Lineage, access control, and policy enforcement remain consistent across all agents. No blind spots, no mystery systems, no surprises in production. Audits become routine rather than disruptive.
These outcomes share a common cause: When the full lifecycle is unified, teams spend their energy on problems that matter to the business instead of problems created by their own infrastructure.
There’s a point where collecting more tools stops being a strategy and starts being a liability. Every addition creates another integration to maintain, another governance gap to close, and another point of failure to debug at the worst possible moment.
The enterprises making real progress with agentic AI aren’t the ones with the longest tool lists. They’re the ones that stopped stitching and started operating — with platforms that handle coordination, governance, and lifecycle management as core functions rather than afterthoughts.
An agent workforce needs to behave like a real team: coordinated, reliable, scalable, and aligned with business outcomes. That doesn’t happen by accident. It happens by design.
Ready to move from experiments to production-grade impact? See how the Agent Workforce Platform works.
FAQs
An end-to-end agentic AI platform unifies the entire lifecycle, building agents, orchestrating multi-agent workflows, deploying them across environments, and governing them with consistent policies. Most vendors offer a collection of tools that must be stitched together manually.
A true end-to-end platform provides a single control plane with shared lineage, observability, and governance, so teams can move from prototype to production without rebuilding everything.
Why is fragmentation such a major problem for enterprises?
When teams use different tools, LLMs, and workflows, enterprises end up with brittle agents, inconsistent policies, duplicated infrastructure, and security blind spots. Most production failures happen at the handoff between AI, IT, and DevOps.
Fragmentation also fuels shadow AI, where teams build unmanaged agents without oversight. A unified platform removes these gaps by giving all stakeholders a shared environment and the governance guardrails they need.
Hyperscalers and open-source stacks provide components like vector stores, LLMs, gateways, observability tools, but customers must assemble, integrate, and secure them themselves. DataRobot provides a single platform that unifies these pieces, supports any model or framework, and embeds governance from day one.
The difference is agent lifecycle management, multi-agent orchestration, and vendor-neutral governance that scales across the business.
How does the NVIDIA partnership improve enterprise readiness?
DataRobot is co-engineered with NVIDIA, giving customers day-zero access to NVIDIA NIMs, NeMo Guardrails, decision optimizers like cuOpt, and industry-specific SDKs without manual setup.
These integrations turn advanced models and infrastructure into usable, production-grade agentic patterns that would otherwise require months of assembly and validation.
Why does governance need to be embedded from the start?
Governance added at the end creates gaps in lineage, security, access control, and auditability, especially when agents move between tools. DataRobot embeds governance into every stage of the lifecycle: versioning, approvals, policy enforcement, monitoring, and runtime controls are applied automatically. This prevents drift, ensures reproducibility, and gives AI leaders visibility across all agents and workloads, even in highly regulated environments.
How does DataRobot support multi-agent systems at scale?
Multi-agent systems break easily when orchestrators, tools, and safety frameworks aren’t aligned. DataRobot handles coordination, retries, shared memory, policy consistency, and debugging across agents through Covalent orchestration, syftr optimization, and NVIDIA guardrails. Instead of running isolated agent demos, enterprises can run a governed, scalable workforce of agents that collaborate reliably across systems.
The post Best agentic AI platforms: Why unified platforms win appeared first on DataRobot.
 MIT researchers utilized specially trained generative AI models to create a system that can complete the shape of hidden 3D objects, like the ones pictured. Credit: Courtesy of the researchers.
MIT researchers utilized specially trained generative AI models to create a system that can complete the shape of hidden 3D objects, like the ones pictured. Credit: Courtesy of the researchers. The team also built an expanded system that fully reconstructs entire indoor scenes by leveraging wireless signal reflections off humans moving in a room. Credit: Courtesy of the researchers.
The team also built an expanded system that fully reconstructs entire indoor scenes by leveraging wireless signal reflections off humans moving in a room. Credit: Courtesy of the researchers.
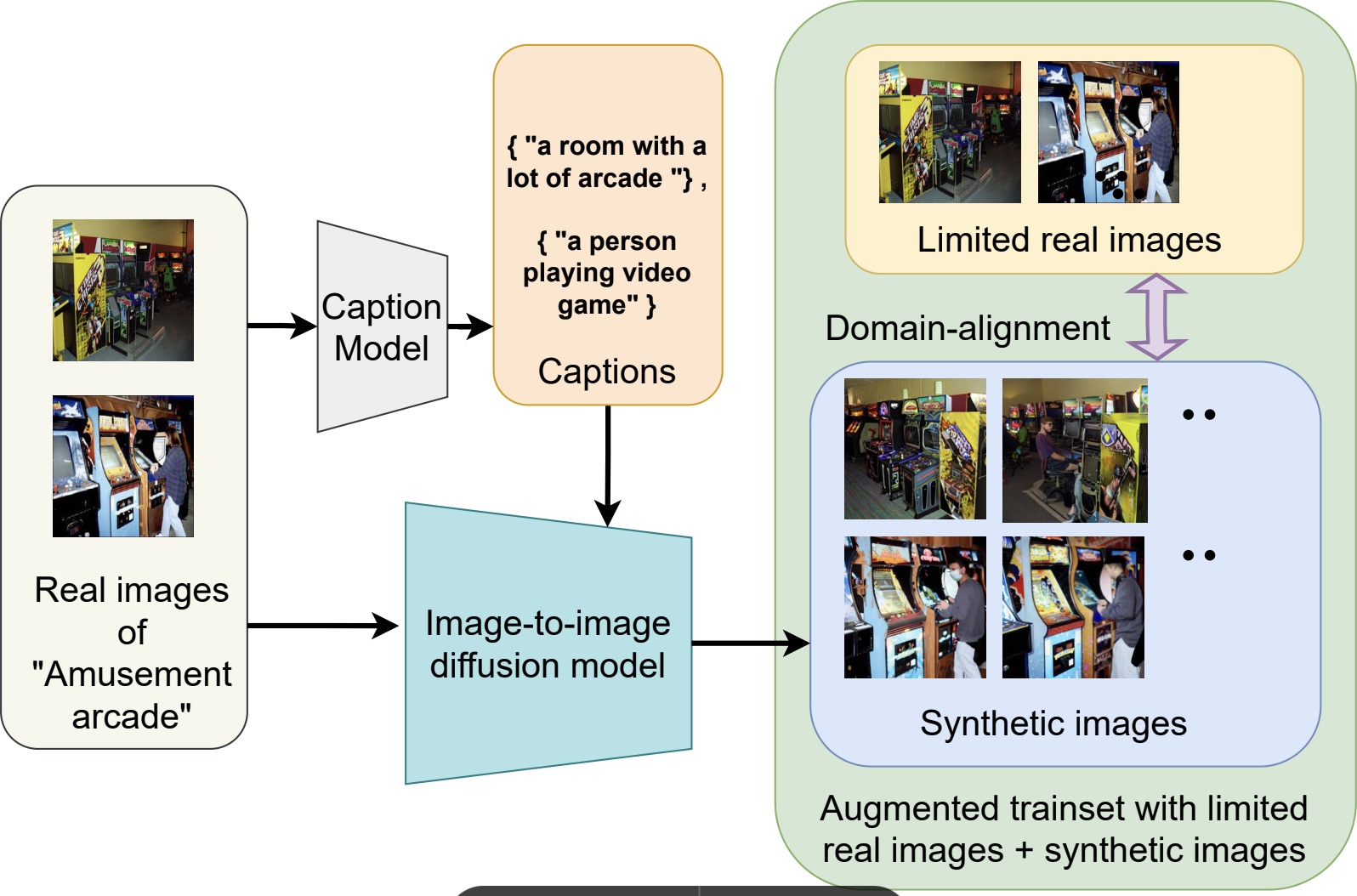 Overview of Cap2Aug.
Overview of Cap2Aug.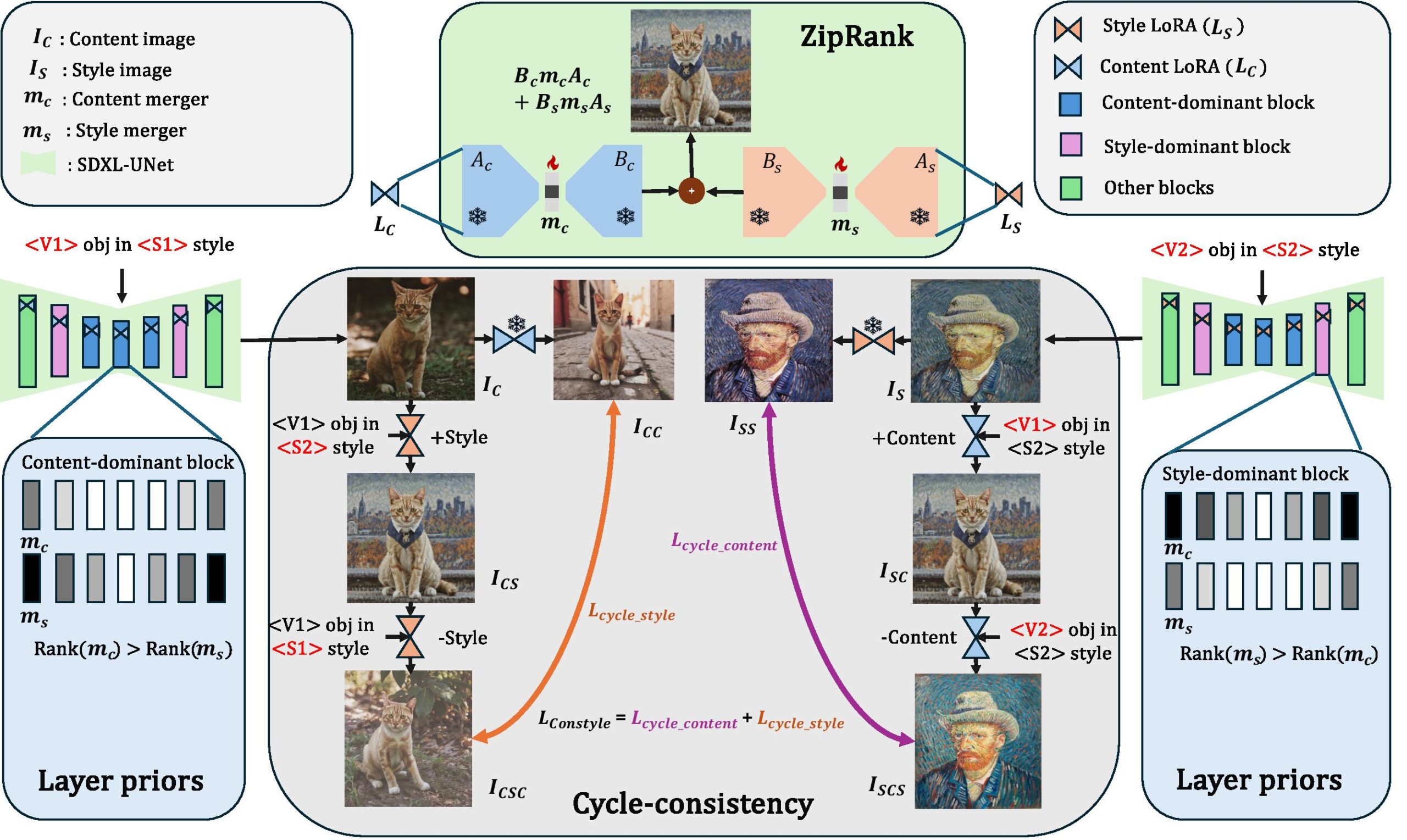 Overview of DuoLoRA.
Overview of DuoLoRA.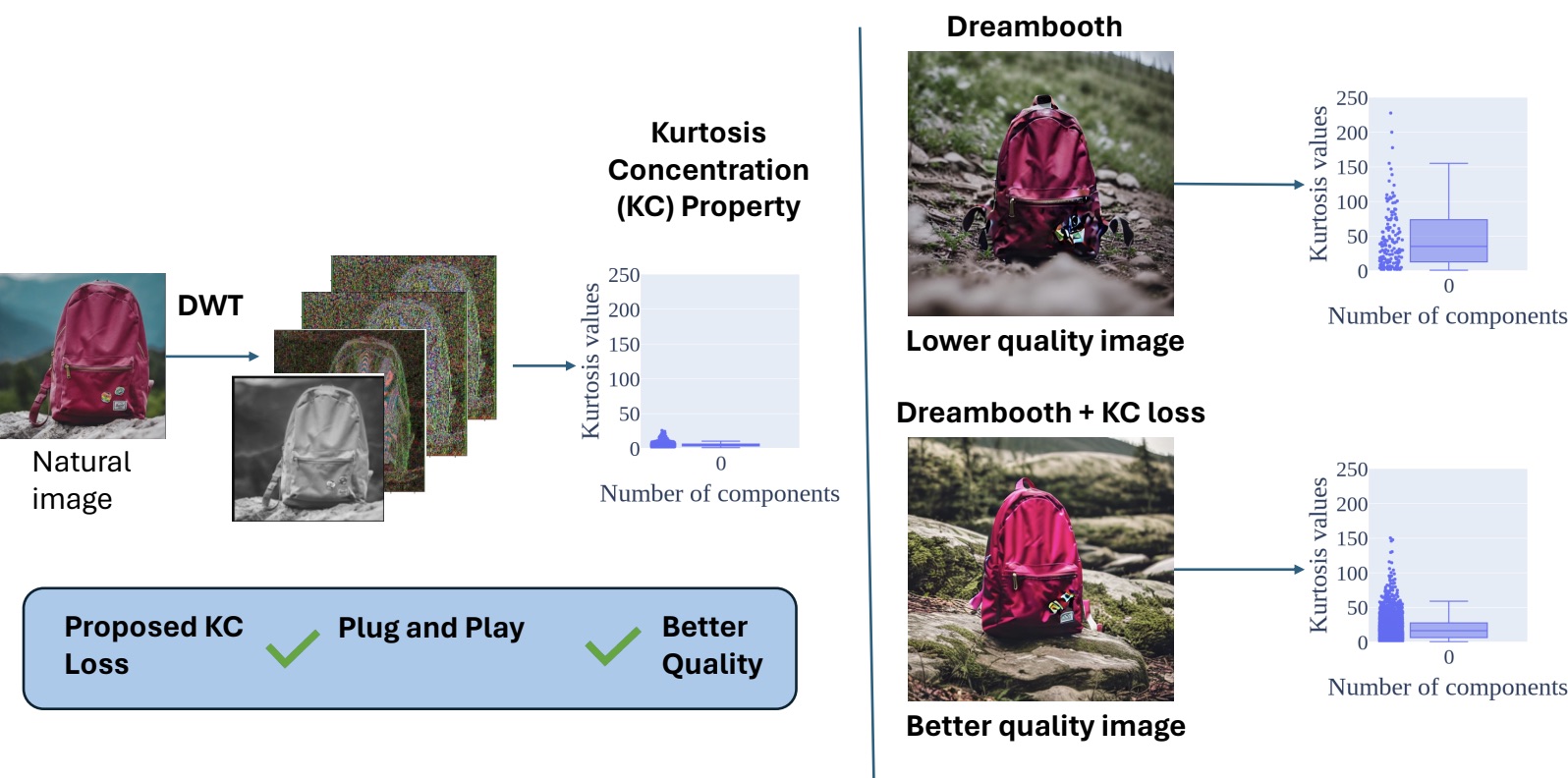 Overview of DiffNat.
Overview of DiffNat.